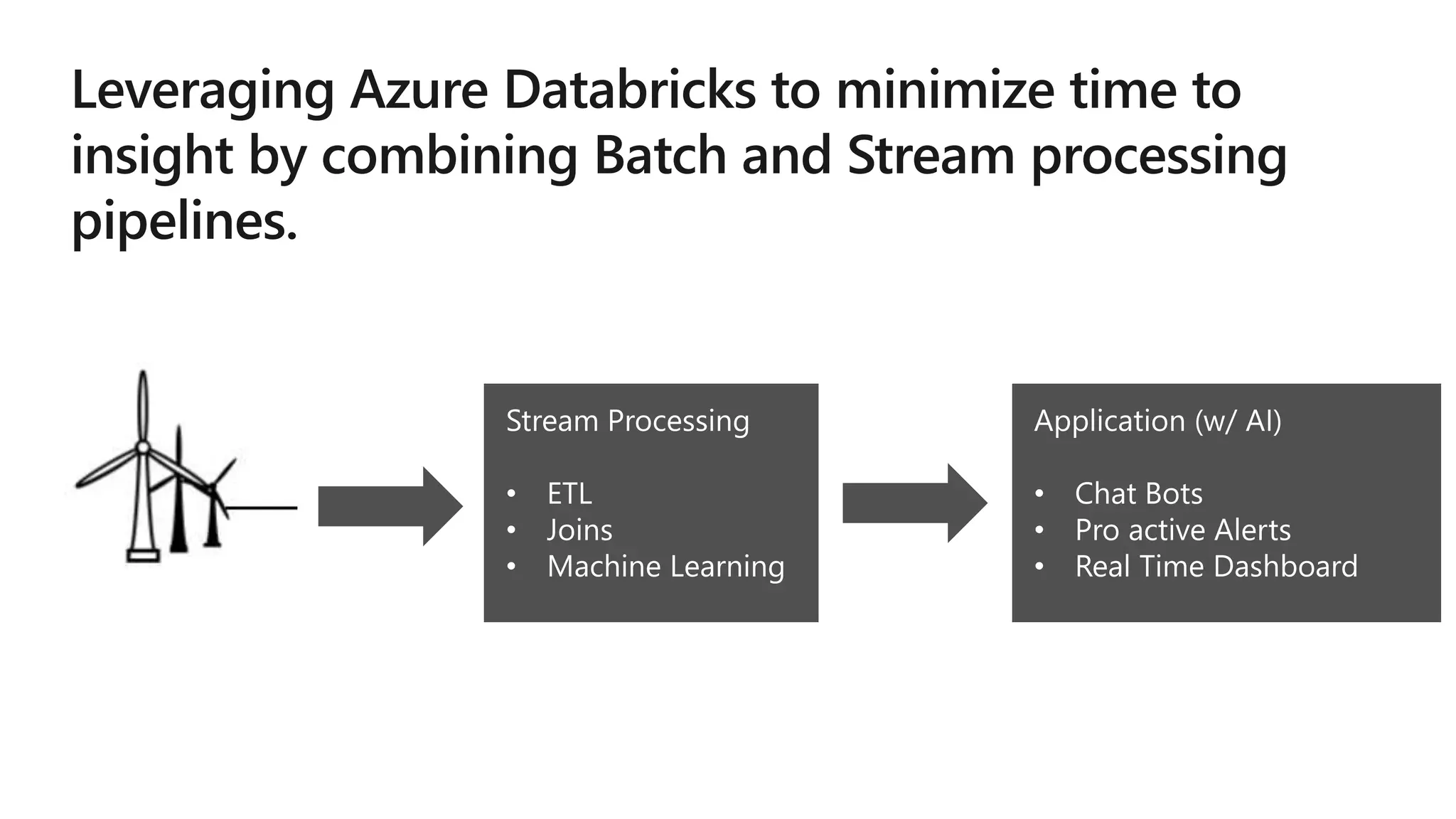
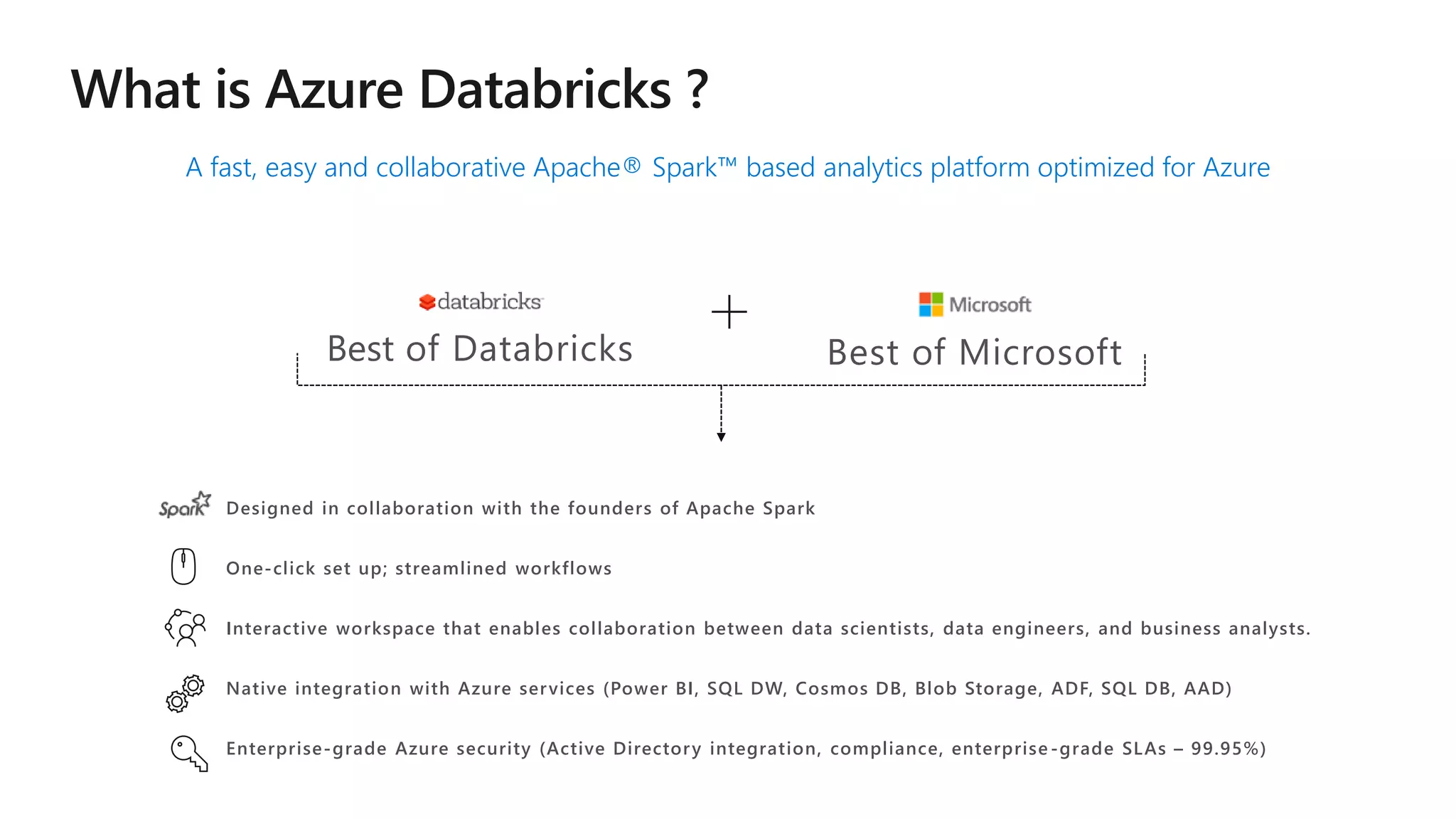
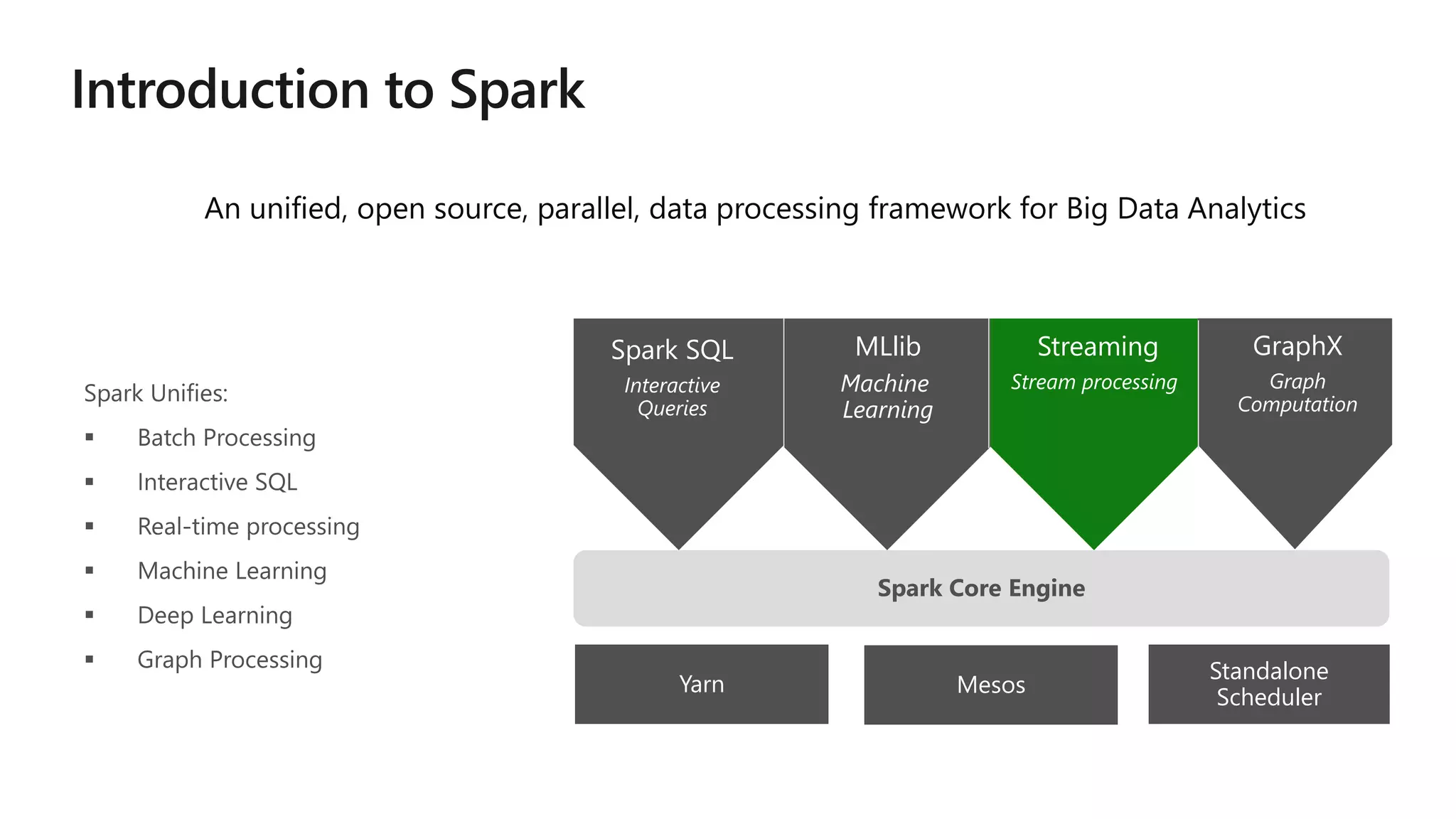
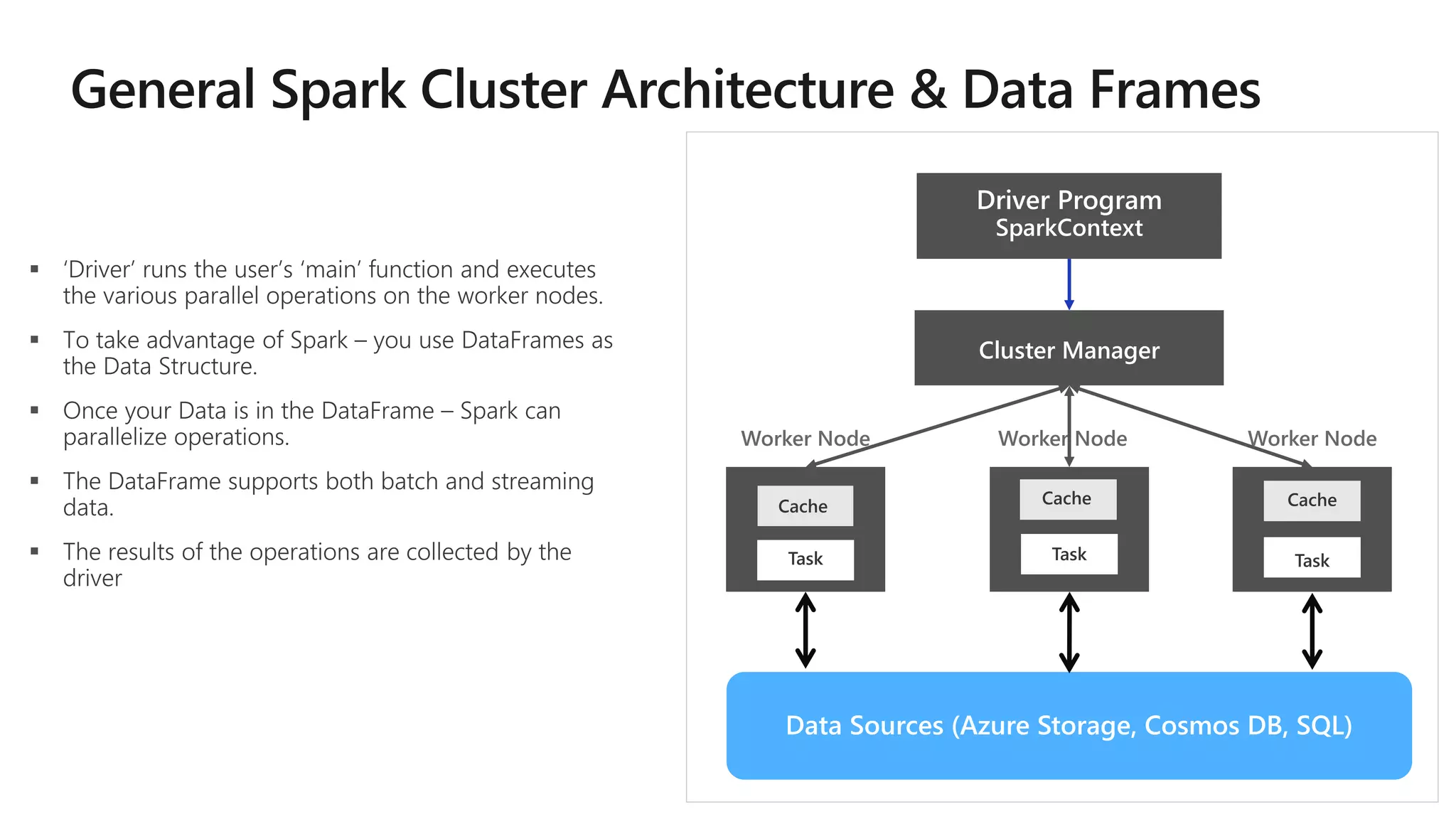
