Downloaded 267 times



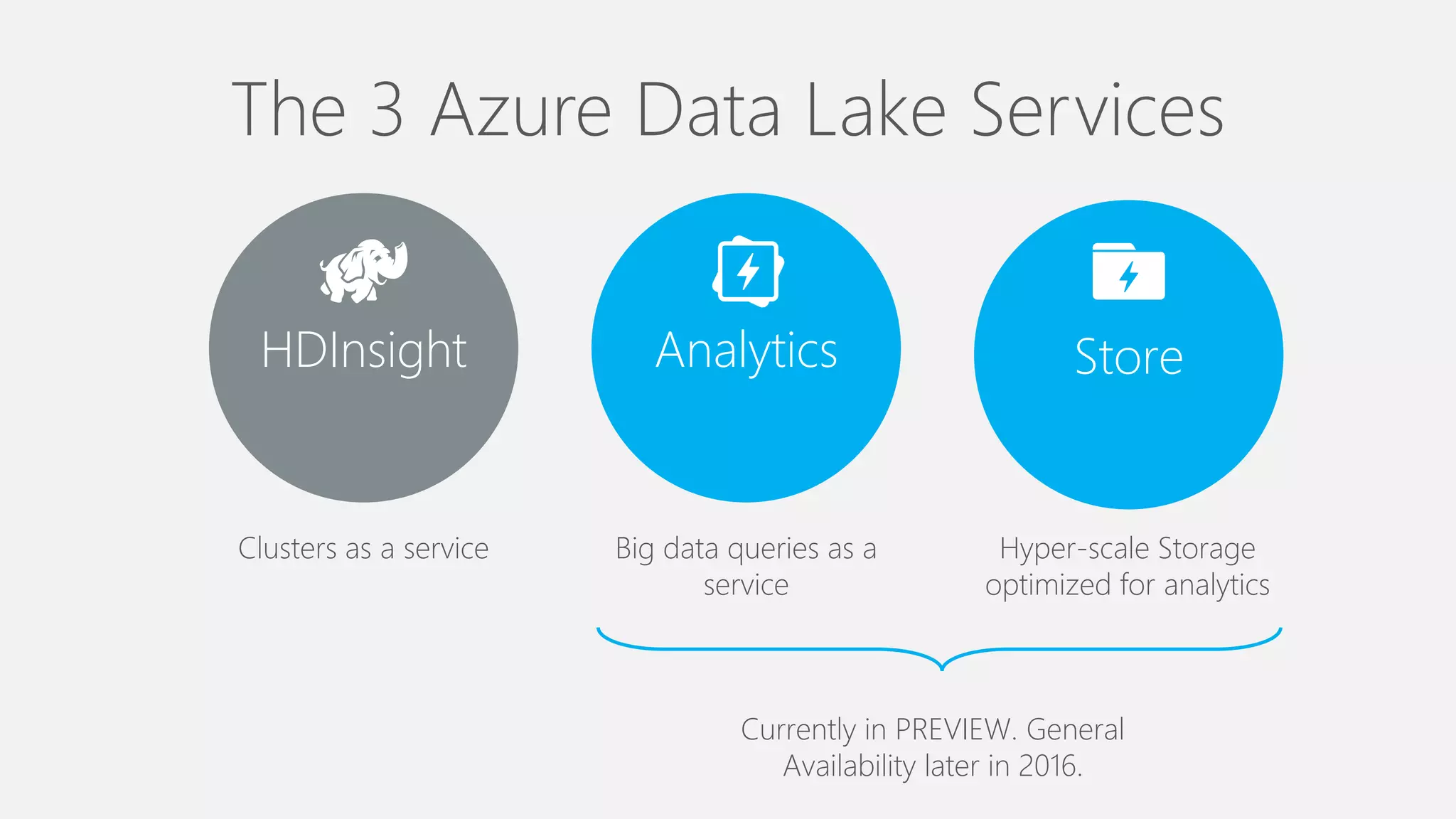



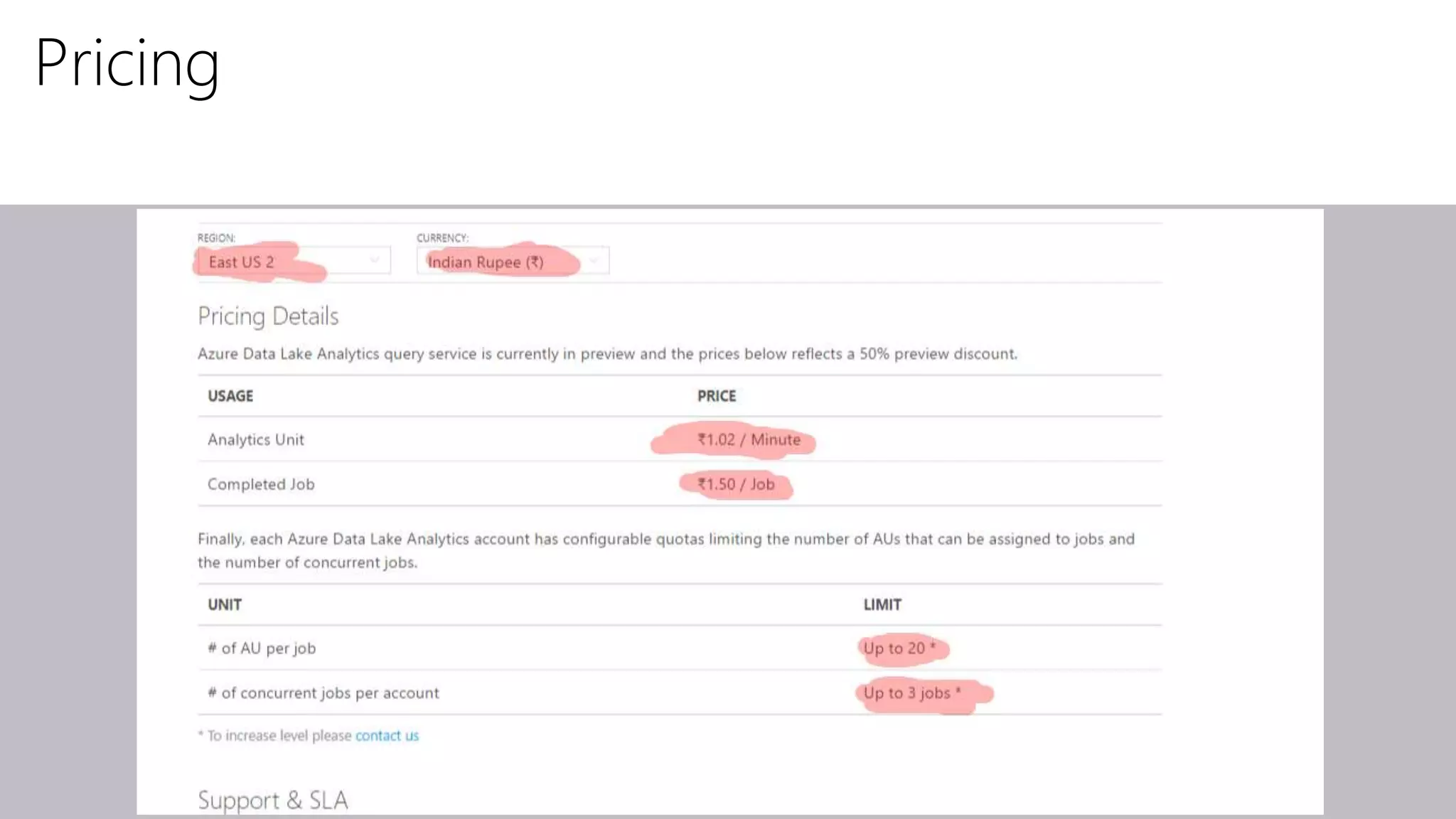


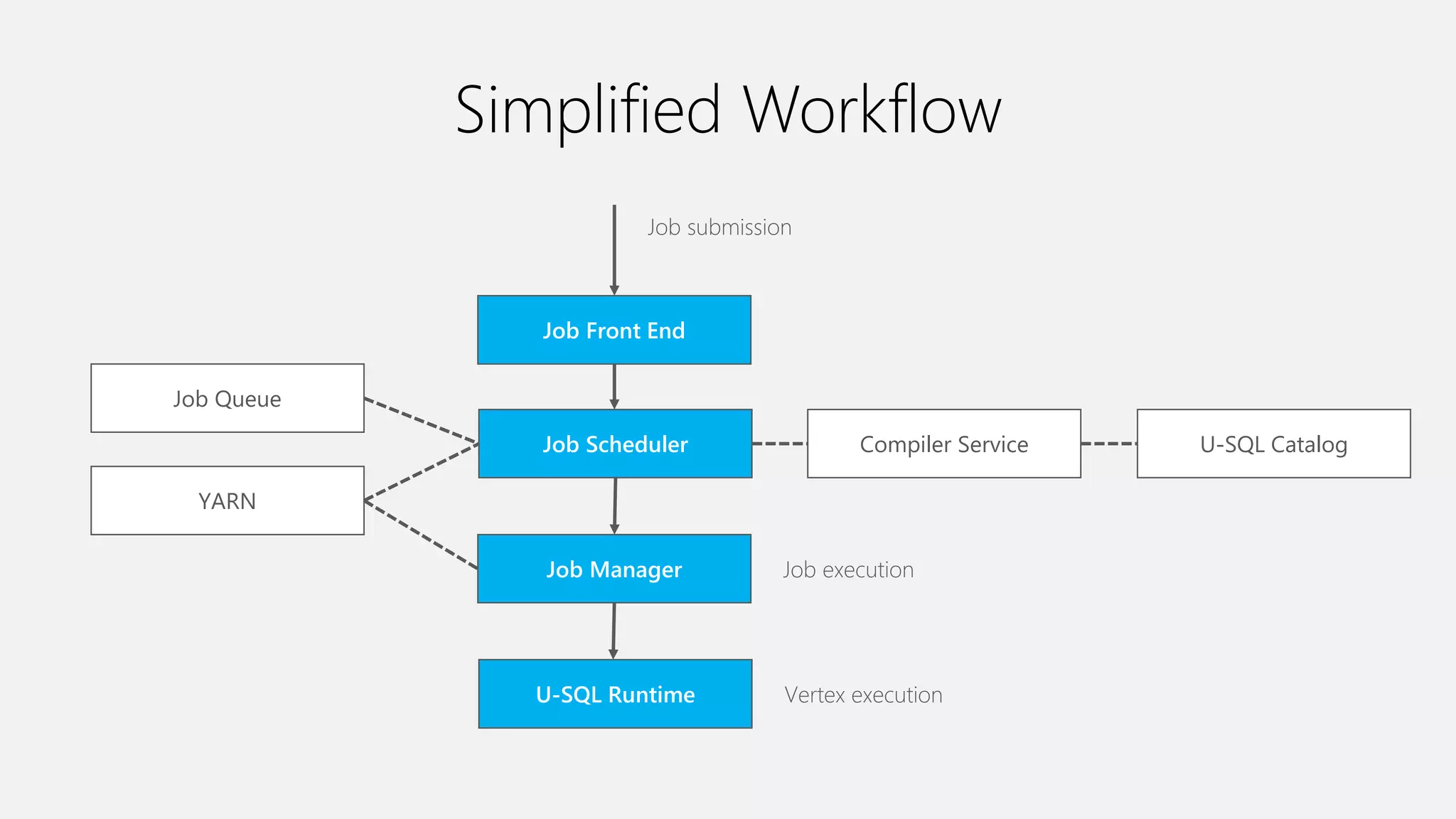


