Downloaded 25 times














![Managing
Assemblies
• CREATE ASSEMBLY db.assembly FROM @path;
• CREATE ASSEMBLY db.assembly FROM byte[];
• Can also include additional resource files
• REFERENCE ASSEMBLY db.assembly;
• Referencing .Net Framework Assemblies
• Always accessible system namespaces:
• U-SQL specific (e.g., for SQL.MAP)
• All provided by system.dll system.core.dll
system.data.dll, System.Runtime.Serialization.dll,
mscorelib.dll (e.g., System.Text,
System.Text.RegularExpressions, System.Linq)
• Add all other .Net Framework Assemblies with:
REFERENCE SYSTEM ASSEMBLY [System.XML];
• Enumerating Assemblies
• Powershell command
• U-SQL Studio Server Explorer
• DROP ASSEMBLY db.assembly;
Create assemblies
Reference assemblies
Enumerate assemblies
Drop assemblies
VisualStudio makes registration easy!](https://image.slidesharecdn.com/br014-usqlintromrys-160928180633/75/Taming-the-Data-Science-Monster-with-A-New-Sword-U-SQL-19-2048.jpg)
!['USING' csharp_namespace
| Alias '=' csharp_namespace_or_class.
Examples:
DECLARE @ input string = "somejsonfile.json";
REFERENCE ASSEMBLY [Newtonsoft.Json];
REFERENCE ASSEMBLY [Microsoft.Analytics.Samples.Formats];
USING Microsoft.Analytics.Samples.Formats.Json;
@data0 =
EXTRACT IPAddresses string
FROM @input
USING new JsonExtractor("Devices[*]");
USING json =
[Microsoft.Analytics.Samples.Formats.Json.JsonExtractor];
@data1 =
EXTRACT IPAddresses string
FROM @input
USING new json("Devices[*]");](https://image.slidesharecdn.com/br014-usqlintromrys-160928180633/75/Taming-the-Data-Science-Monster-with-A-New-Sword-U-SQL-20-2048.jpg)



![ADLA Account/Catalog
Database
Schema
[1,n]
[1,n]
[0,n]
tables views TVFs
C# Fns C# UDAgg
Clustered
Index
partitions
C#
Assemblies
C# Extractors
Data
Source
C# Reducers
C# Processors
C# Combiners
C# Outputters
Ext. tables
Abstract
objects
User
objects
Refers toContains Implemented
and named by
Procedures
Creden-
tials
MD
Name
C# Name
C# Applier
Table Types
Legend
Statistics
C# UDTs](https://image.slidesharecdn.com/br014-usqlintromrys-160928180633/75/Taming-the-Data-Science-Monster-with-A-New-Sword-U-SQL-24-2048.jpg)
![• Naming
• Discovery
• Sharing
• Securing
U-SQL Catalog Naming
• Default Database and Schema context: master.dbo
• Quote identifiers with []: [my table]
• Stores data in ADL Storage /catalog folder
Discovery
• Visual Studio Server Explorer
• Azure Data Lake Analytics Portal
• SDKs and Azure Powershell commands
Sharing
• Within an Azure Data Lake Analytics account
Securing
• Secured with AAD principals at catalog level (inherited from ADL
Storage)
• At General Availability: Database level access control](https://image.slidesharecdn.com/br014-usqlintromrys-160928180633/75/Taming-the-Data-Science-Monster-with-A-New-Sword-U-SQL-25-2048.jpg)



![U-SQL
Analytics
Windowing Expression
Window_Function_Call 'OVER' '('
[ Over_Partition_By_Clause ]
[ Order_By_Clause ]
[ Row _Clause ]
')'.
Window_Function_Call :=
Aggregate_Function_Call
| Analytic_Function_Call
| Ranking_Function_Call.