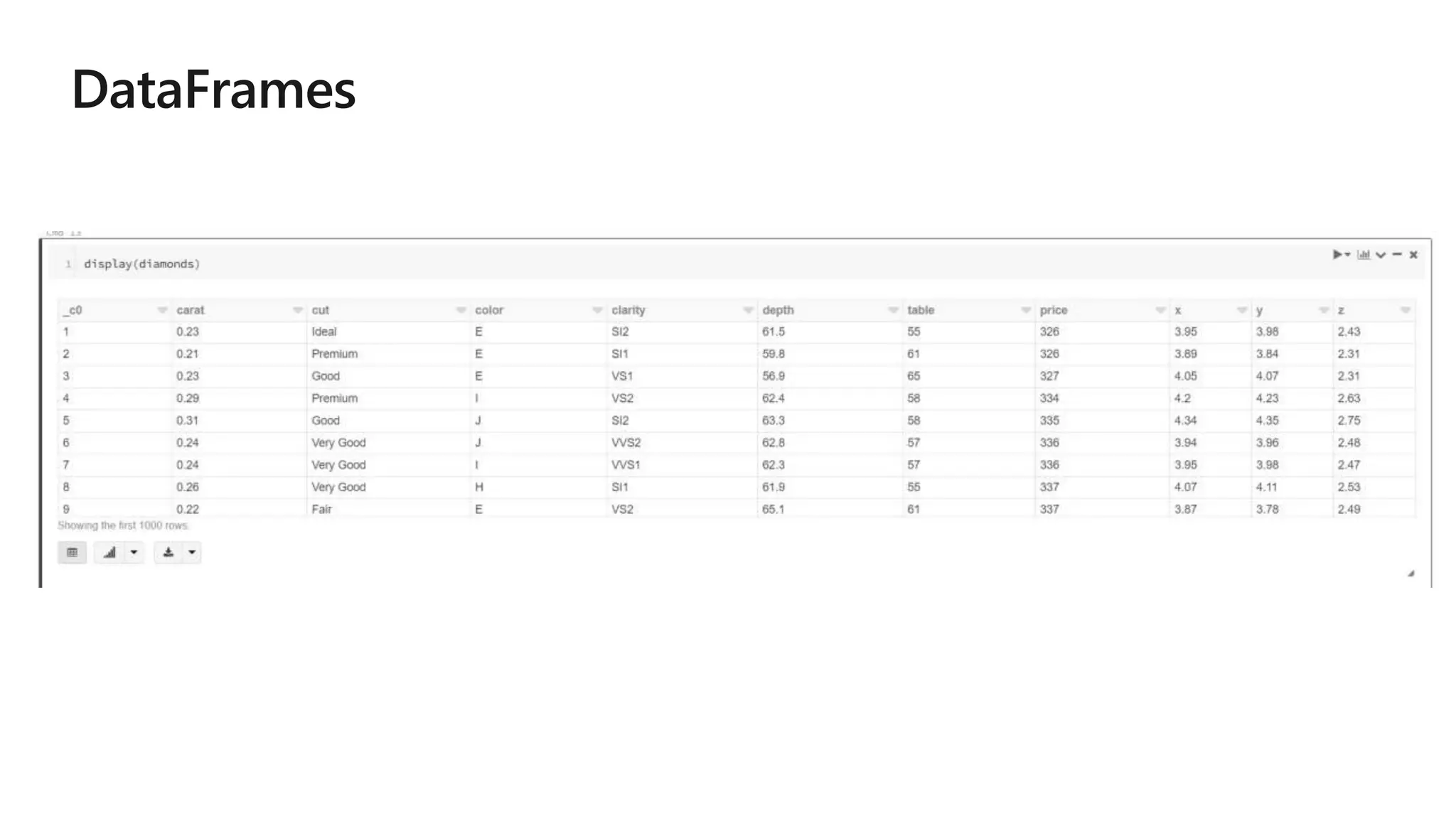
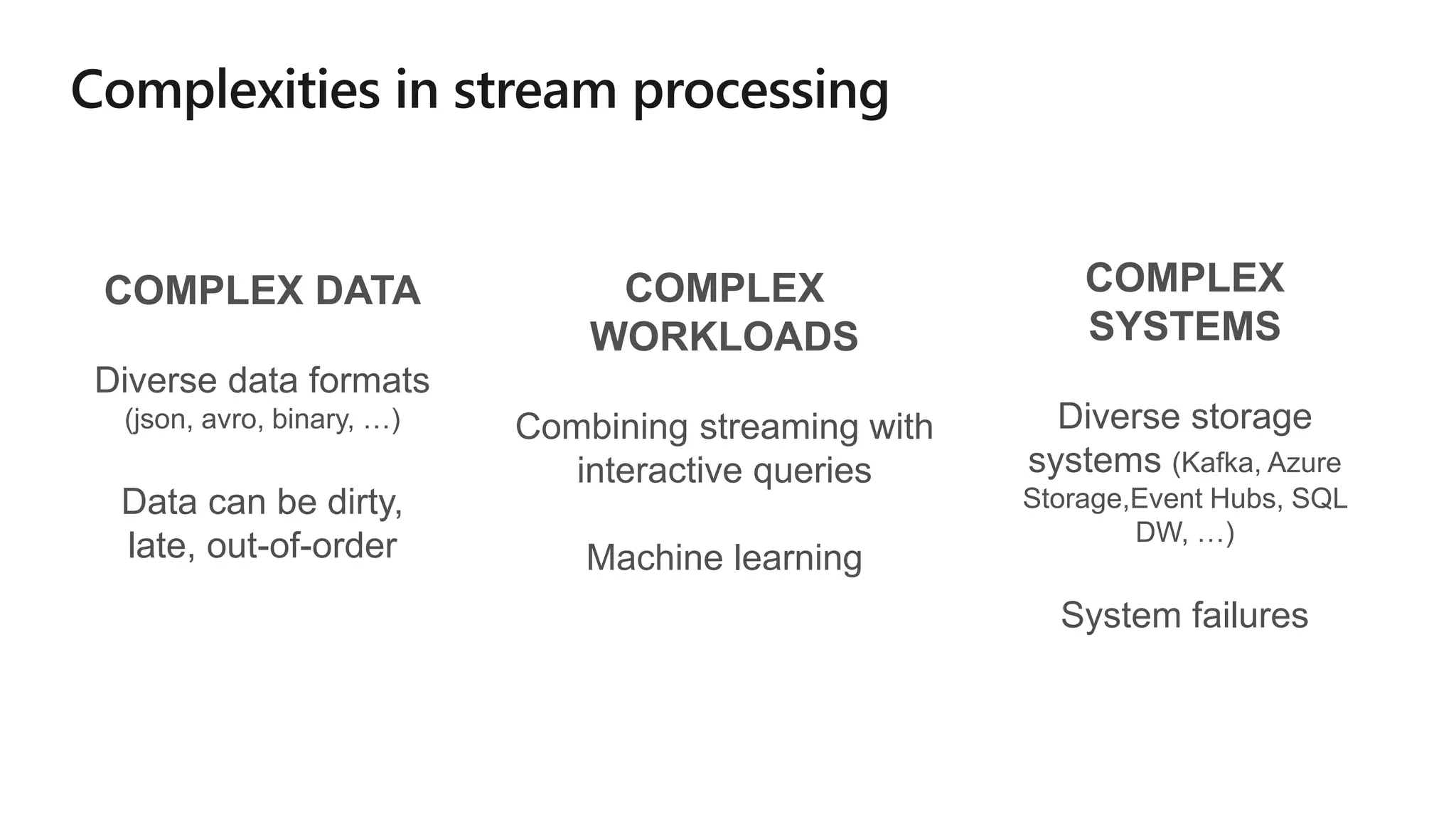
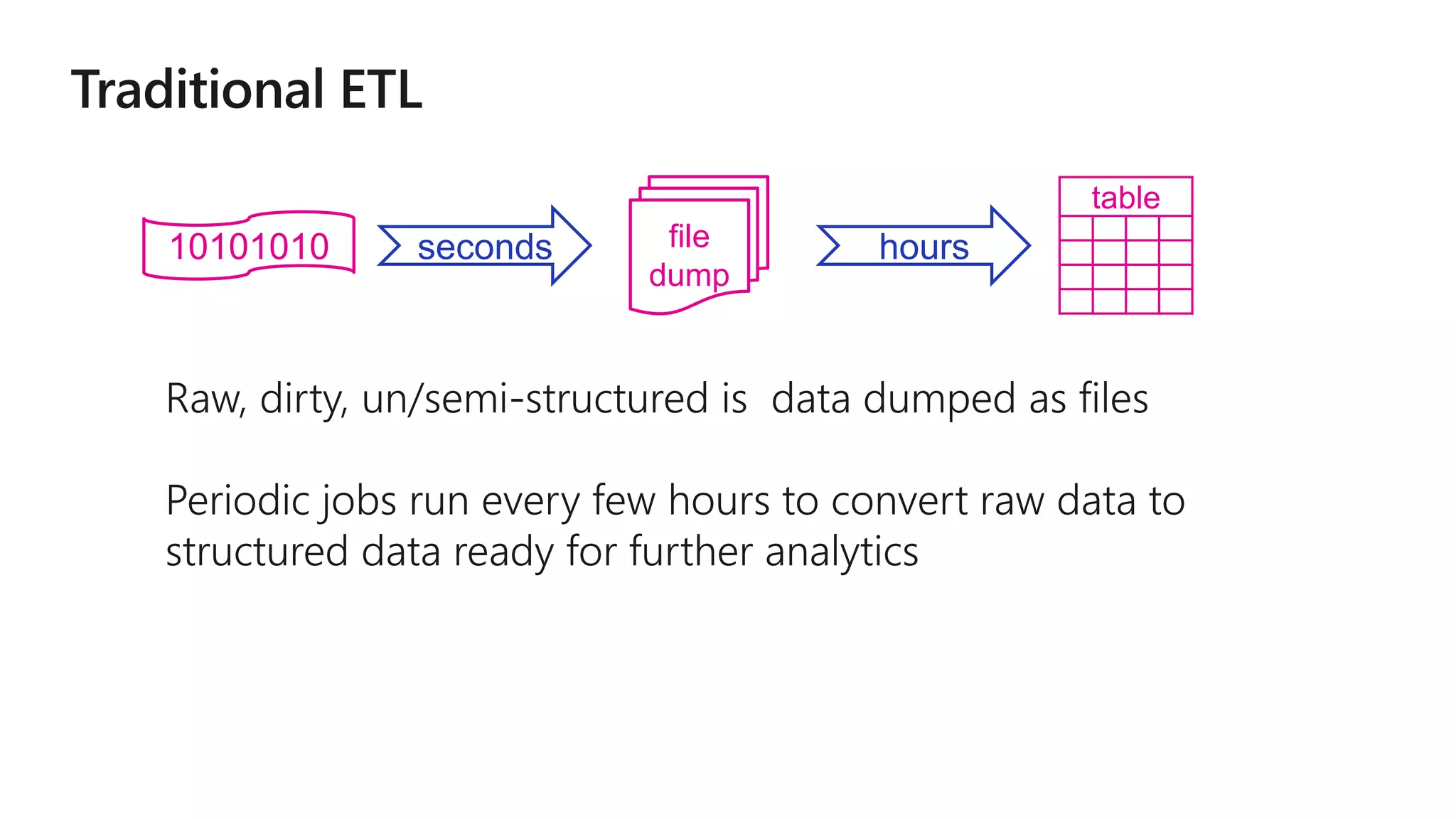
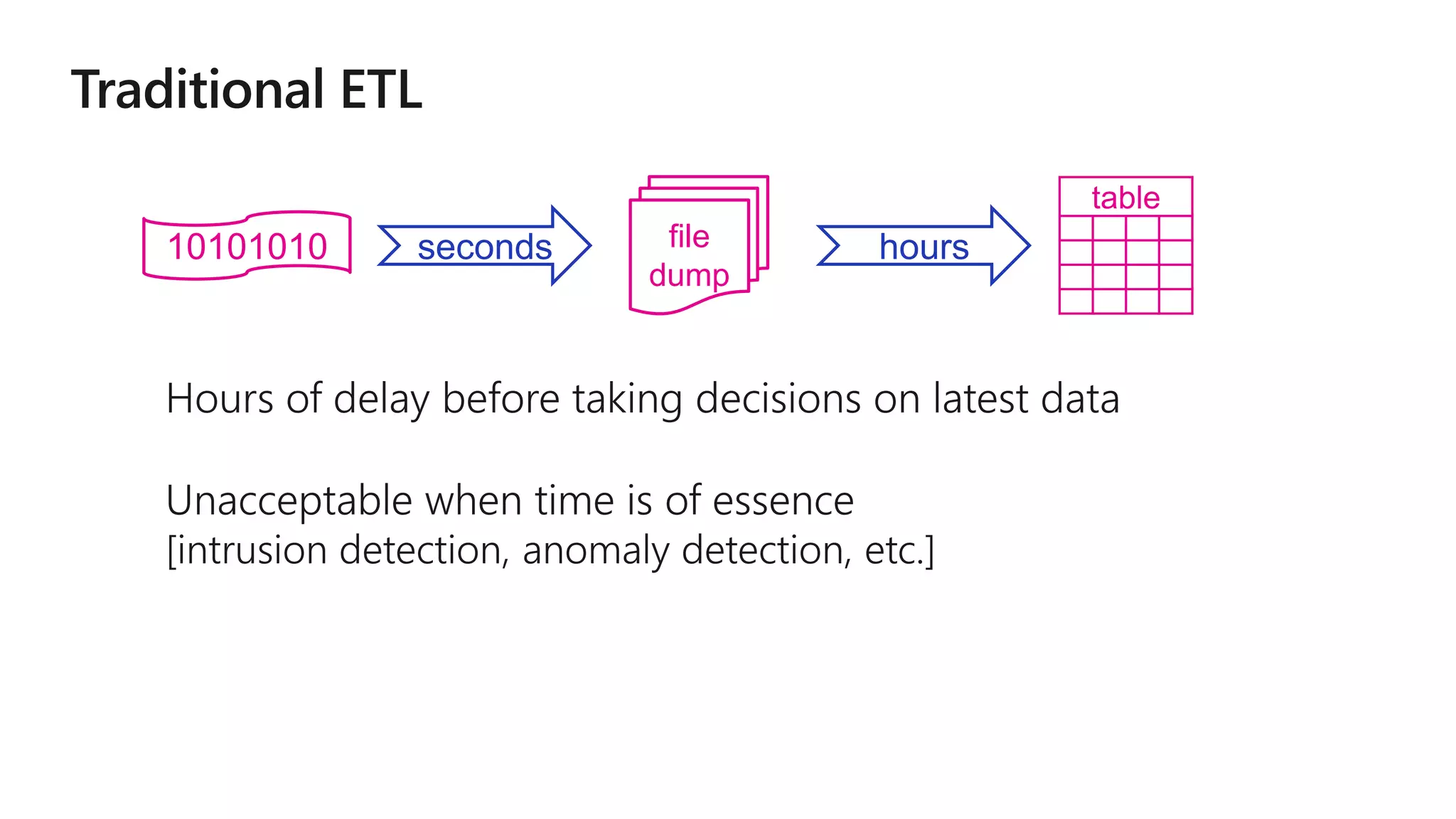