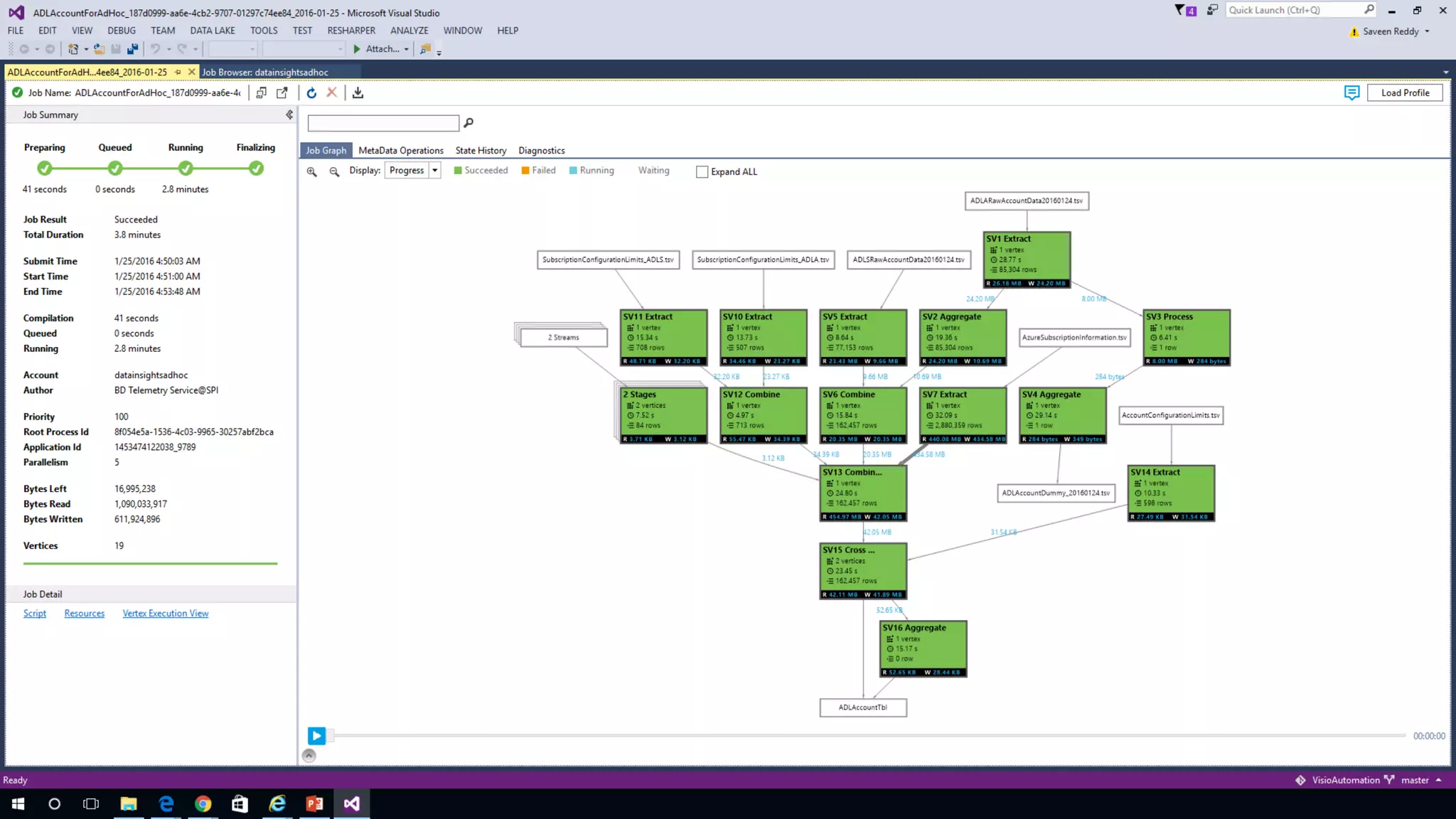
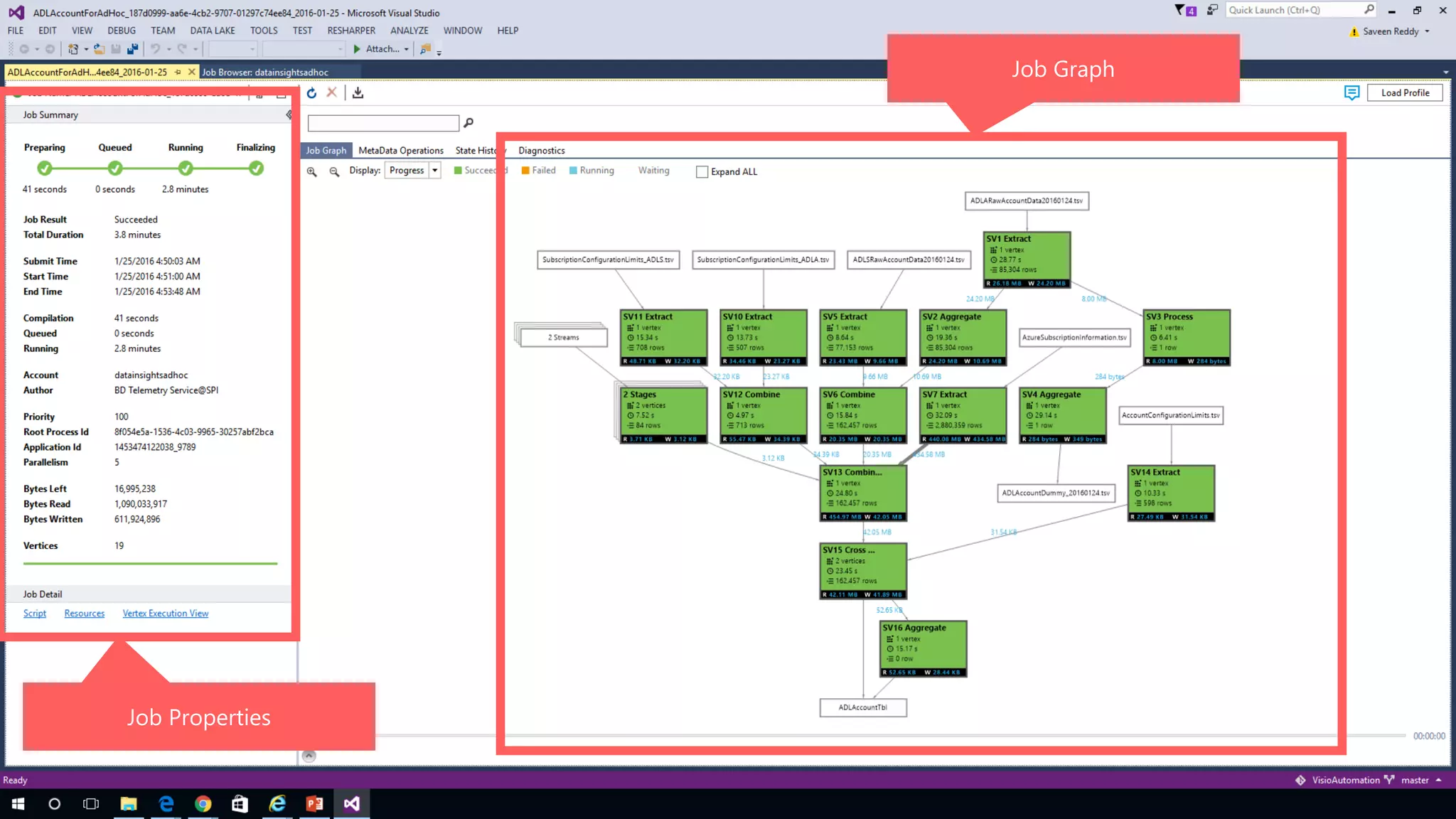

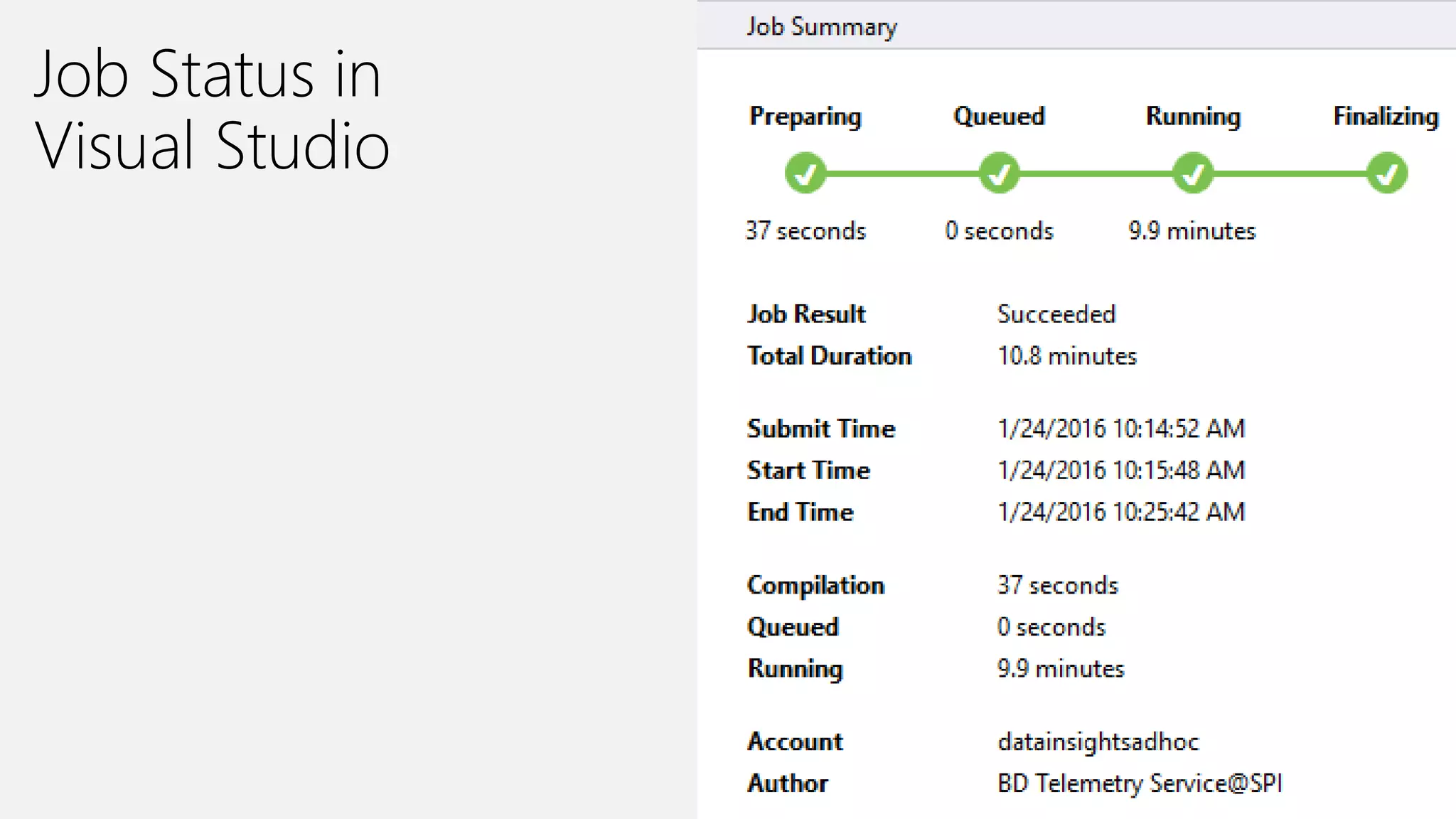
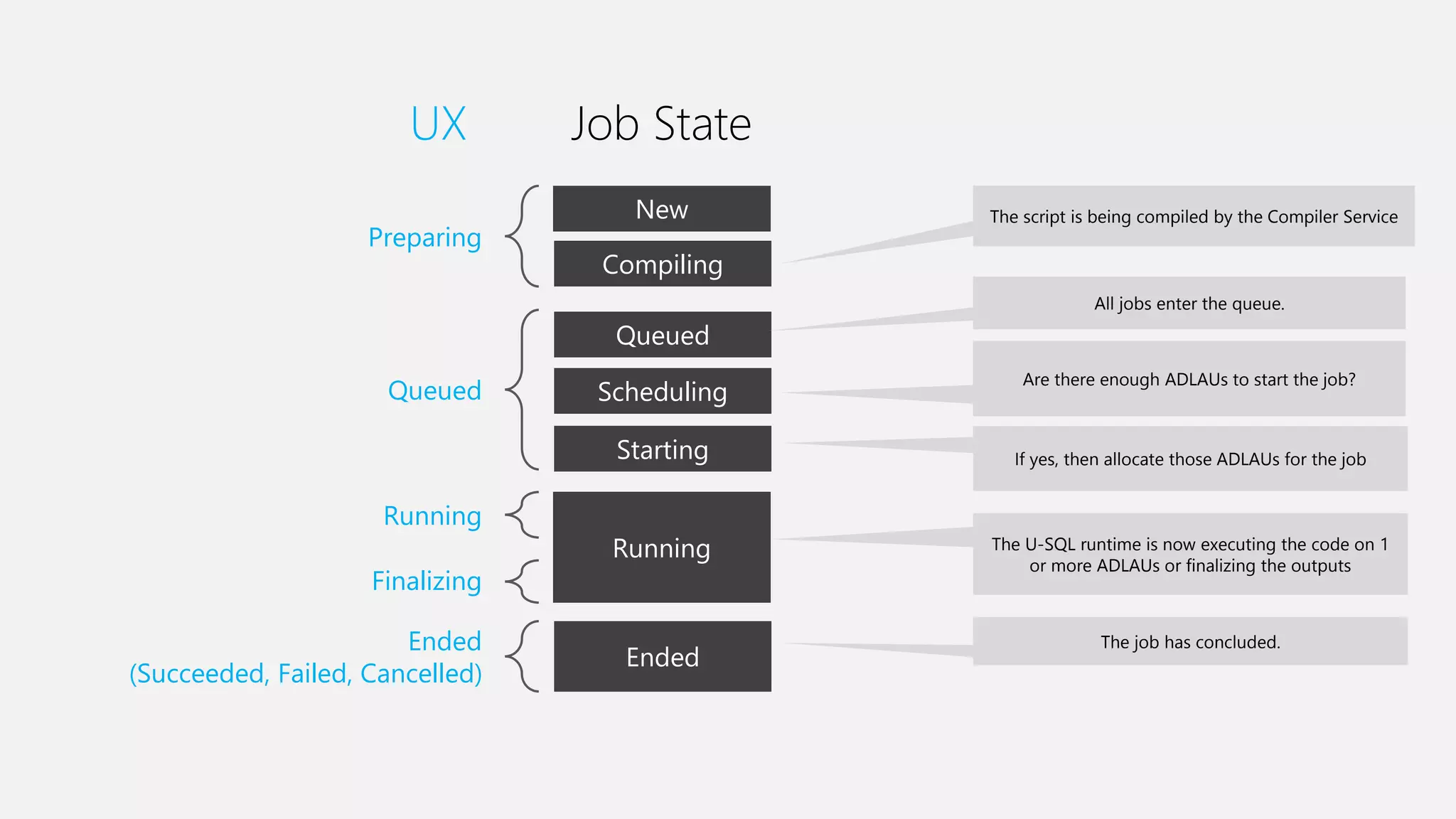

