Download to read offline

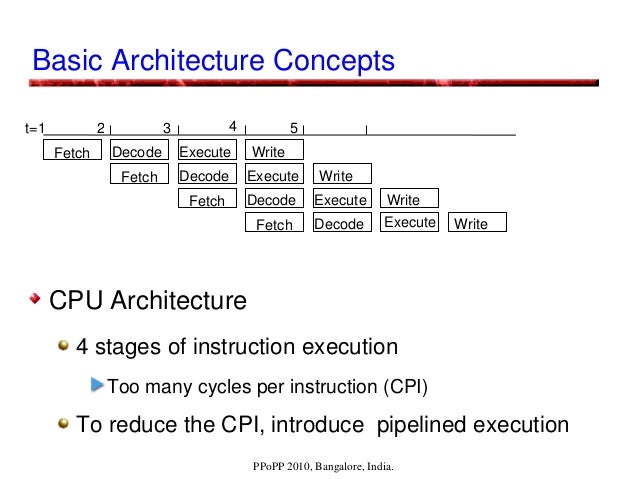
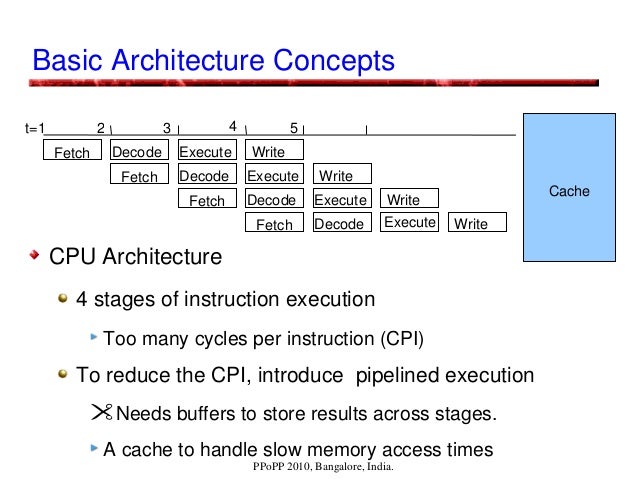
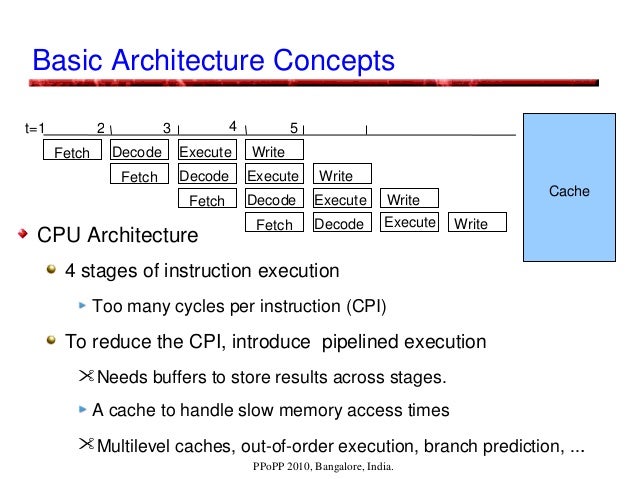












Computer architectures are facing issues: Memory latencies are far higher. Benefits from instruction level parallelism (ILP) is reducing. With increasing clock rates, power consumption is increasing. Increasing complexity with multi-stage pipelines, intermediate buffers, multi-level caches, out-of-order execution, branch prediction, ... GPUs are parallel computer architectures that are good at some tasks, not so good at others. Running routines with high arithmetic intensity with overlapped memory access is the preferred approach. They may be unsuitable for irregular algorithms, where it is difficult to get high efficiency due to the high latency of accesses. They are less versatile compared to CPUs, using SIMD parallelism, and are dense compute-wise (per currency). NVIDIA's CUDA programming model enables GPUs to be used for general-purpose computing, and hence the term GPGPU. GPU Architectural, Programming, and Performance Models presentation at PPoPP, 2010, Bangalore, India. By Prof. Kishore Kothapalli with Prof. P. J. Narayanan and Suryakant Patidar. https://gist.github.com/wolfram77/43a6660121eef45b78c10d4e652dad6c



