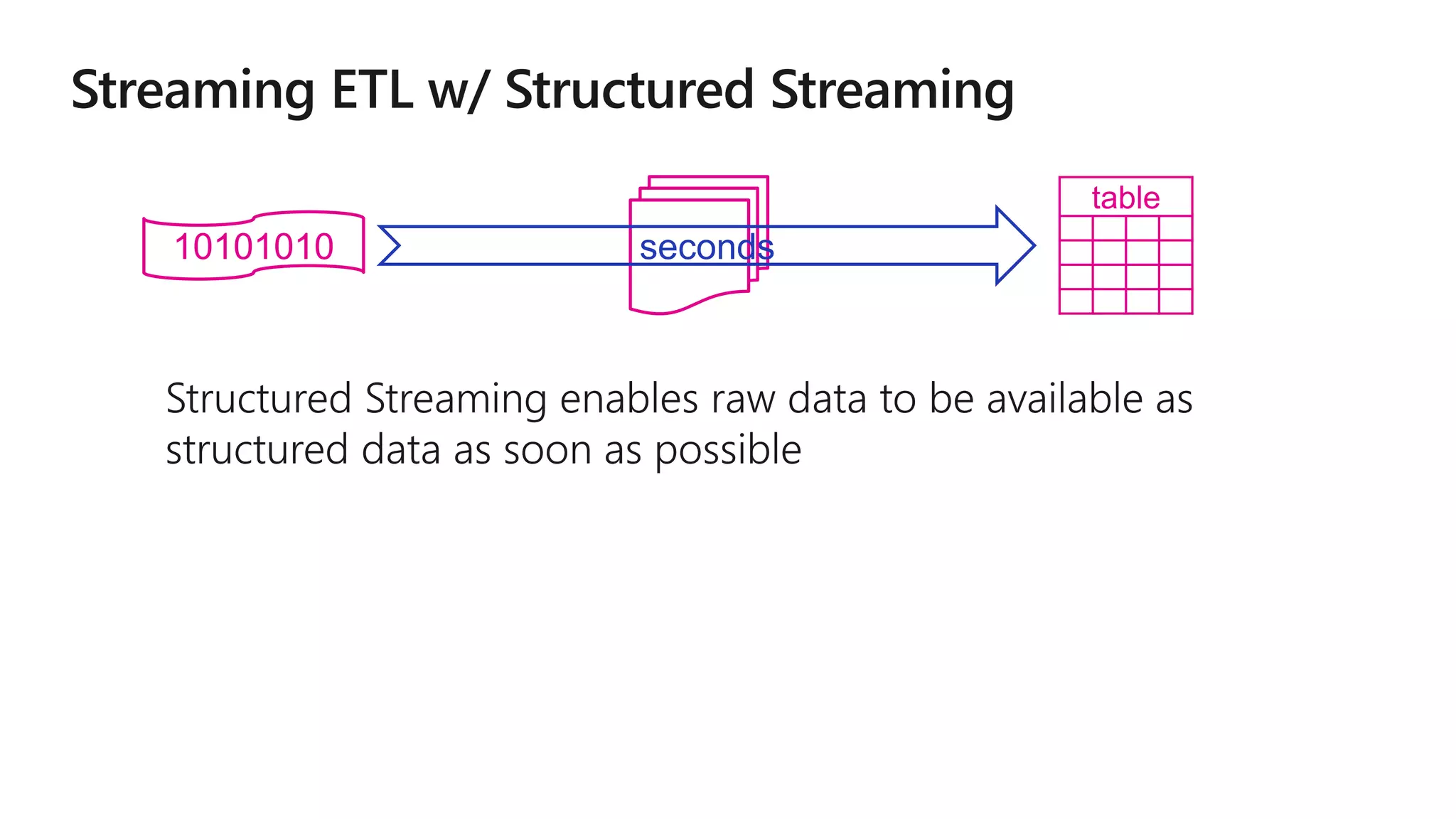
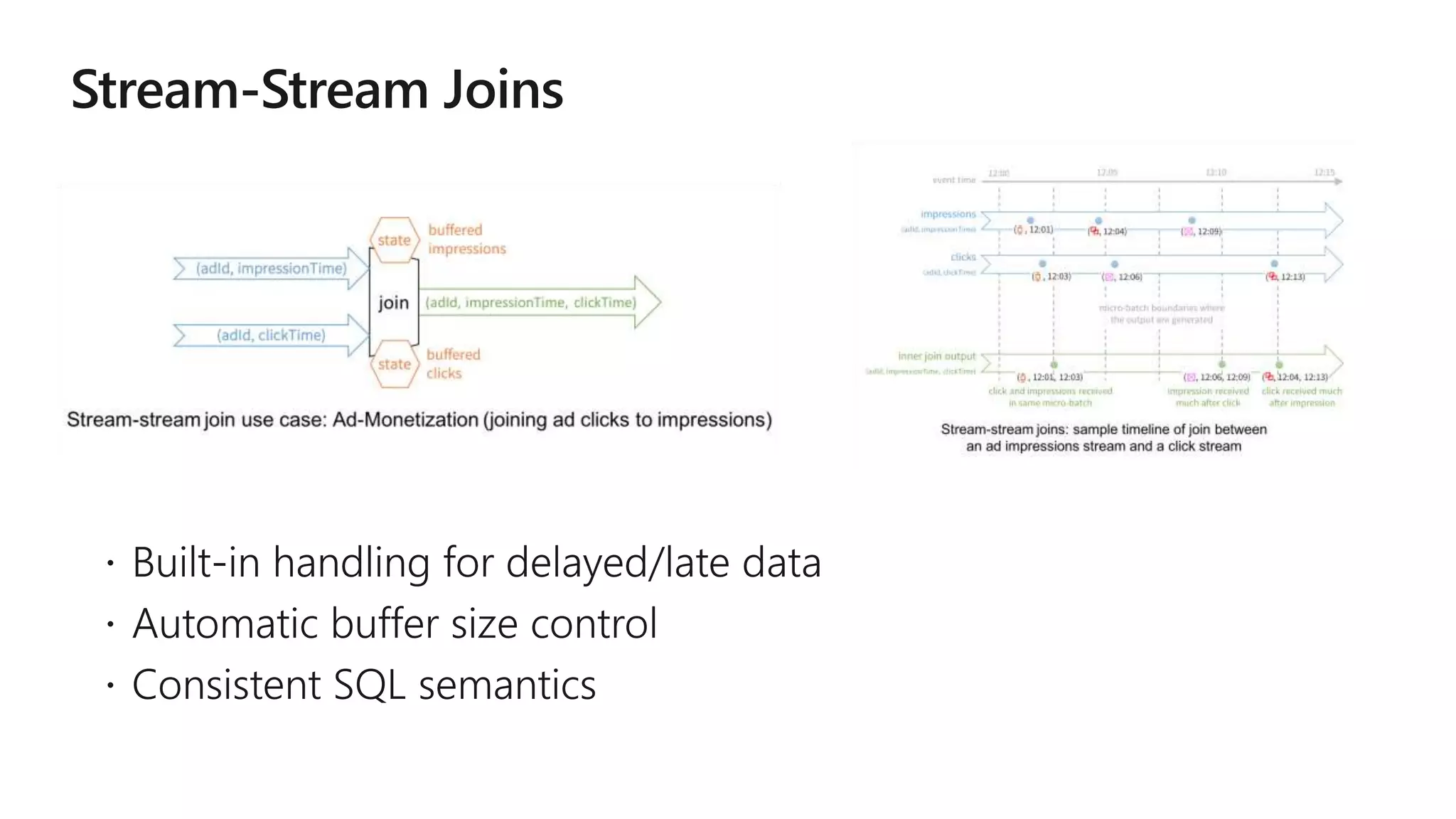
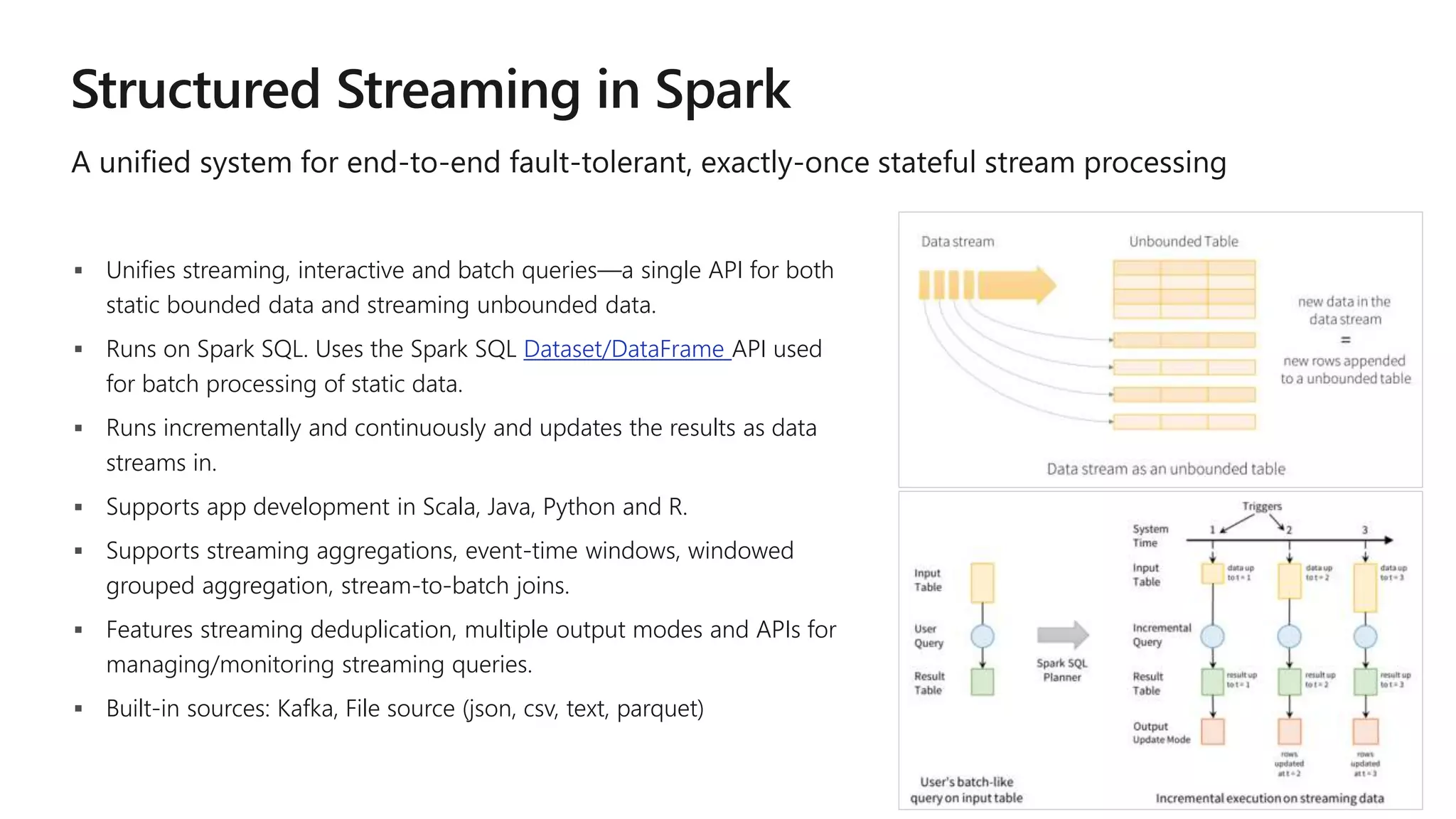
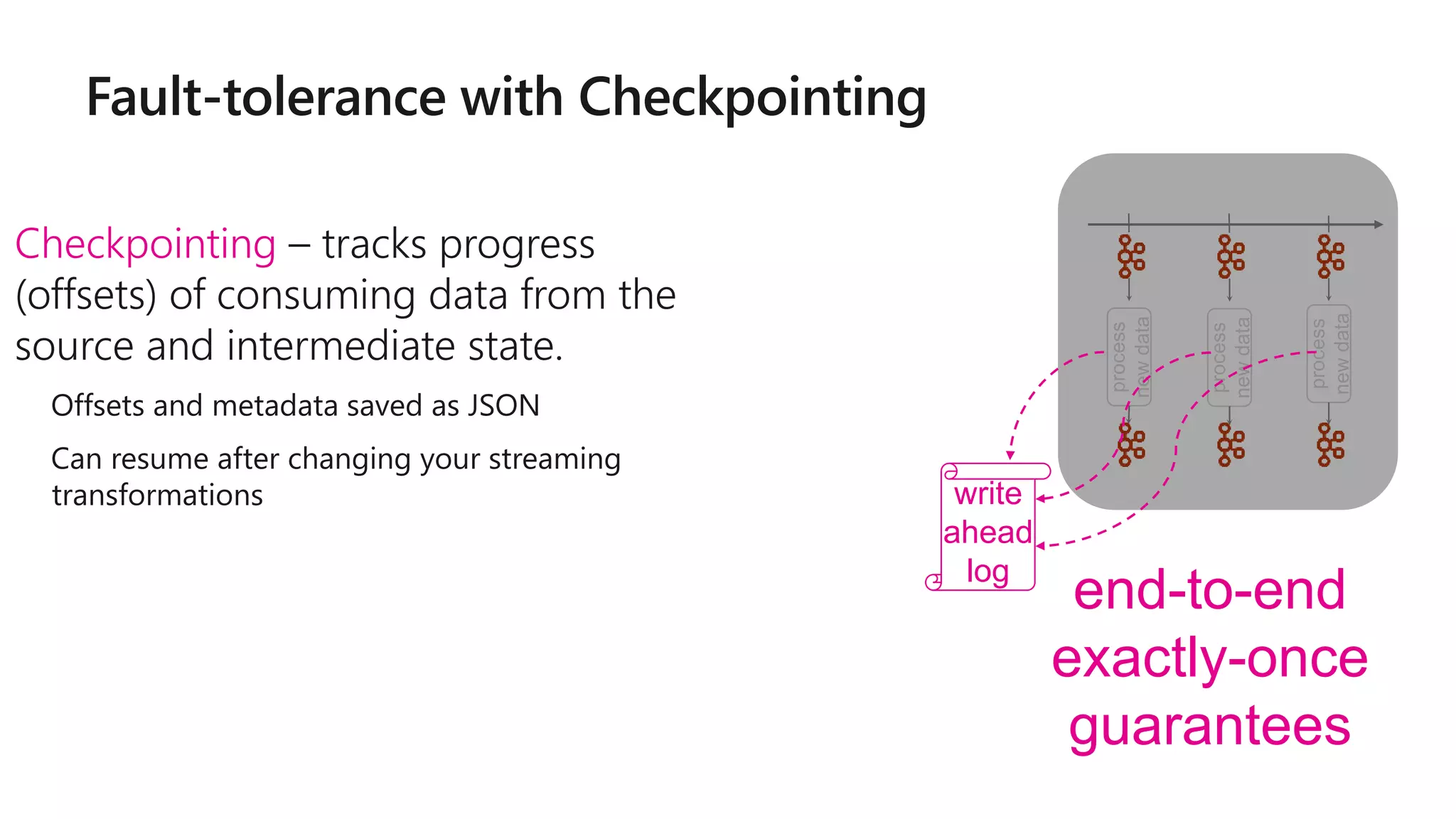