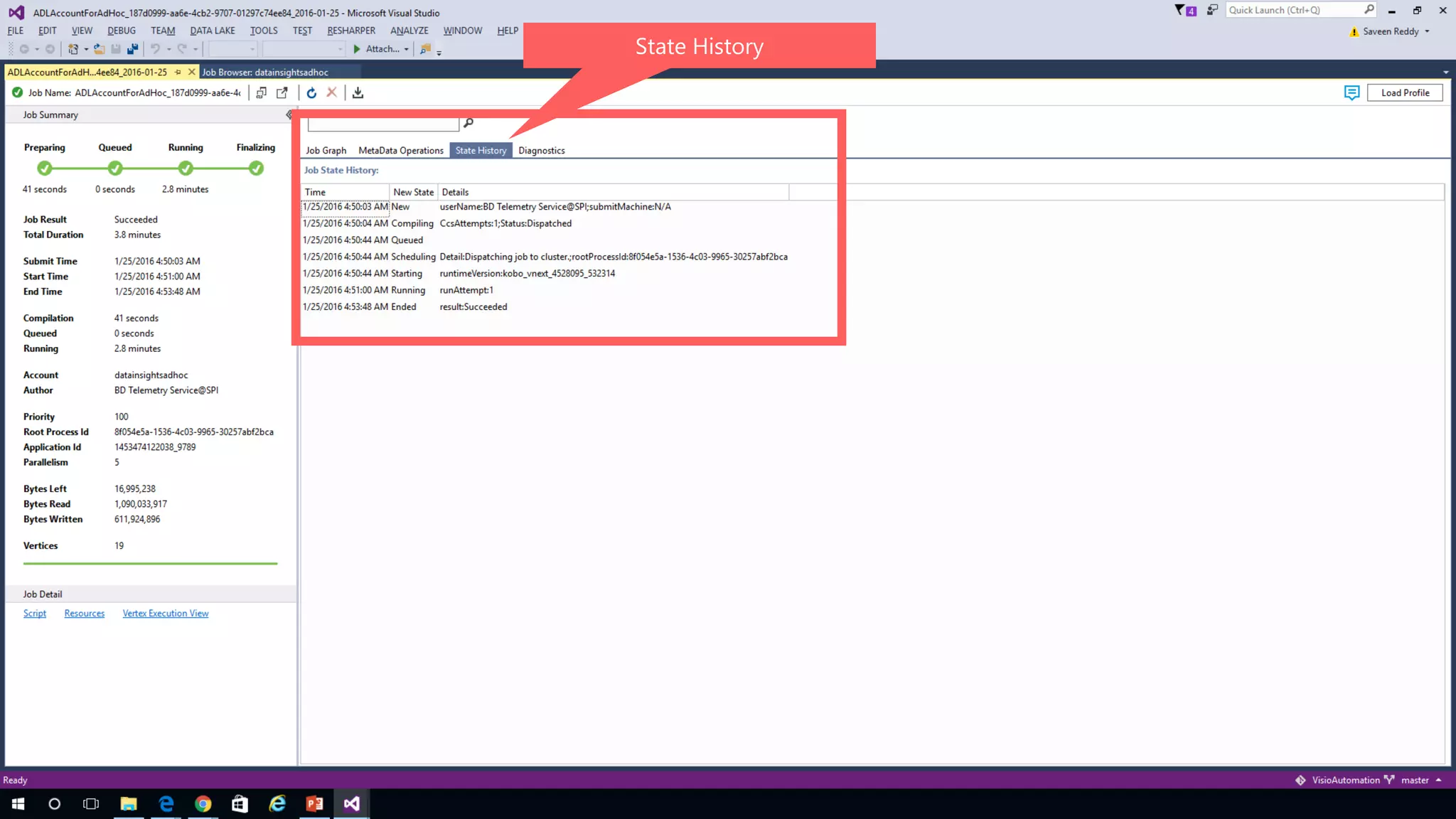
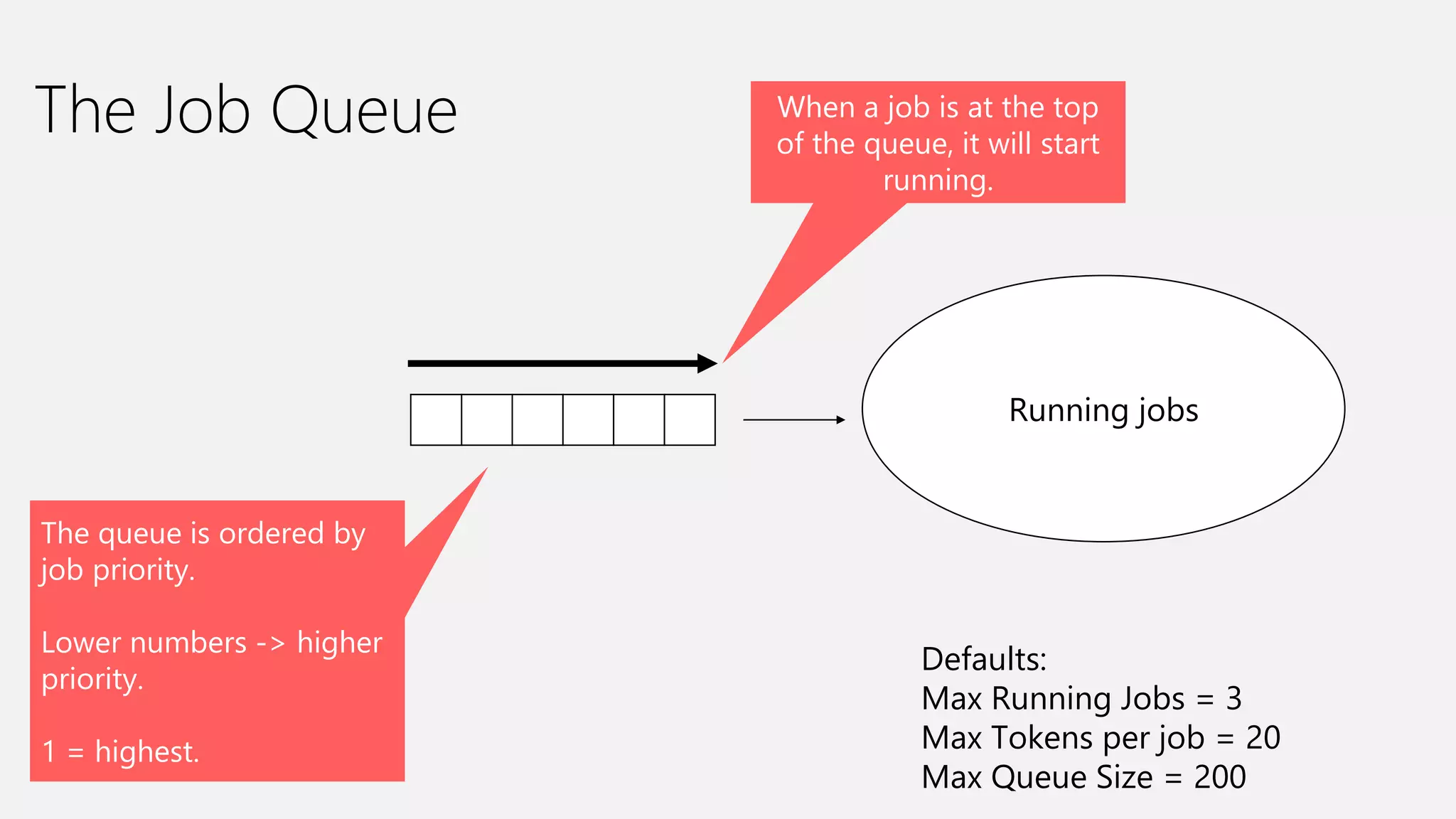
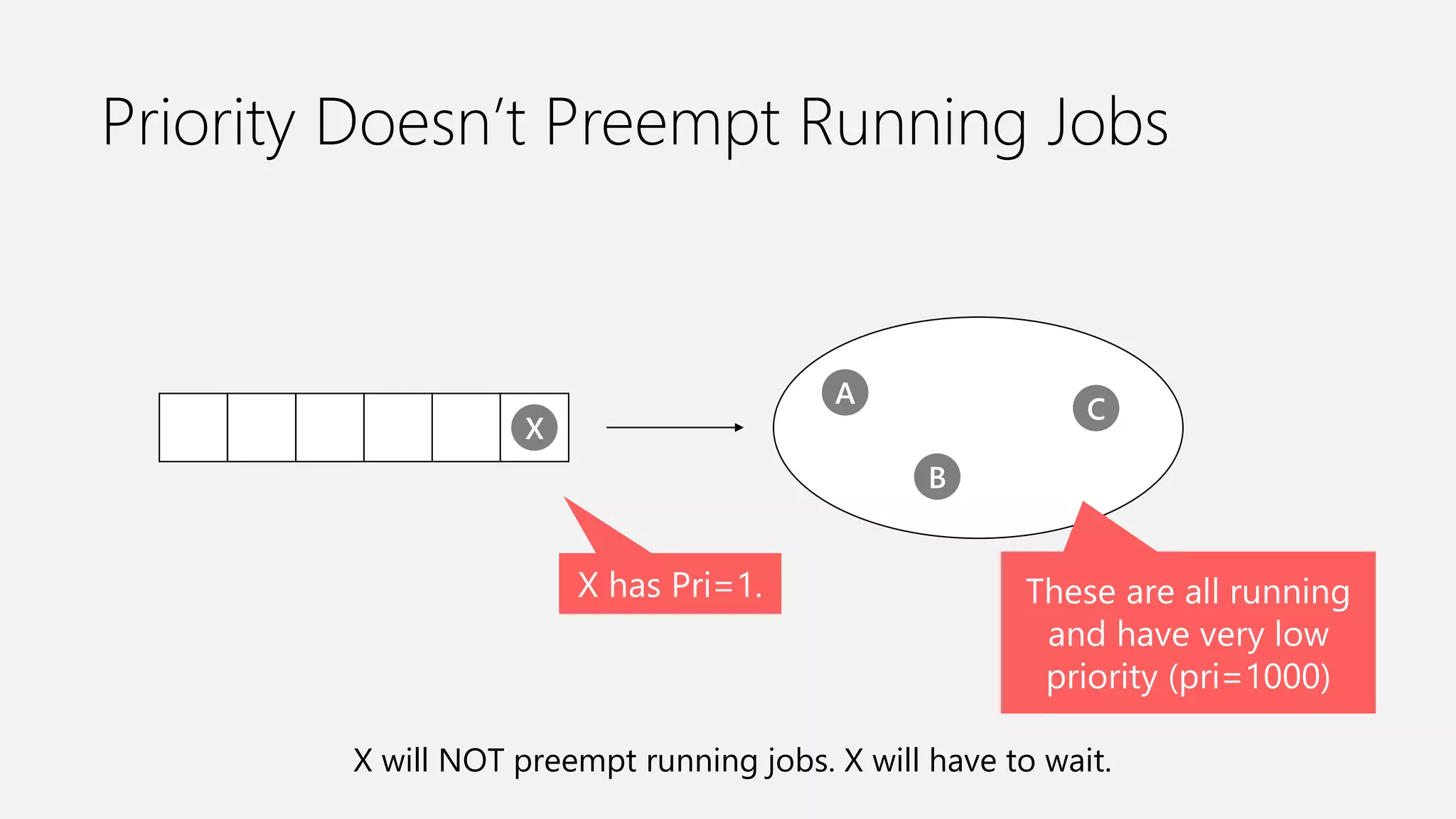