Windowing Aggregate Functions
ANY_VALUE, AVG, COUNT, MAX, MIN, SUM, STDEV, STDEVP, VAR, VARP
Analytics Functions
CUME_DIST, FIRST_VALUE, LAST_VALUE, PERCENTILE_CONT,
PERCENTILE_DISC, PERCENT_RANK; soon: LEAD/LAG
Ranking Functions
DENSE_RANK, NTILE, RANK, ROW_NUMBER](https://image.slidesharecdn.com/br014-usqlintromrys-160928180633/75/Taming-the-Data-Science-Monster-with-A-New-Sword-U-SQL-29-2048.jpg)






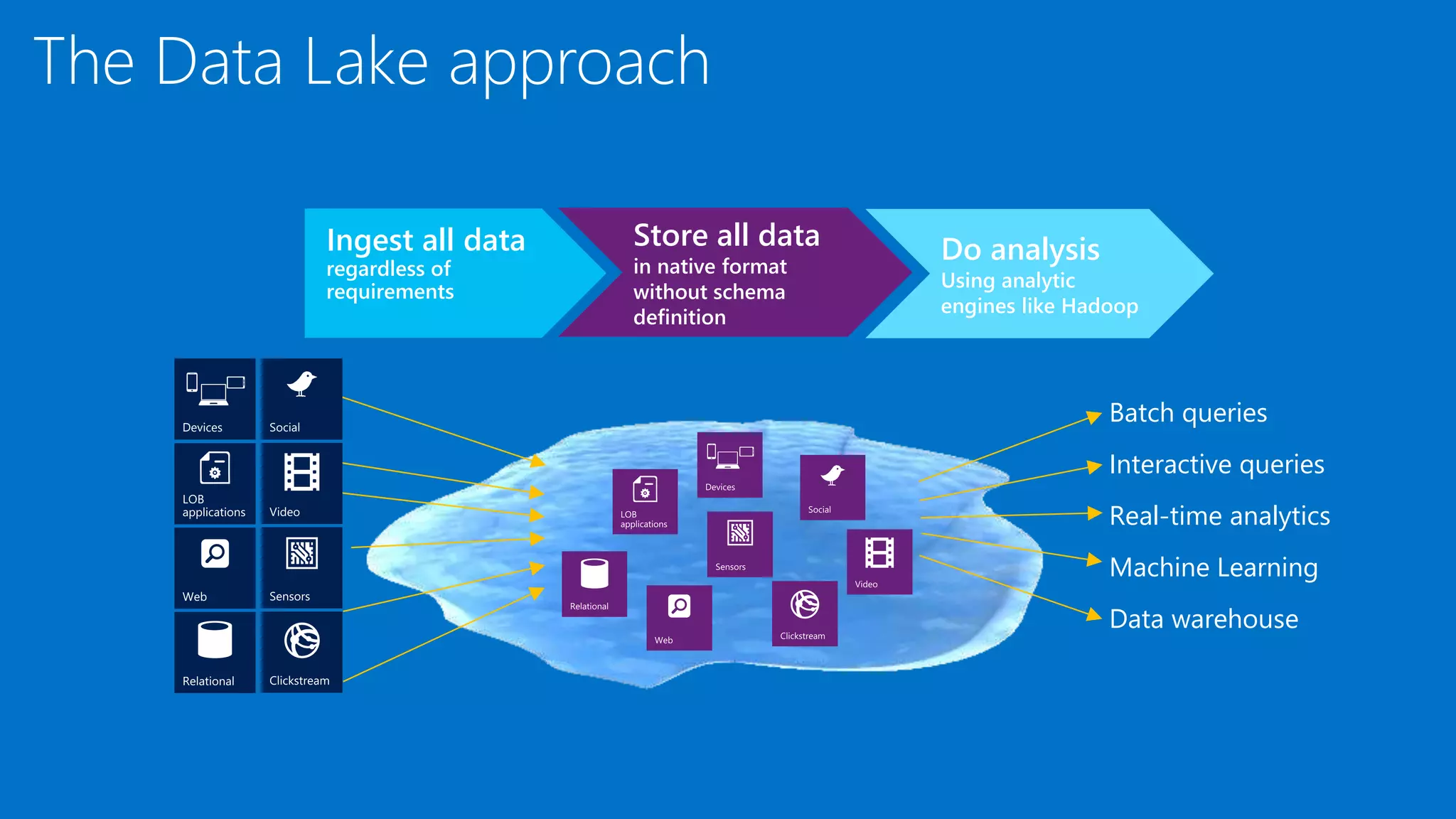
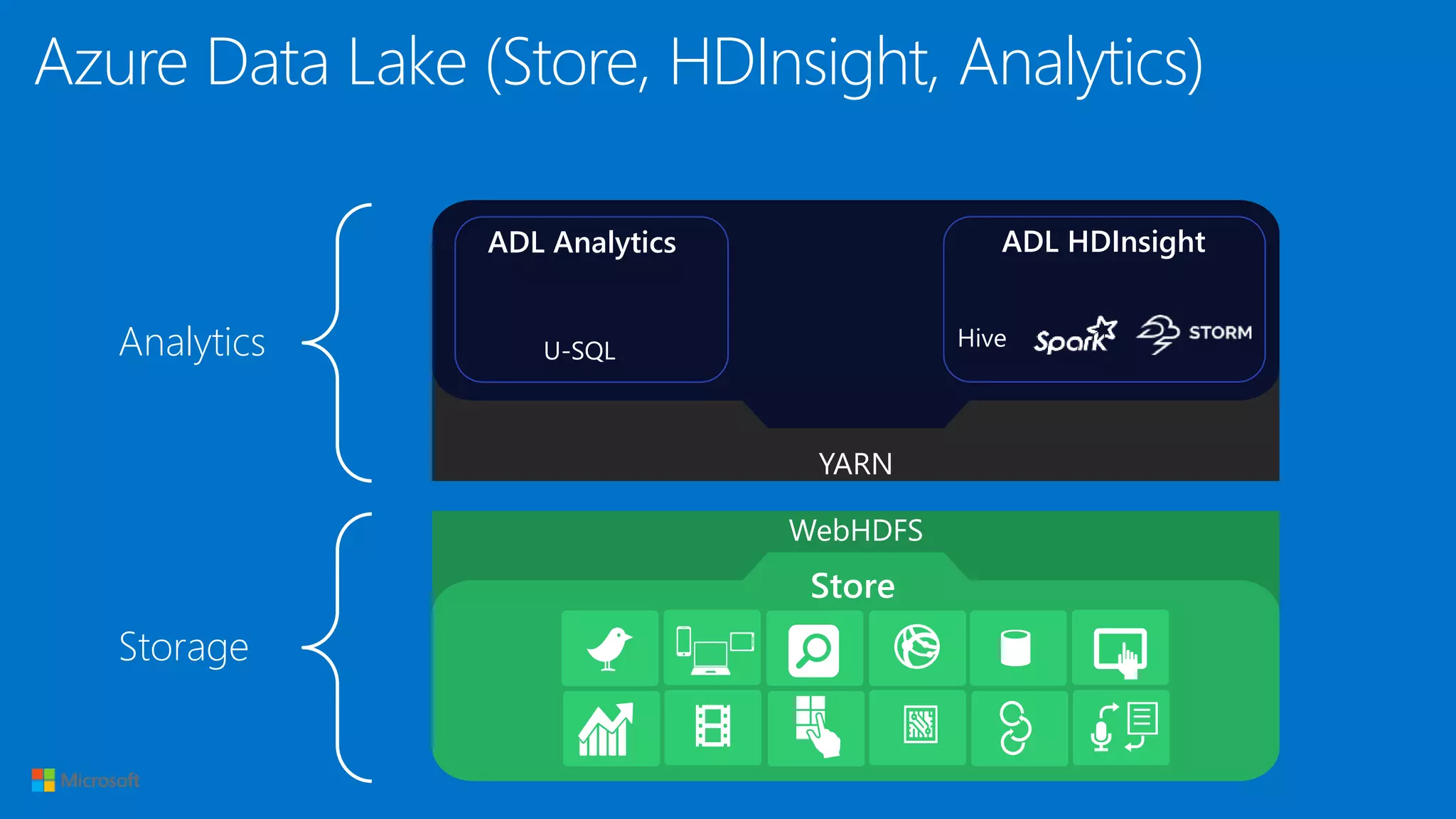
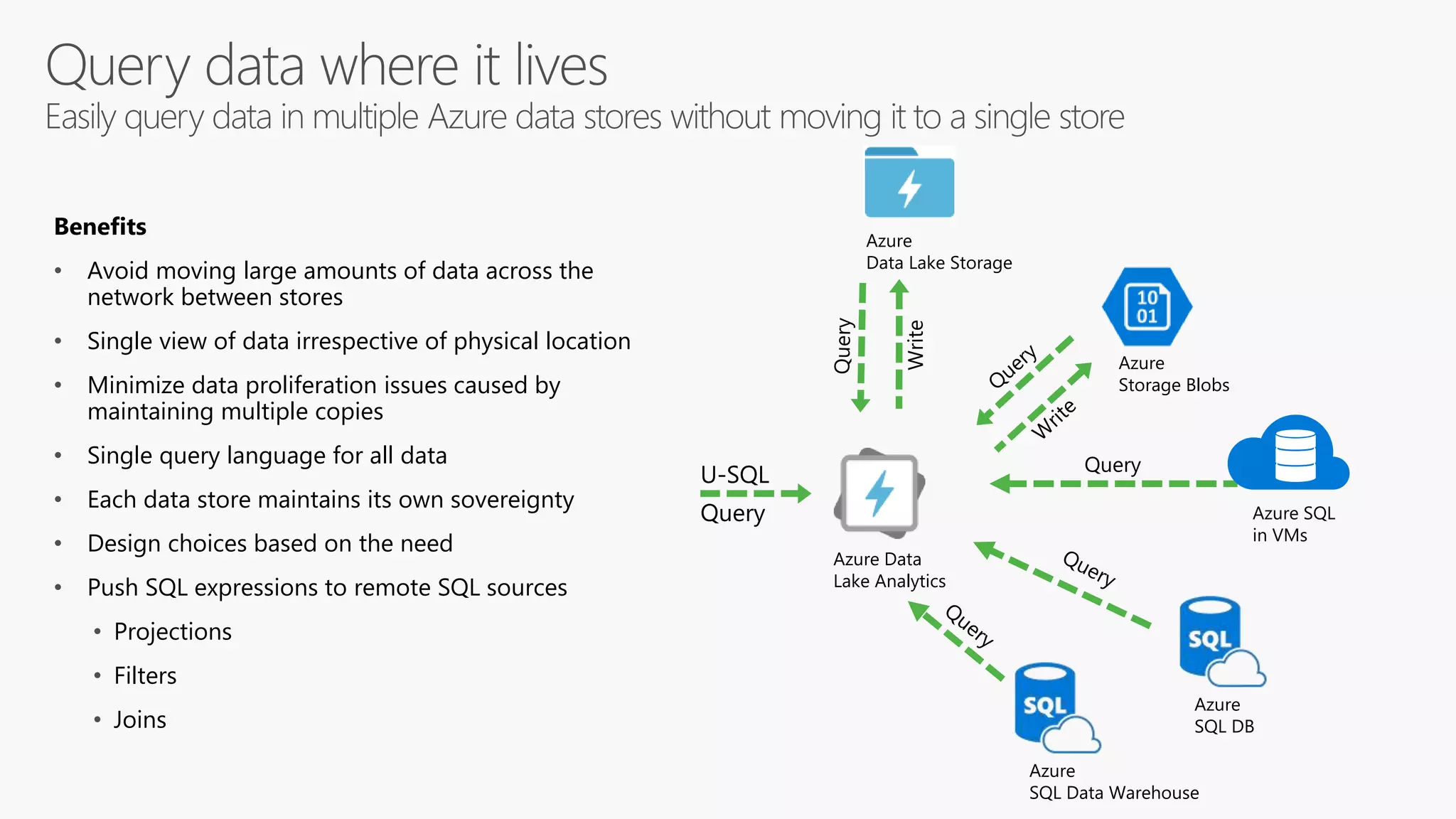
The document introduces Azure Data Lake and the U-SQL language. U-SQL unifies SQL for querying structured and unstructured data, C# for custom code extensibility, and distributed querying across cloud data sources. Some key features discussed include its declarative query model, built-in and user-defined functions and operators, assembly management, and table definitions. Examples demonstrate complex analytics over JSON and CSV files using U-SQL.




















































