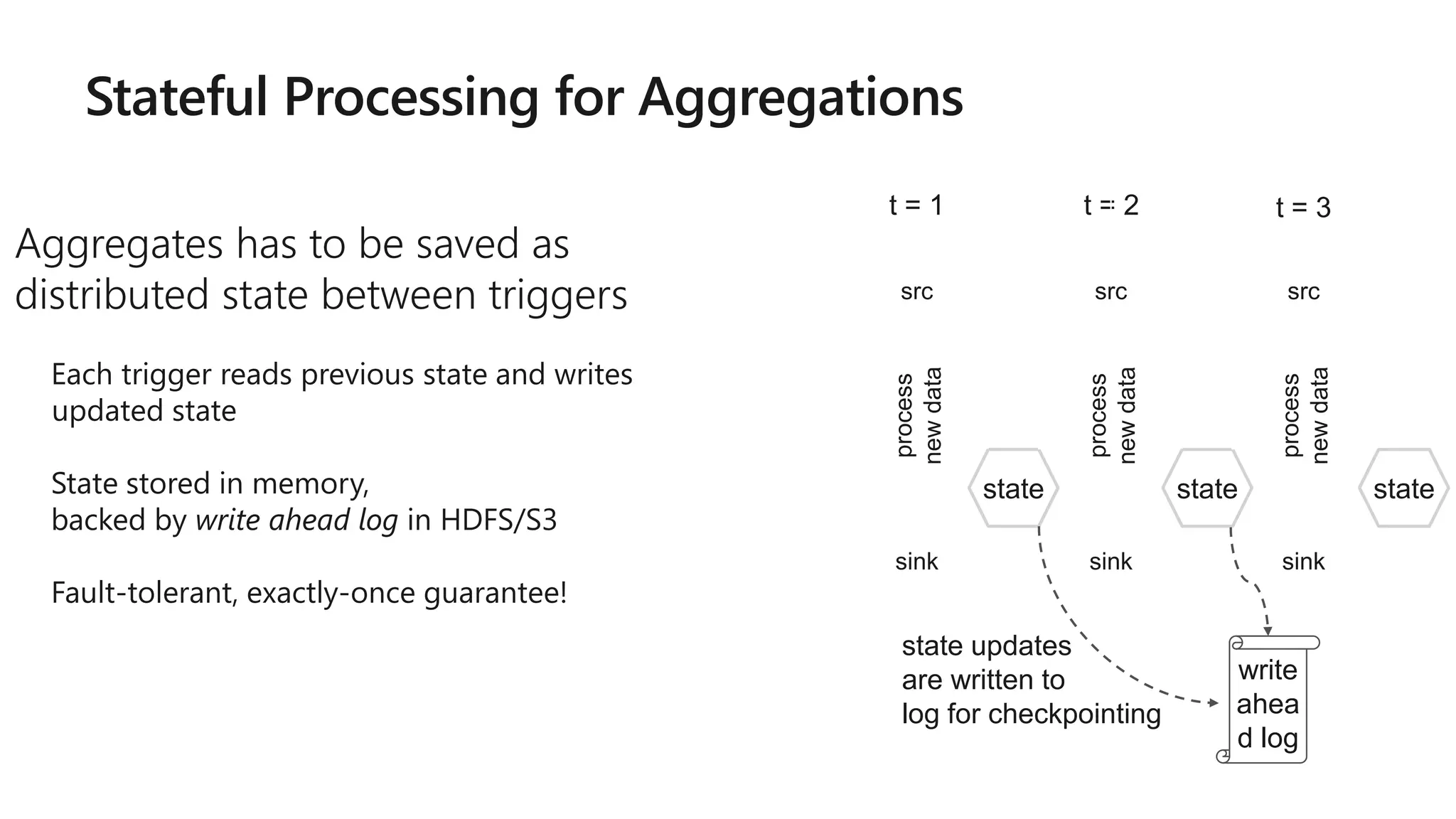
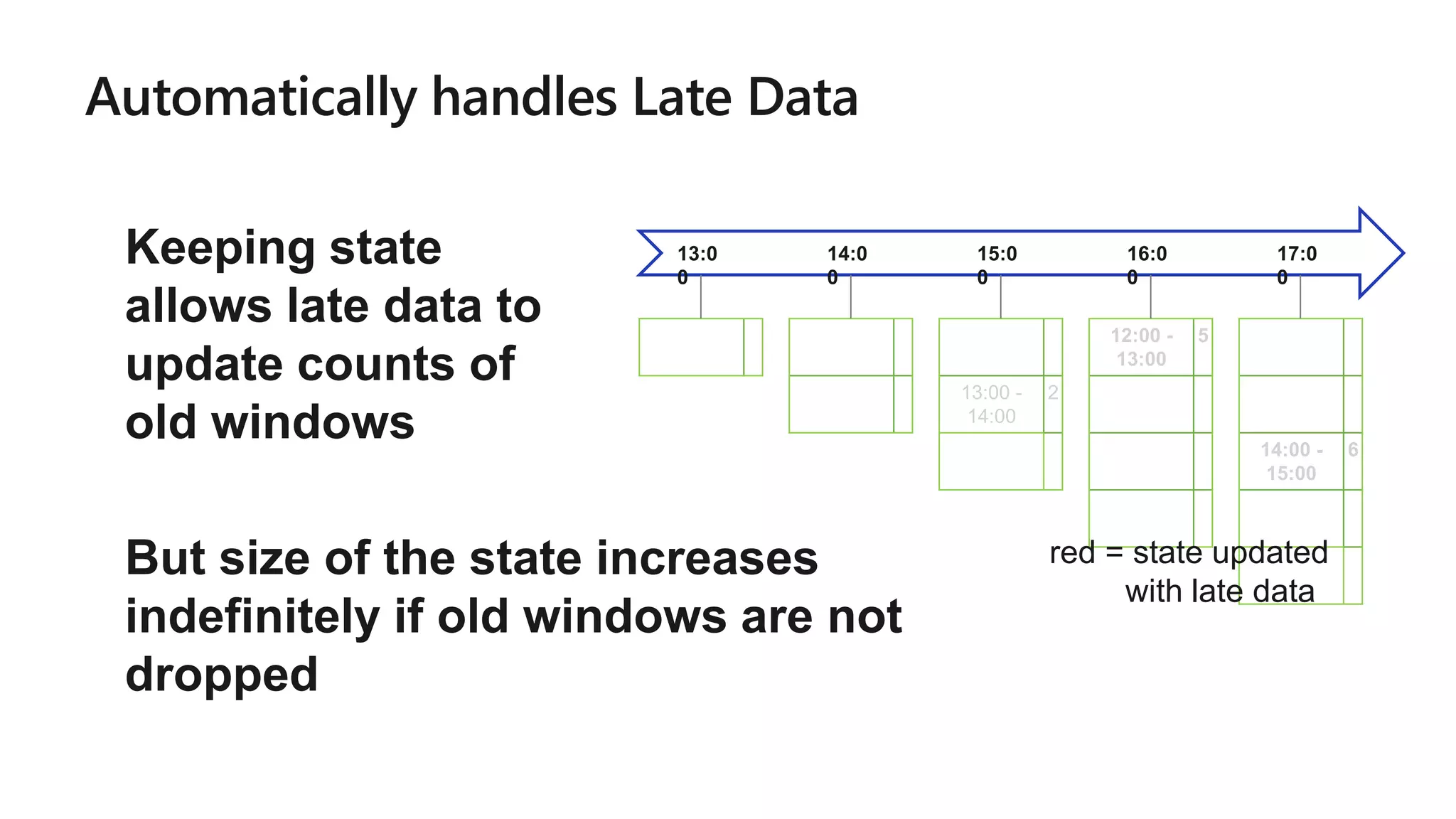
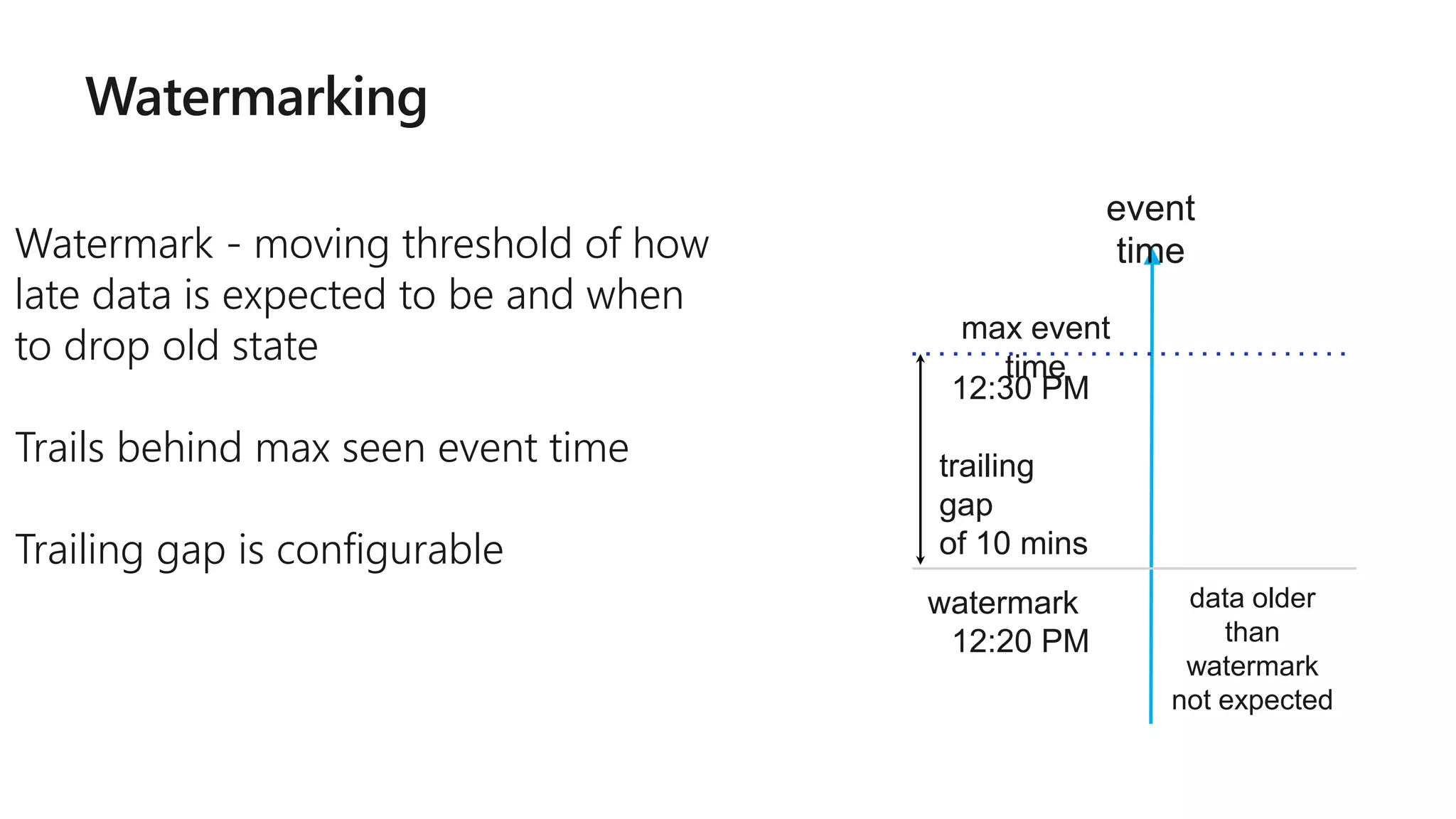
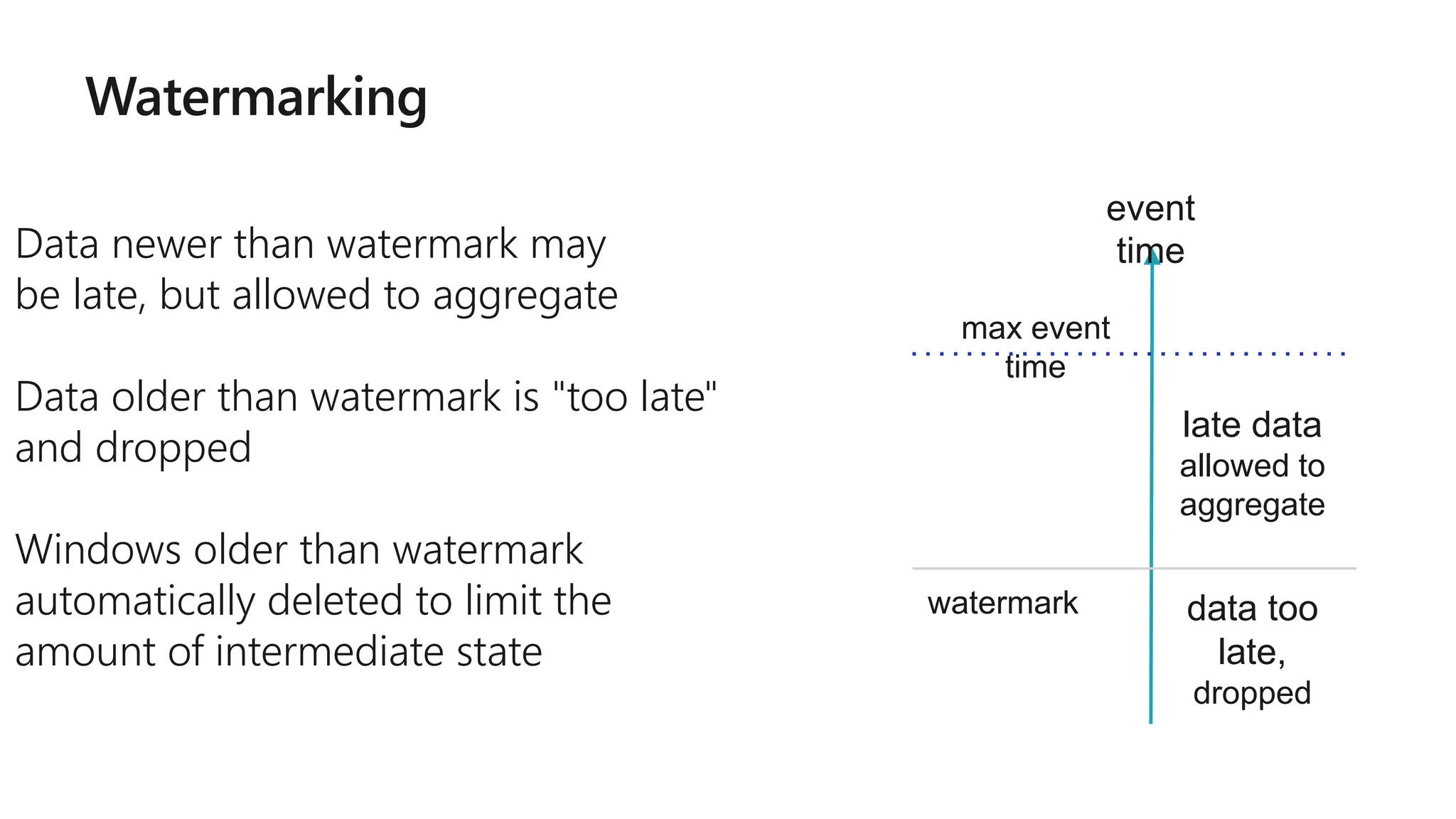
The document outlines a collaborative analytics platform based on Apache Spark optimized for Azure, specifically Databricks, featuring streamlined workflows for data scientists and analysts. It emphasizes integration with various Azure services and capabilities for real-time data processing, including event-time processing and exactly-once guarantees. The platform's advanced functionalities include support for complex queries, stateful processing, and built-in support for diverse data formats and sources.



