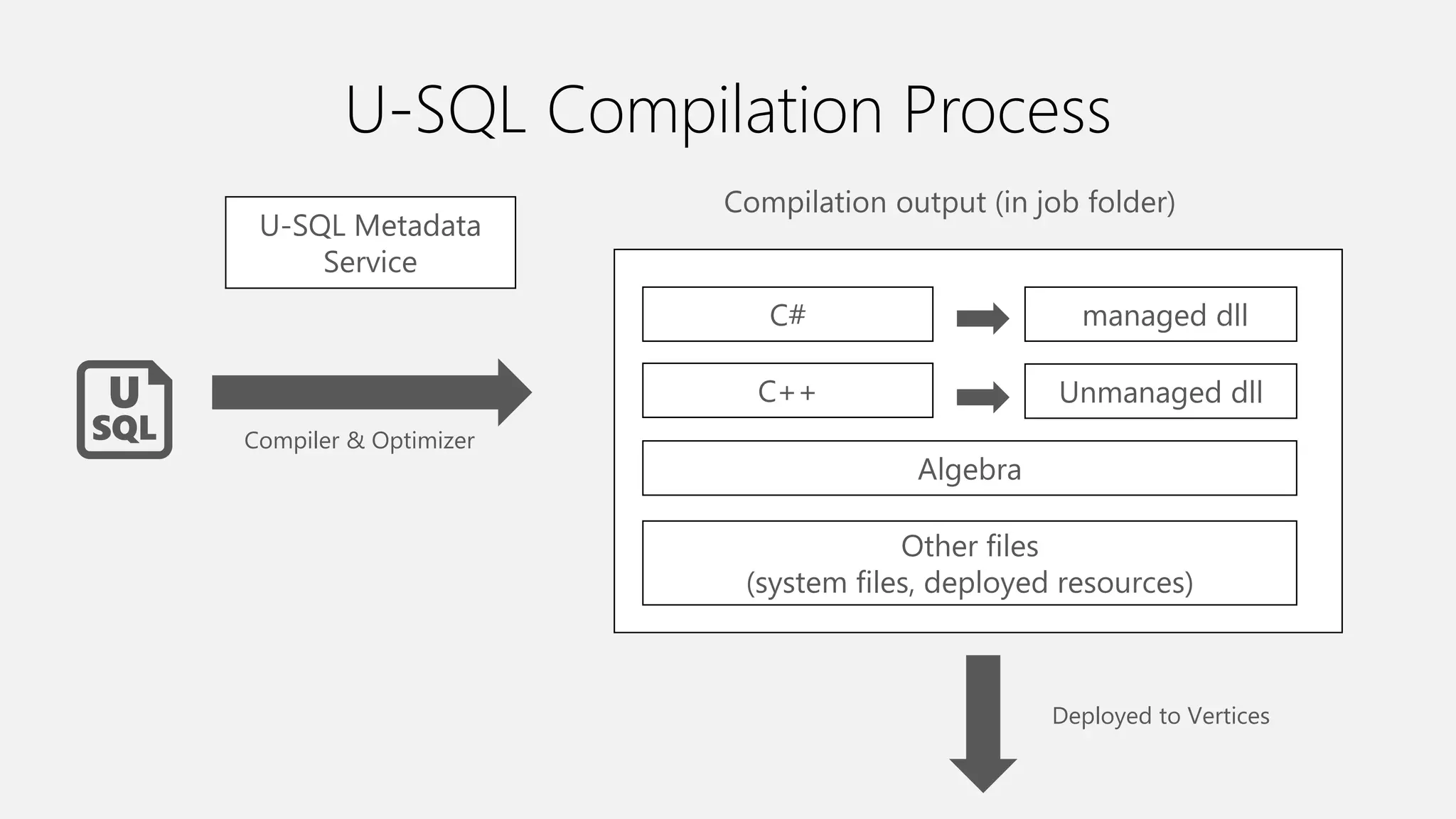

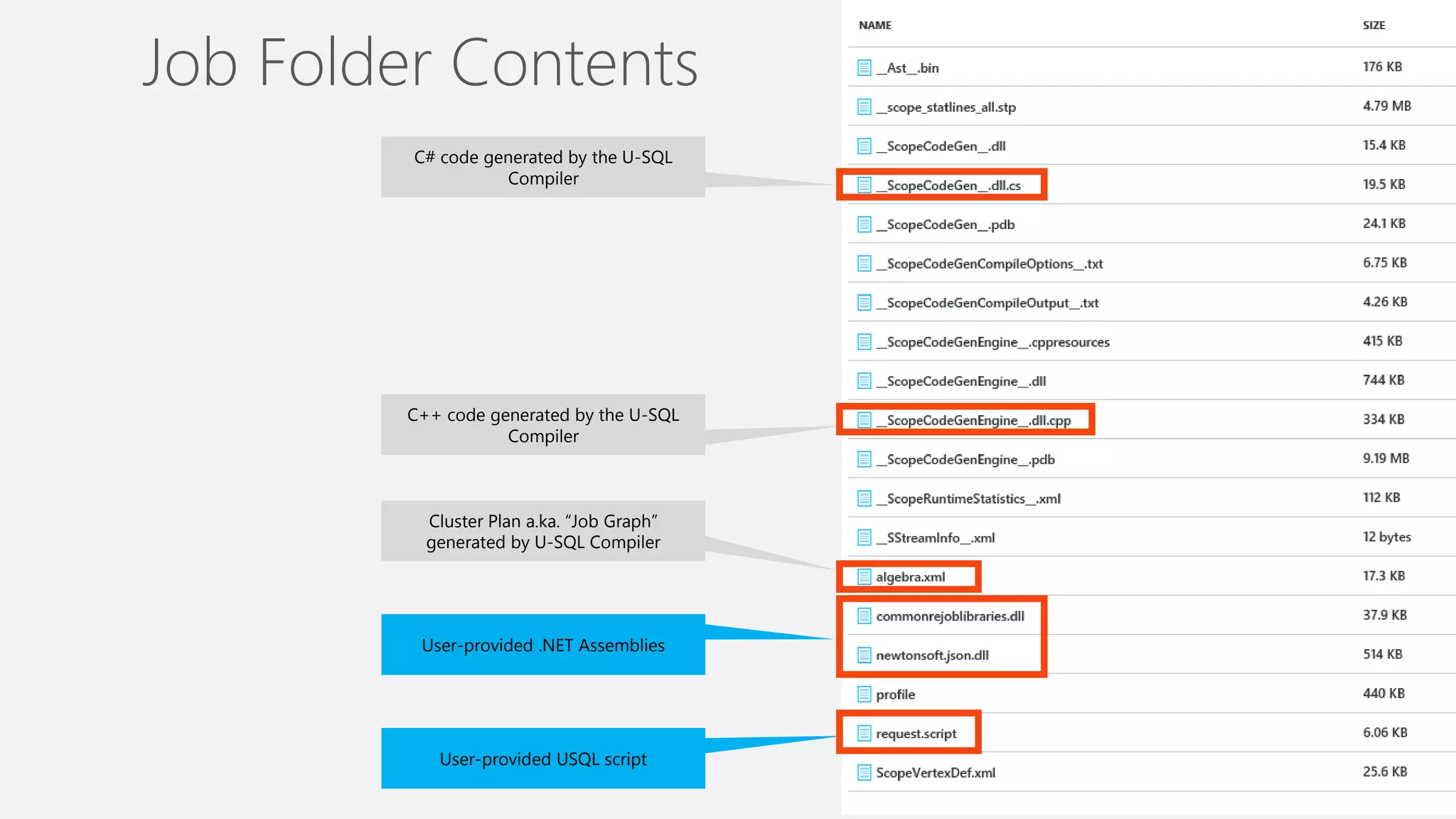
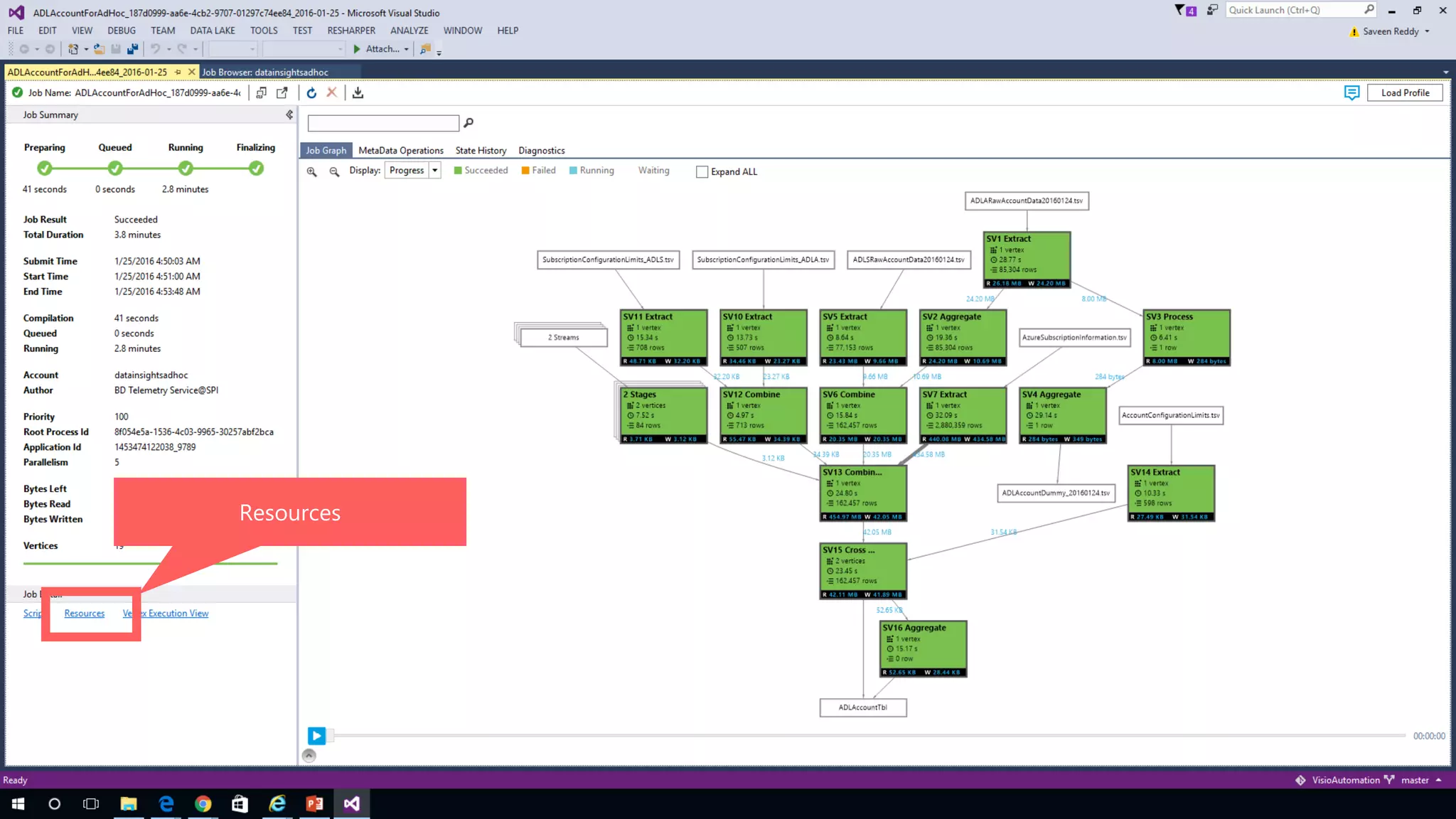
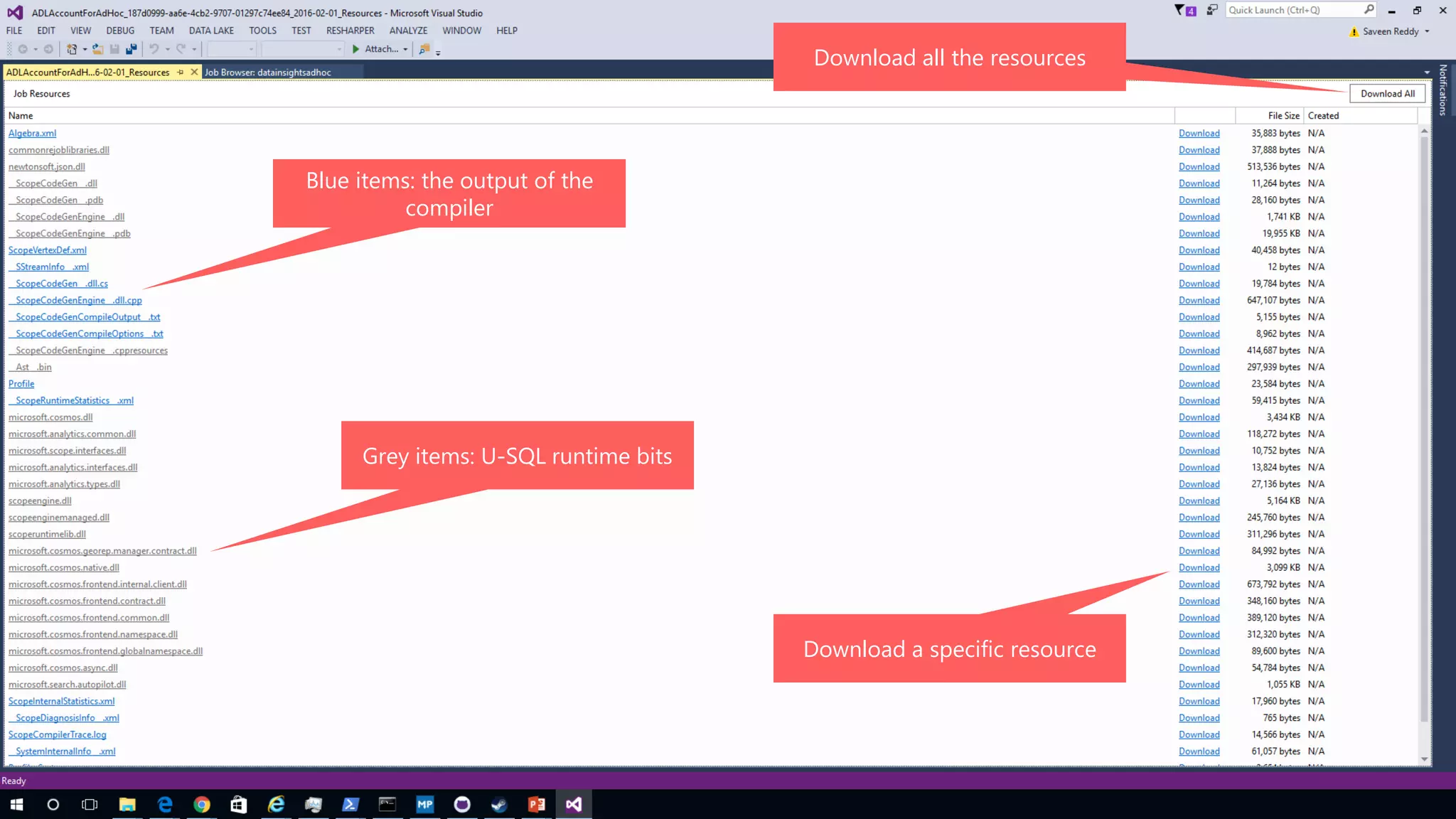

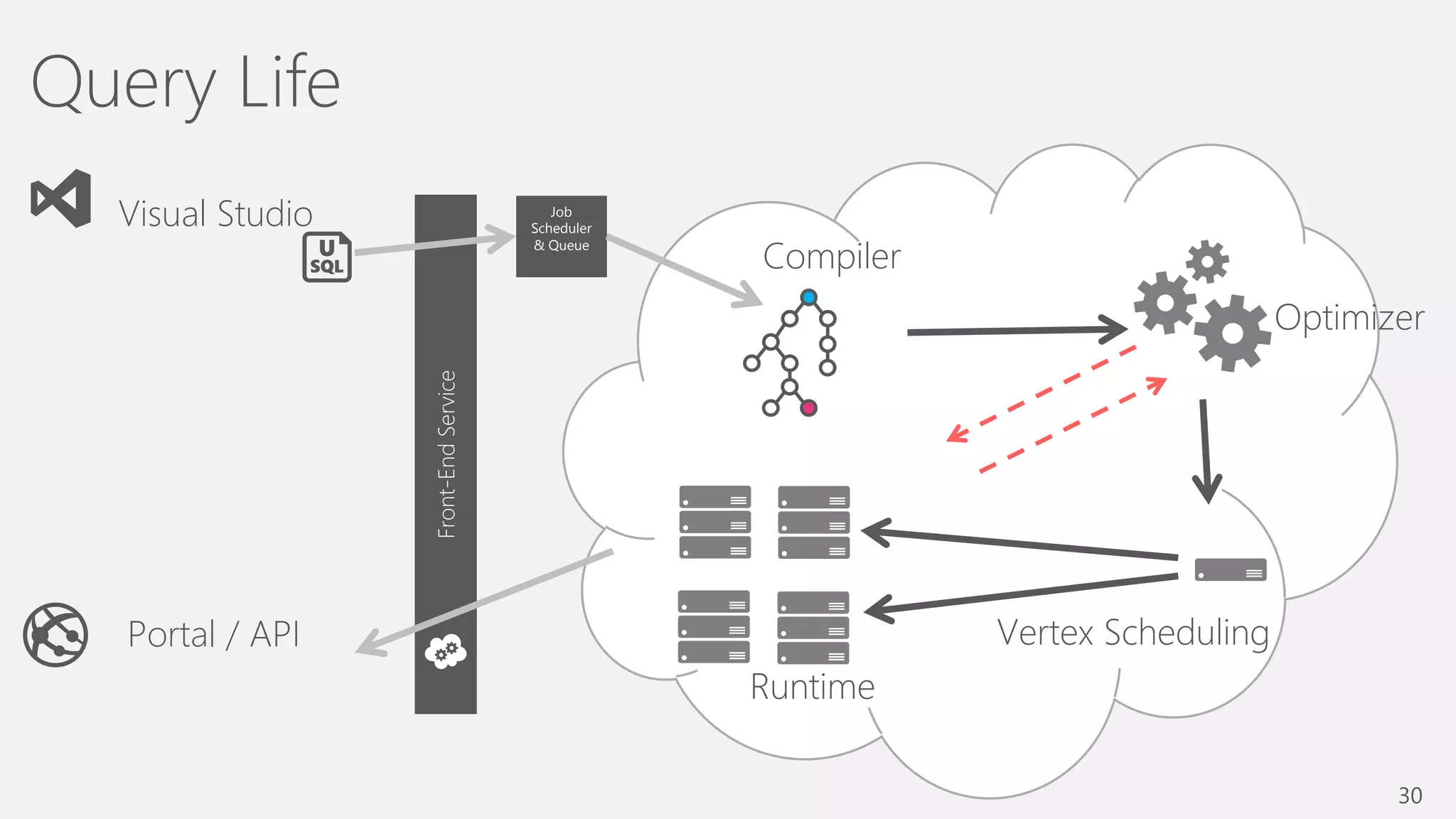
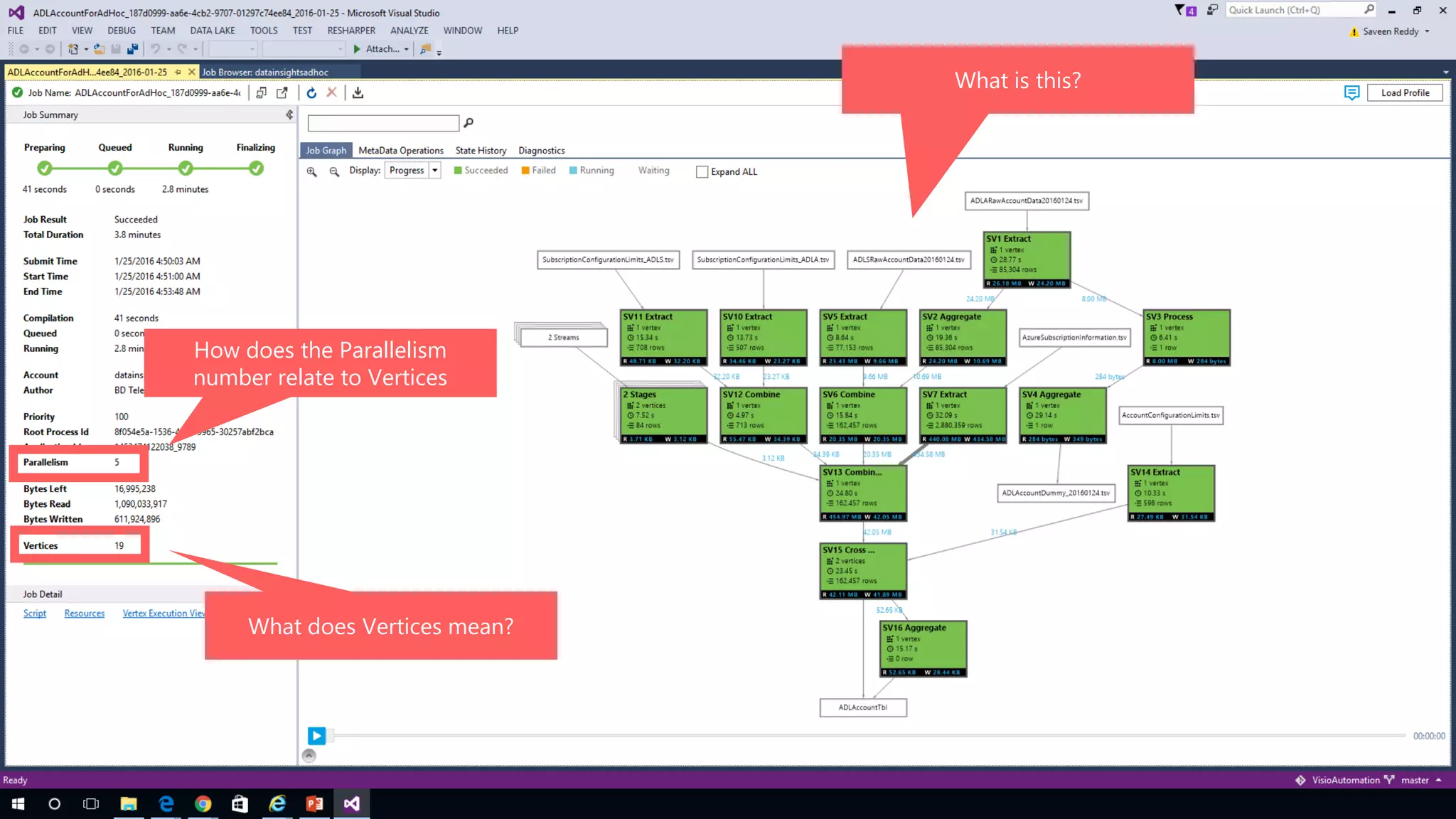
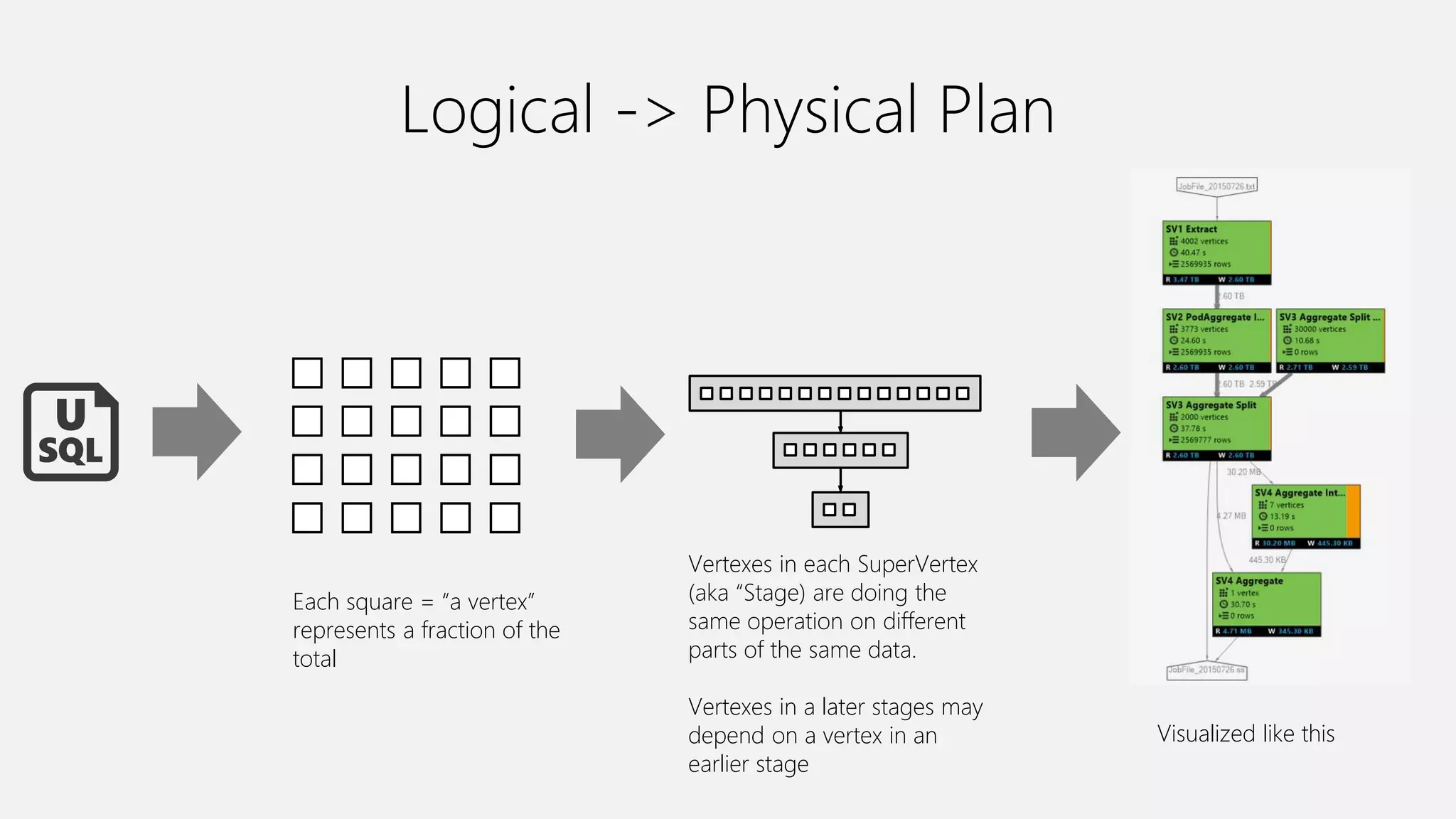
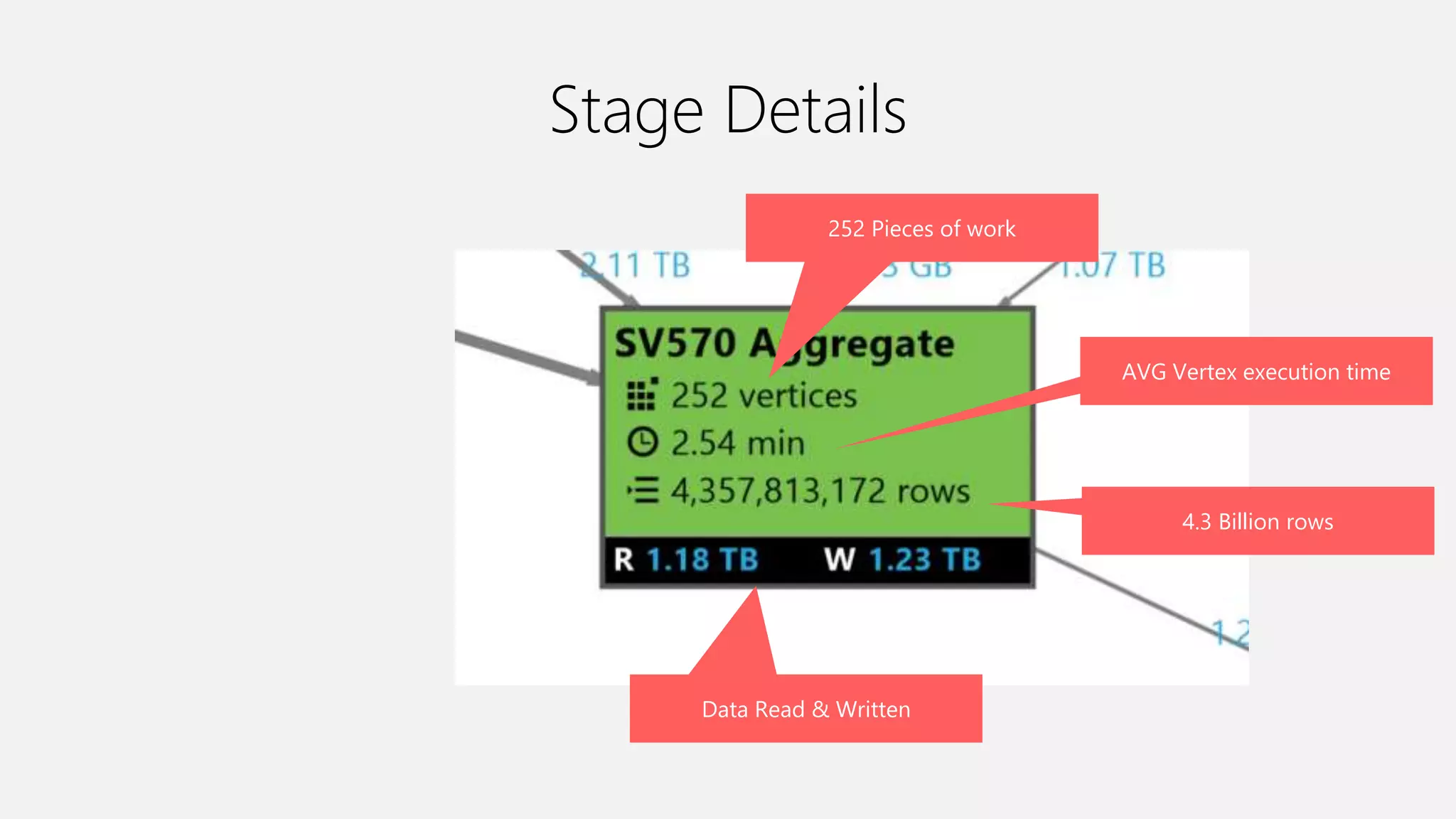



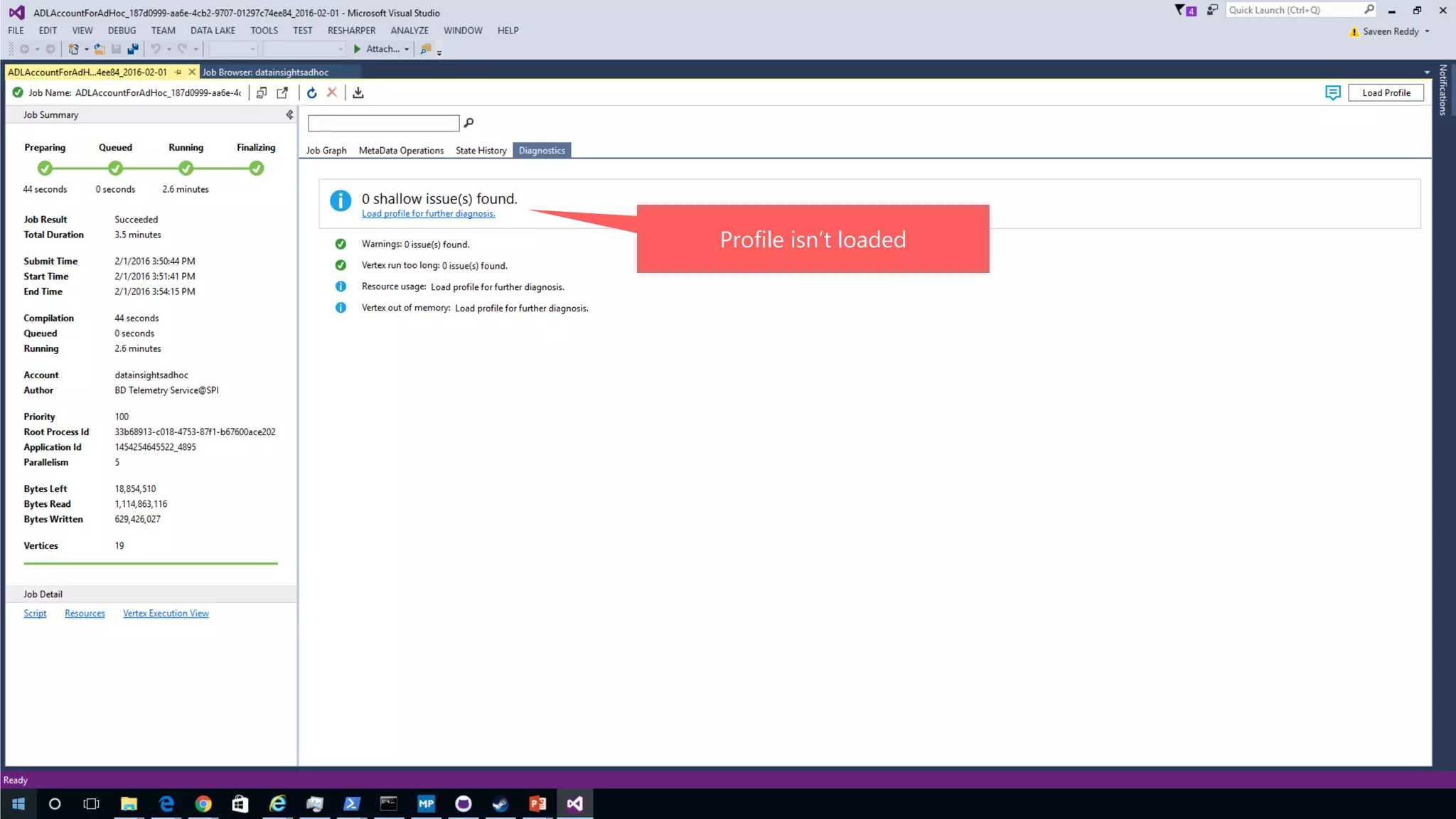
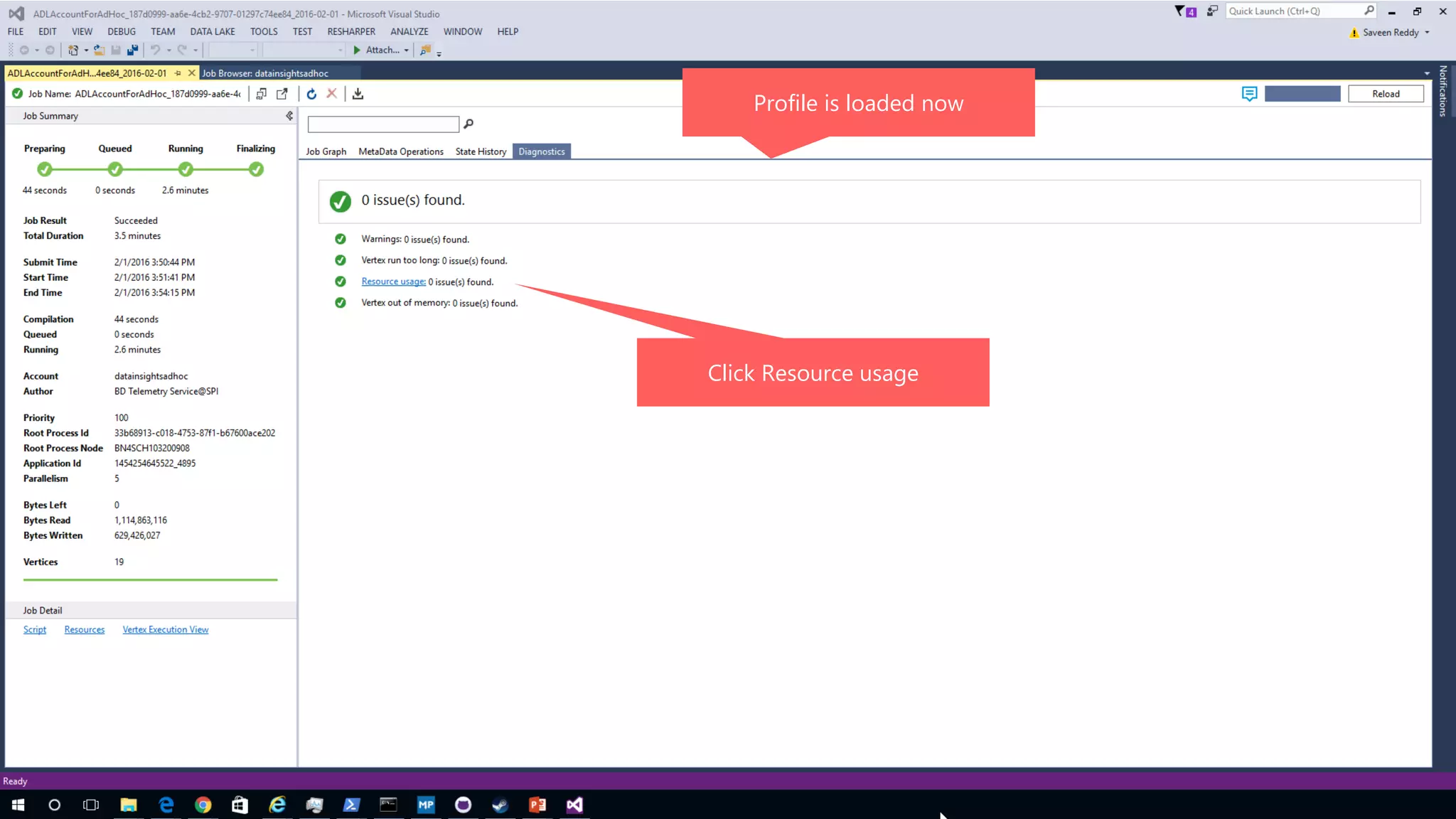
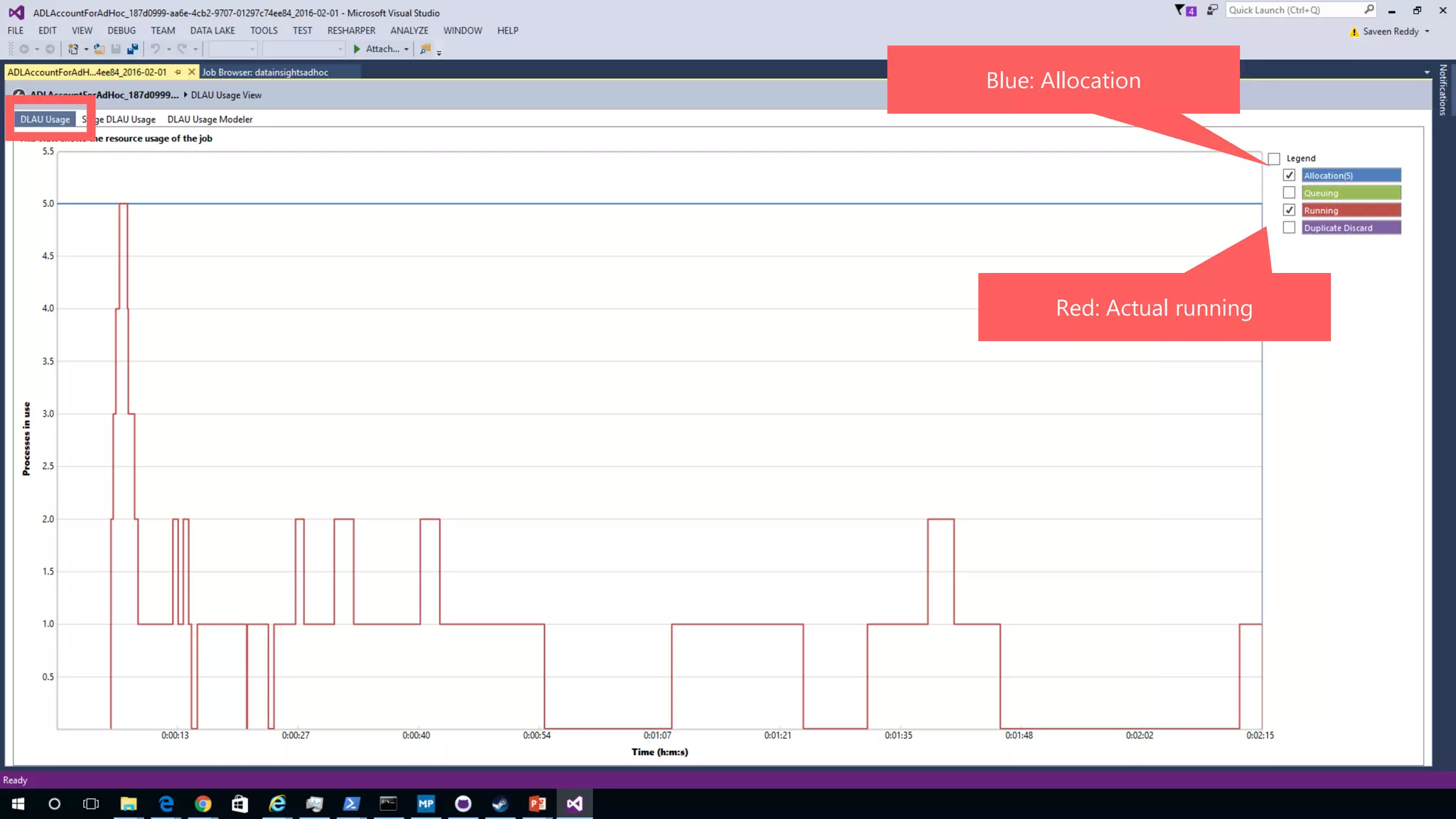
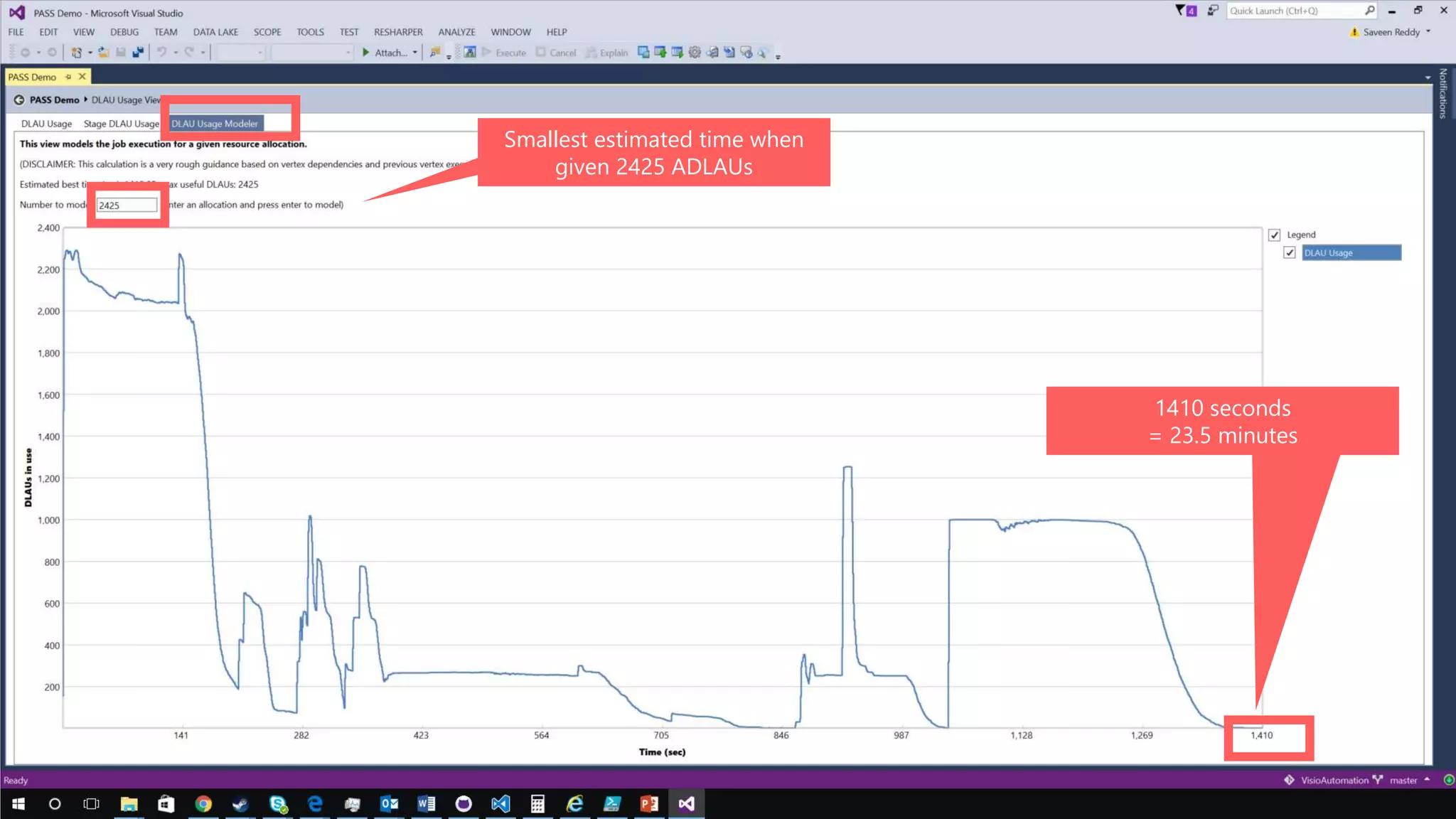
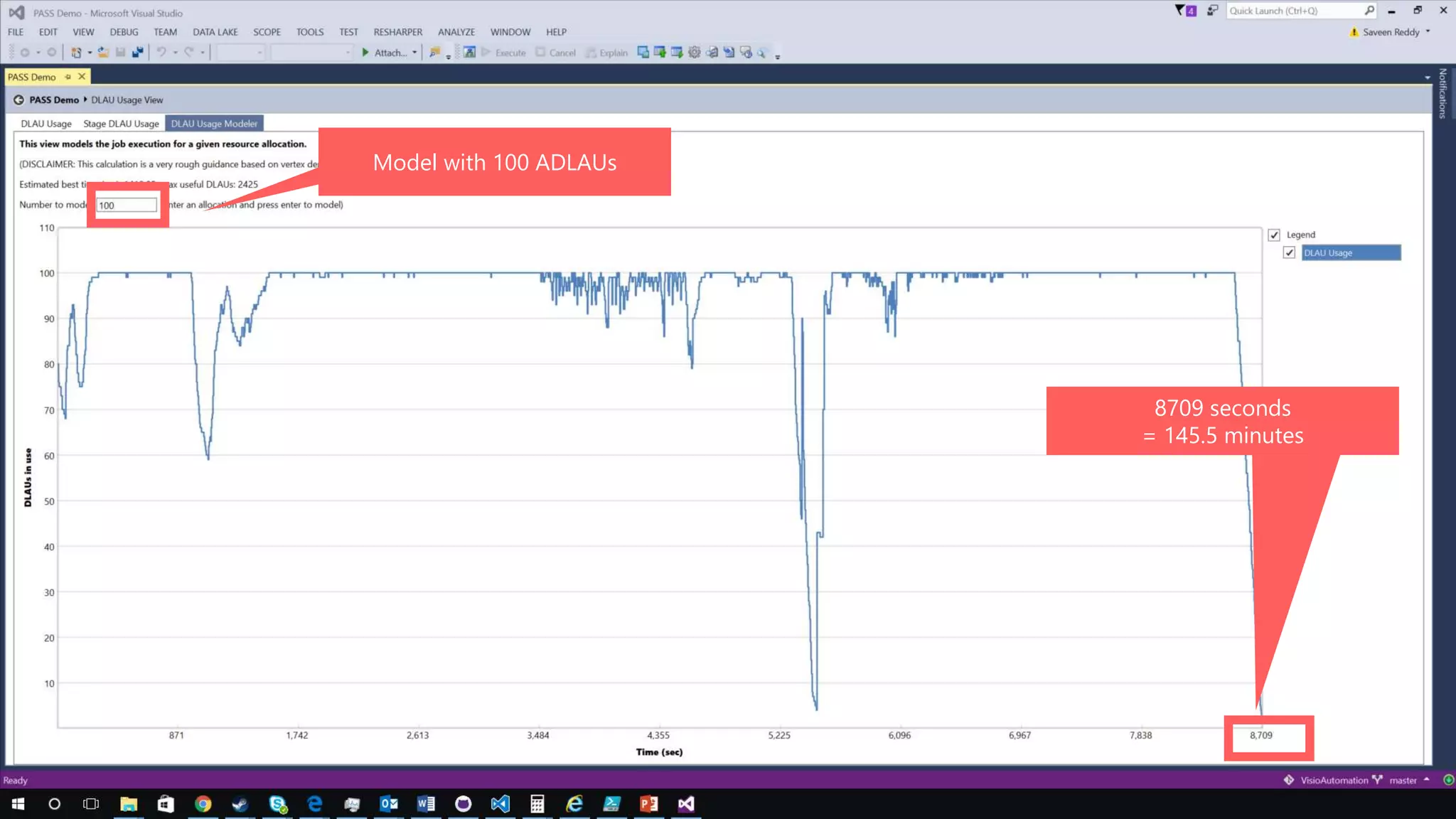

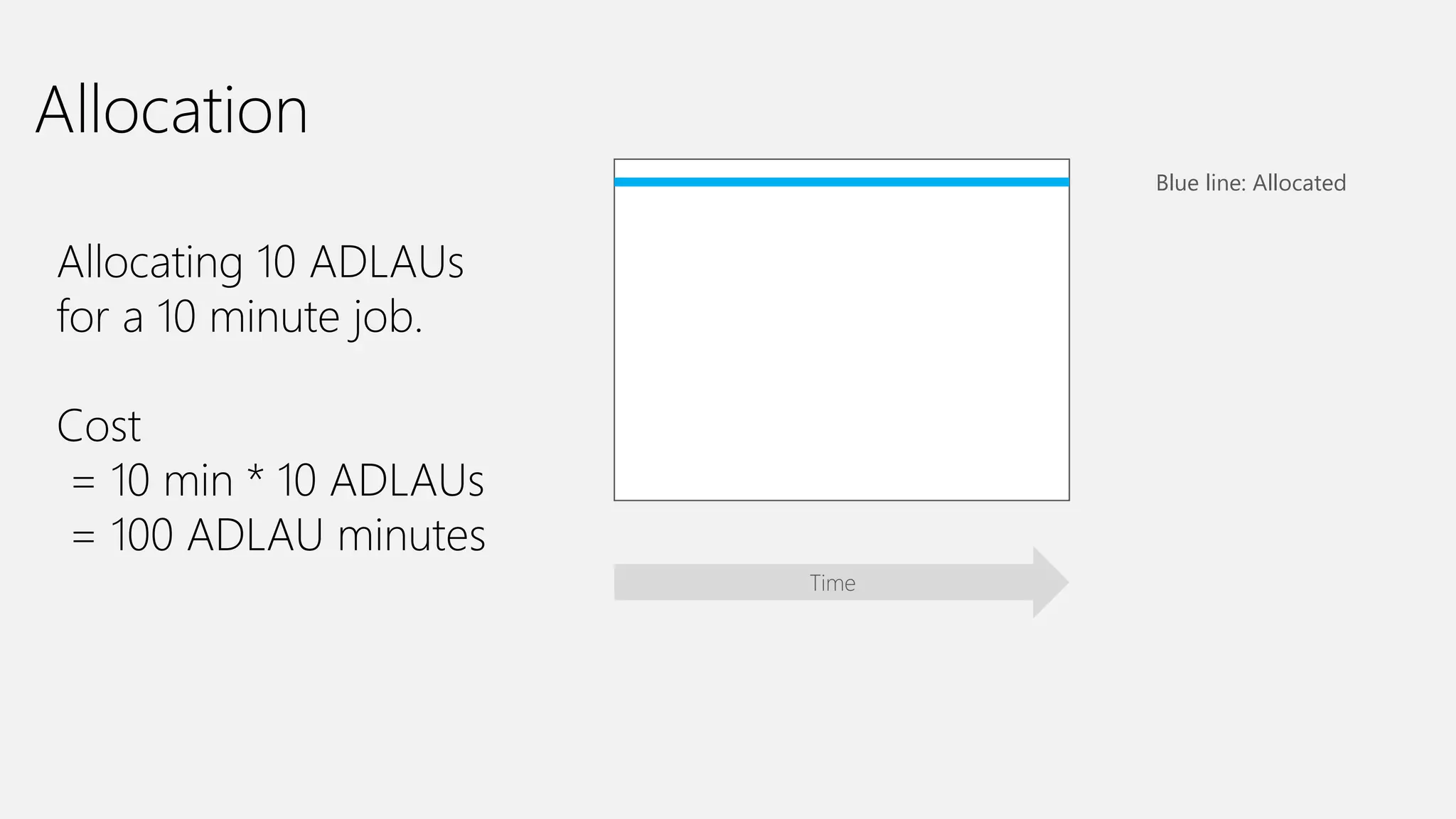



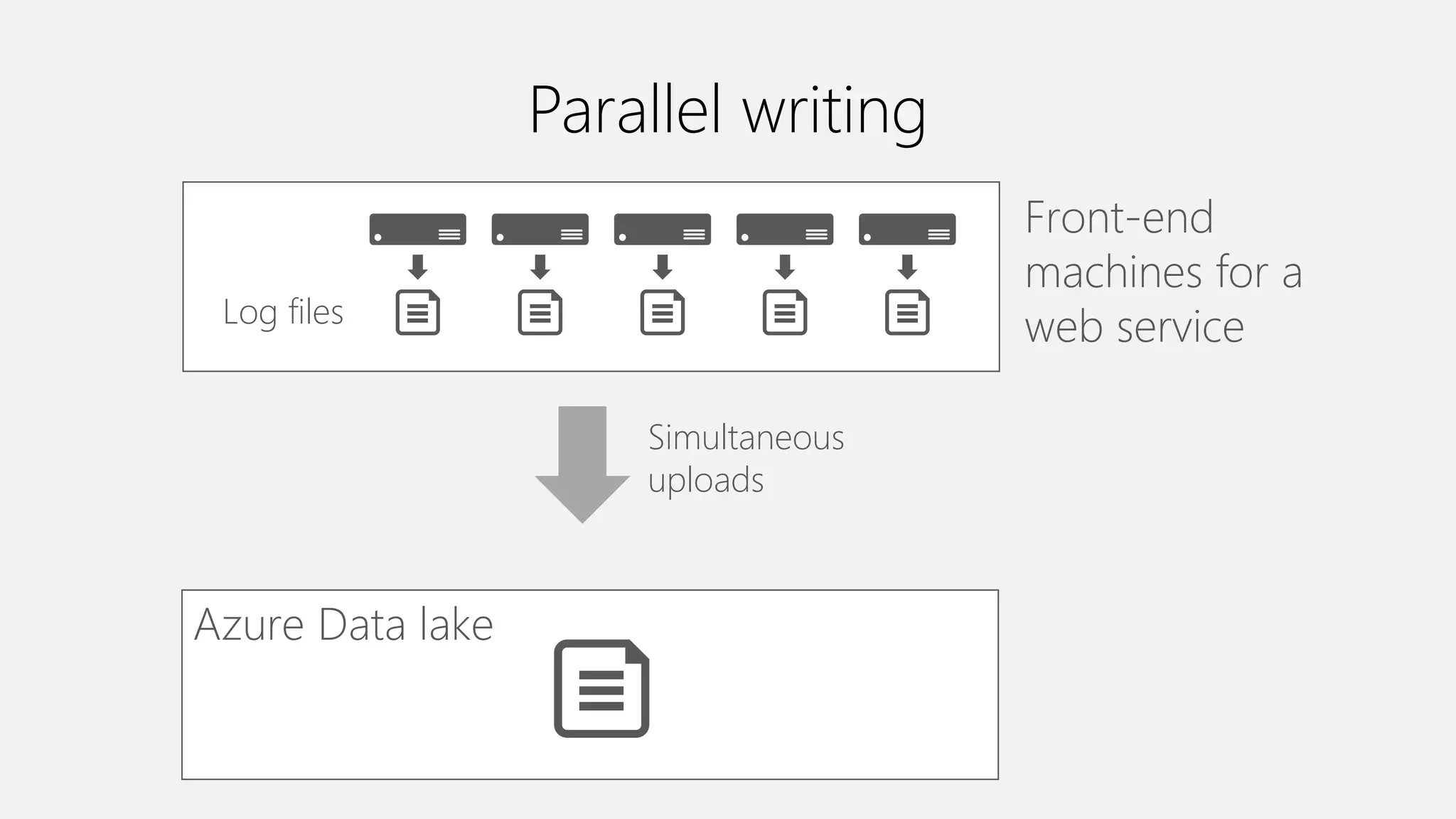
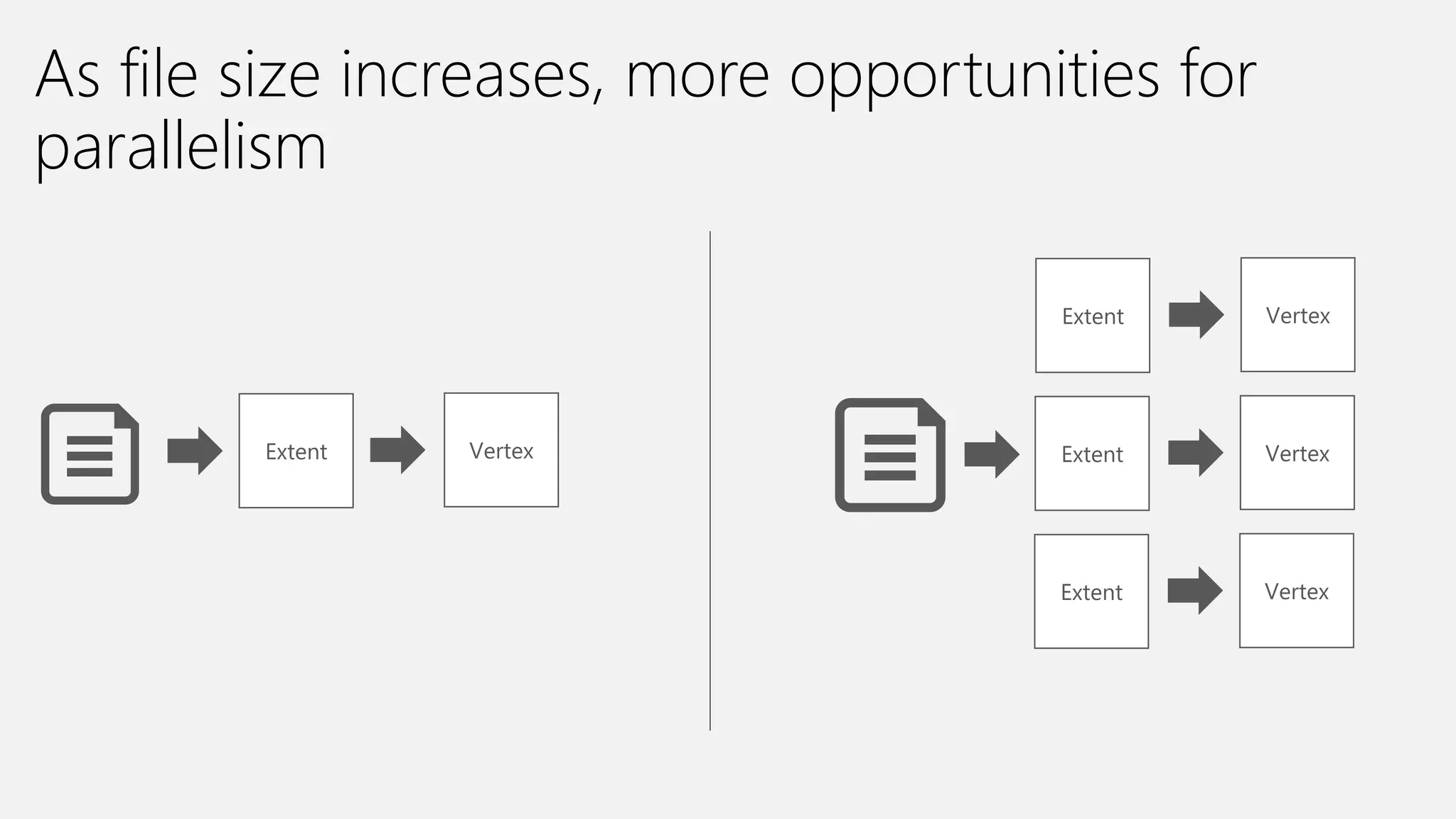

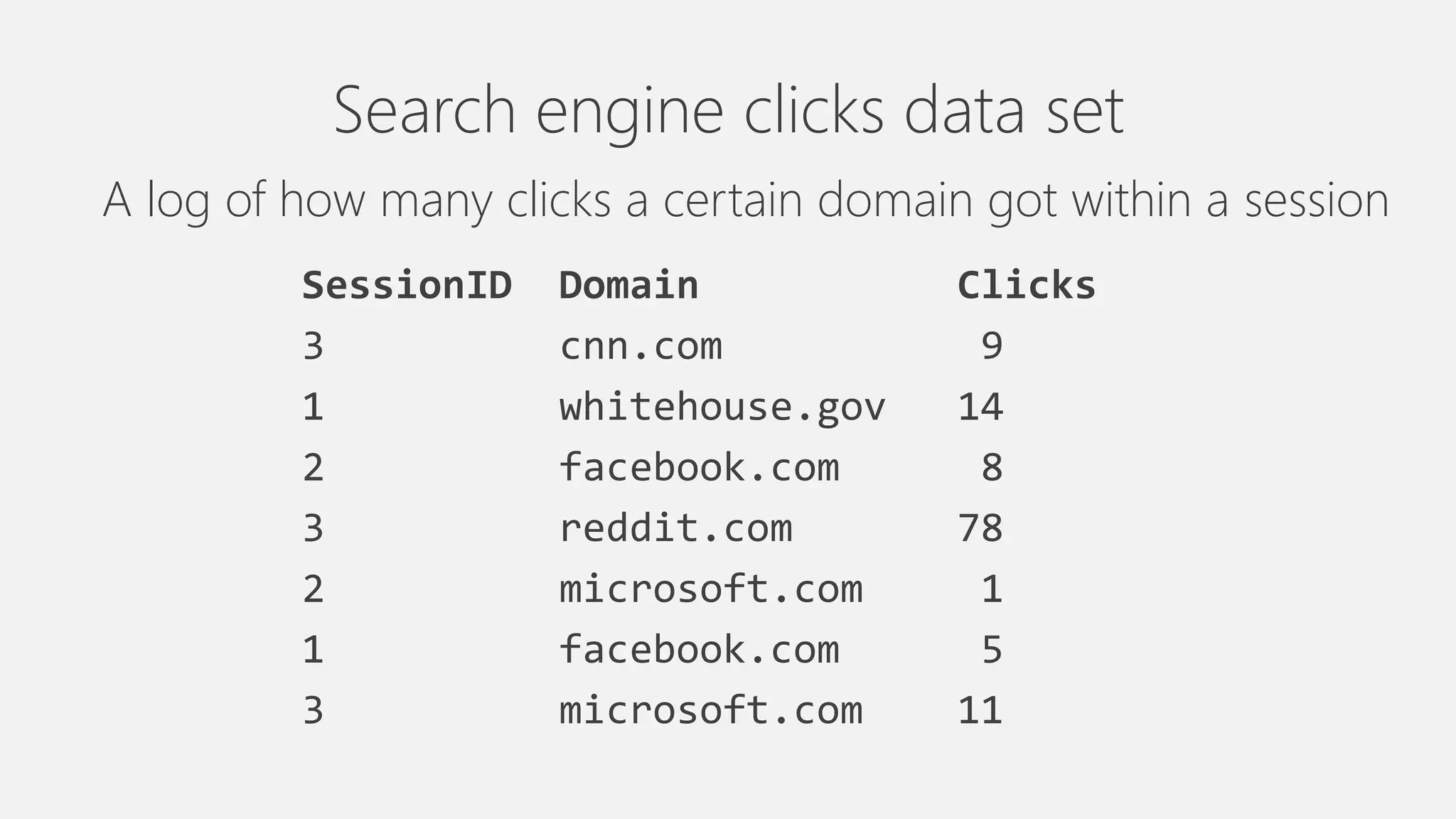


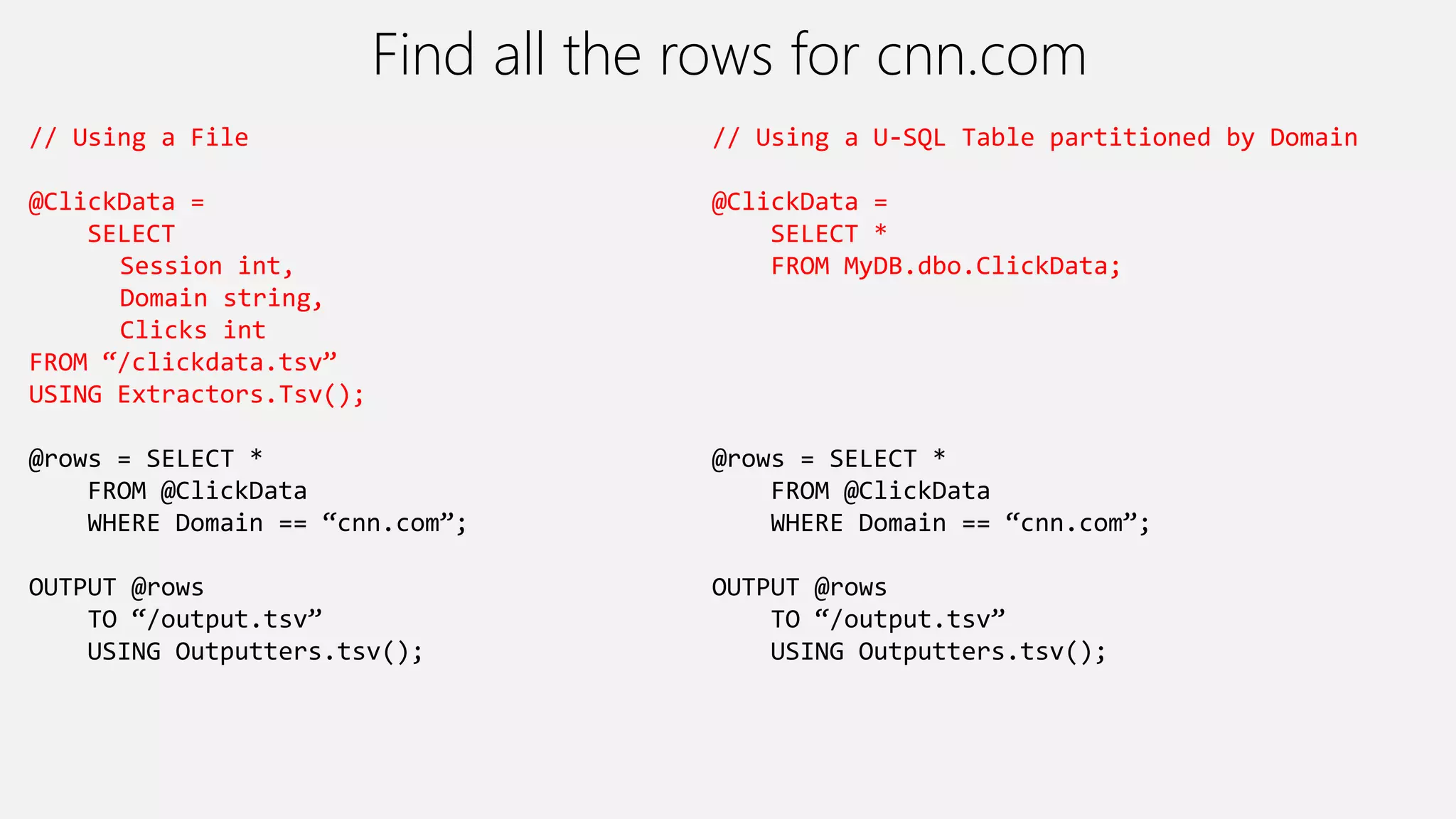
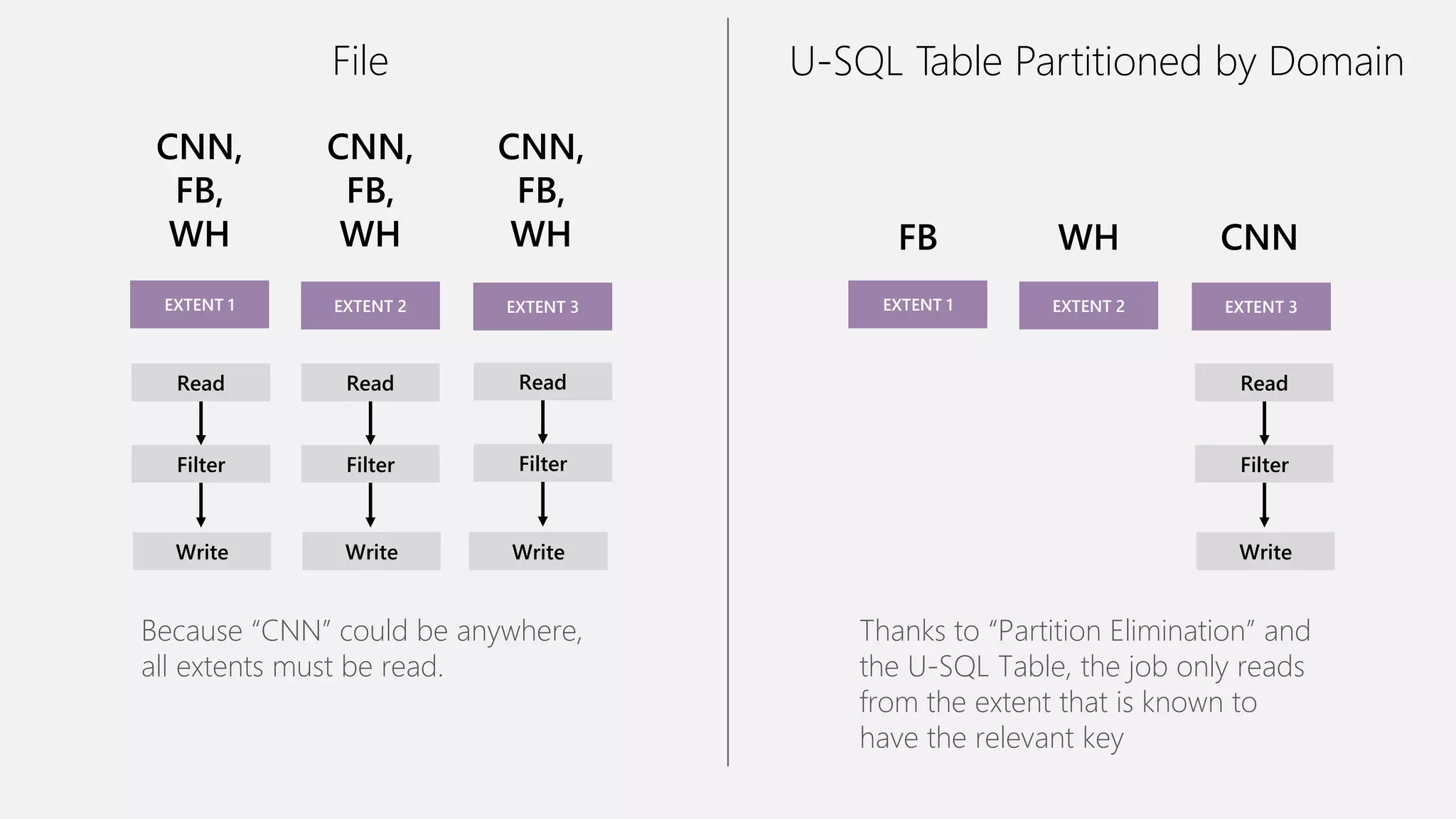

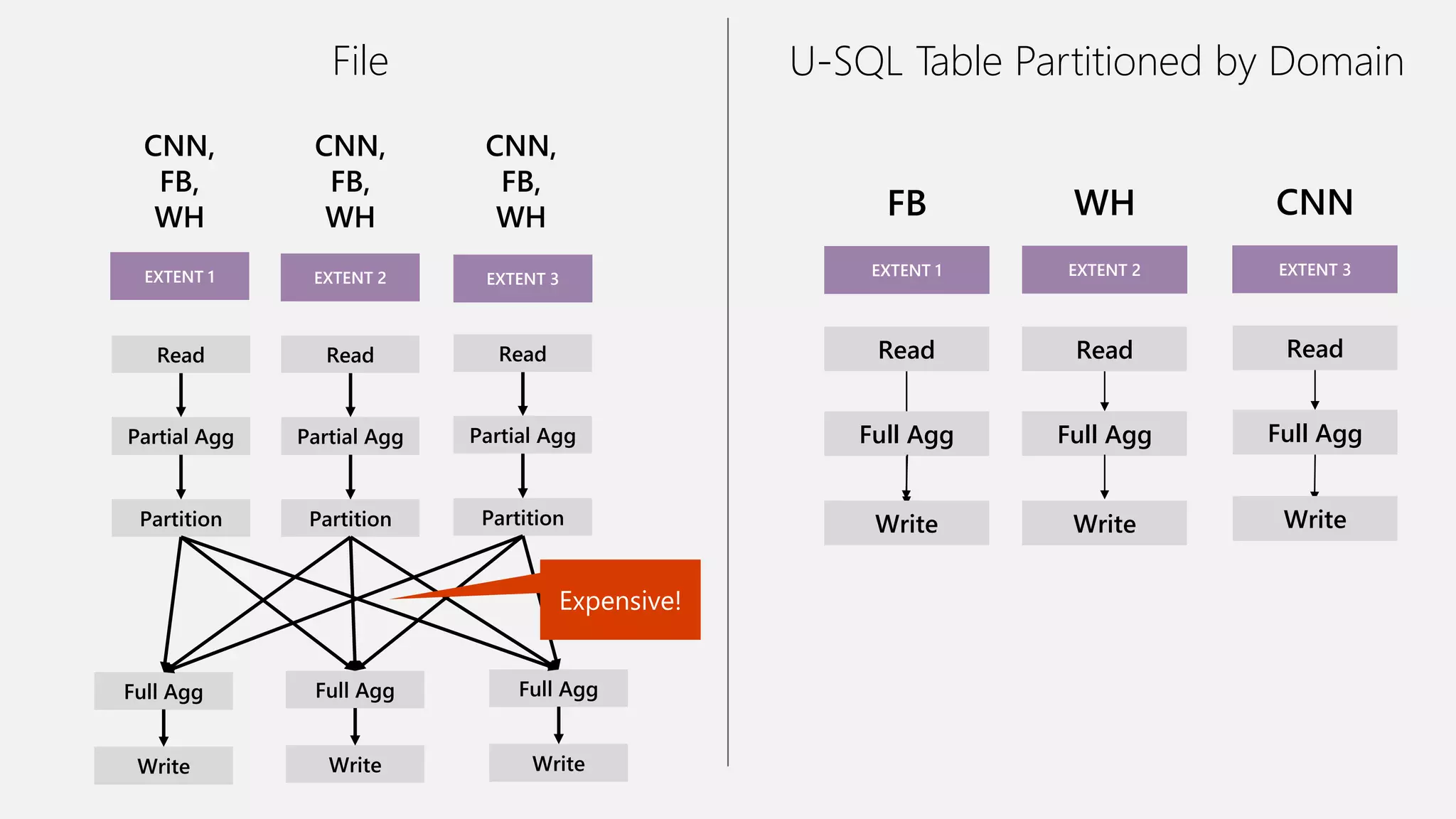




Azure Data Lake Analytics provides a big data analytics service for processing large amounts of data stored in Azure Data Lake Store. It allows users to run analytics jobs using U-SQL, a language that unifies SQL with C# for querying structured, semi-structured and unstructured data. Jobs are compiled, scheduled and run in parallel across multiple Azure Data Lake Analytics Units (ADLAUs). The key components include storage, a job queue, parallelization, and a U-SQL runtime. Partitioning input data improves performance by enabling partition elimination and parallel aggregation of query results.










































































![Number_Guessing_Game_Dsbsbssbzboc[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/numberguessinggamedoc1-251206215042-a076fc05-thumbnail.jpg?width=640&height=640&fit=bounds)