![Specify options to configure
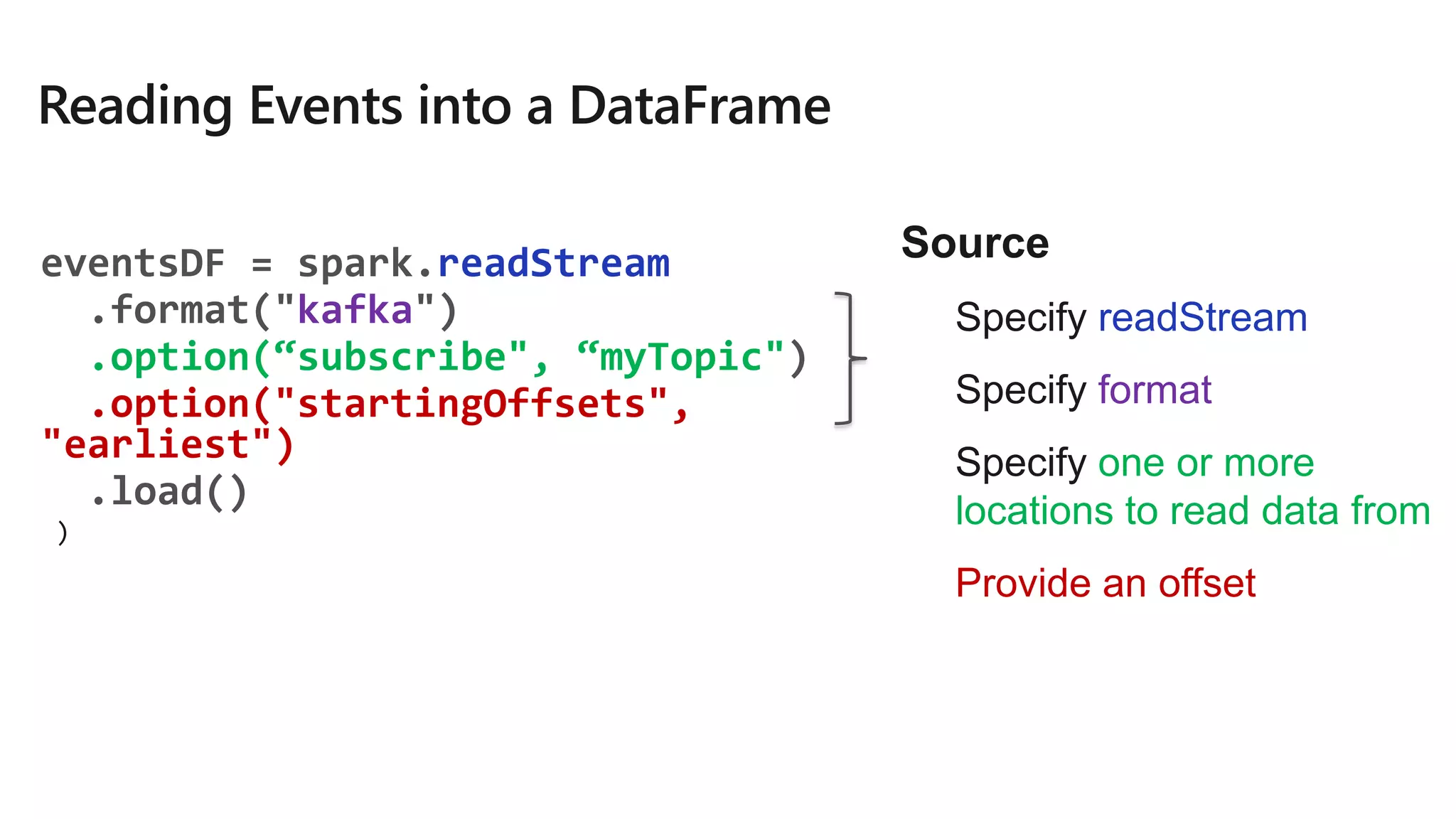
How?
kafka.boostrap.servers => broker1,broker2
What?
subscribe => topic1,topic2,topic3 // fixed list of topics
subscribePattern => topic* // dynamic list of topics
assign => {"topicA":[0,1] } // specific partitions
Where?
startingOffsets => latest(default) / earliest / {"topicA":{"0":23,"1":345} }
val rawData = spark.readStream
.format("kafka")
.option("kafka.boostrap.servers",...
)
.option("subscribe", "topic")
.load()](https://image.slidesharecdn.com/brk3314-180515233724/75/Leveraging-Azure-Databricks-to-minimize-time-to-insight-by-combining-Batch-and-Stream-processing-pipelines-49-2048.jpg)
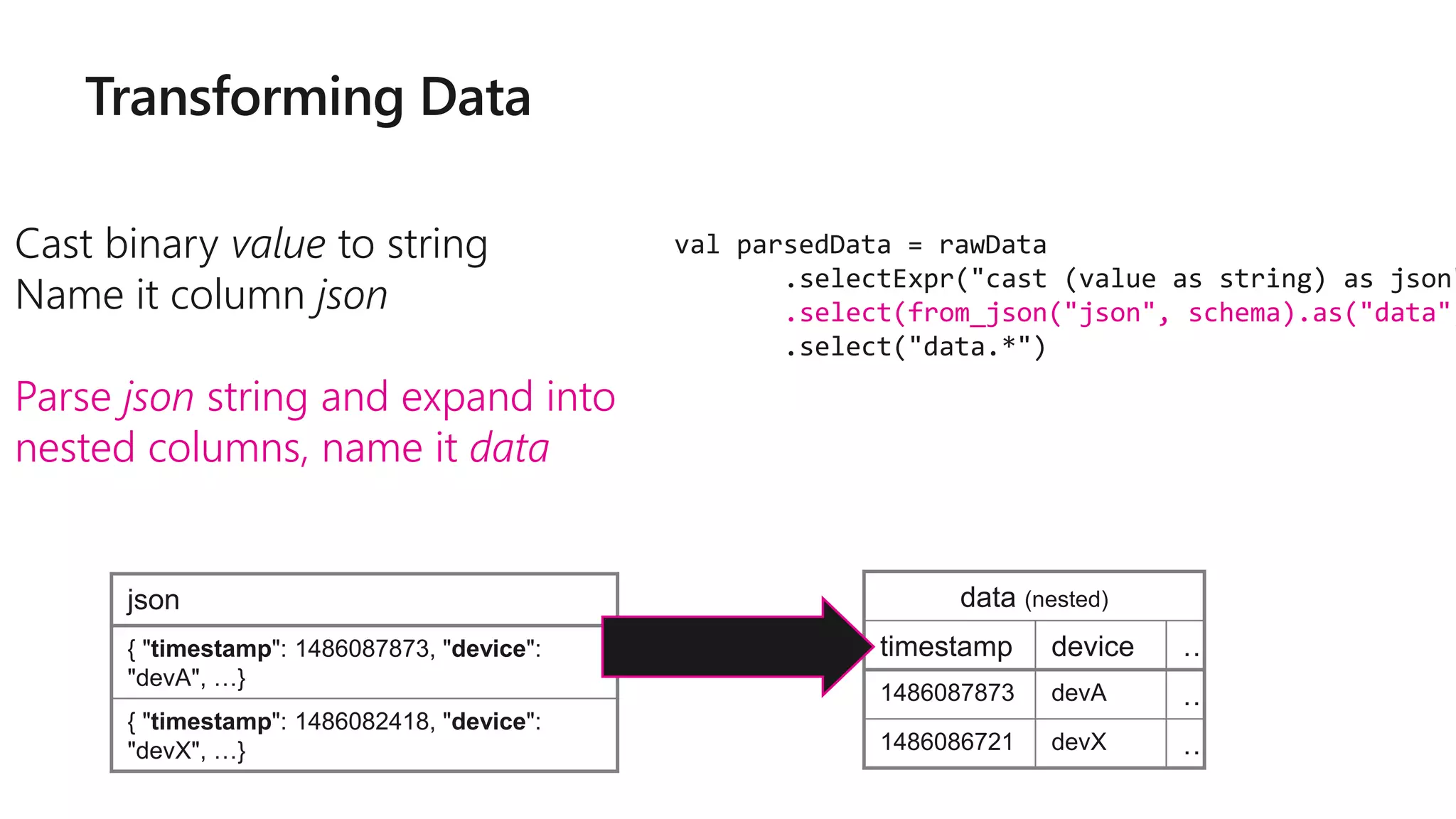
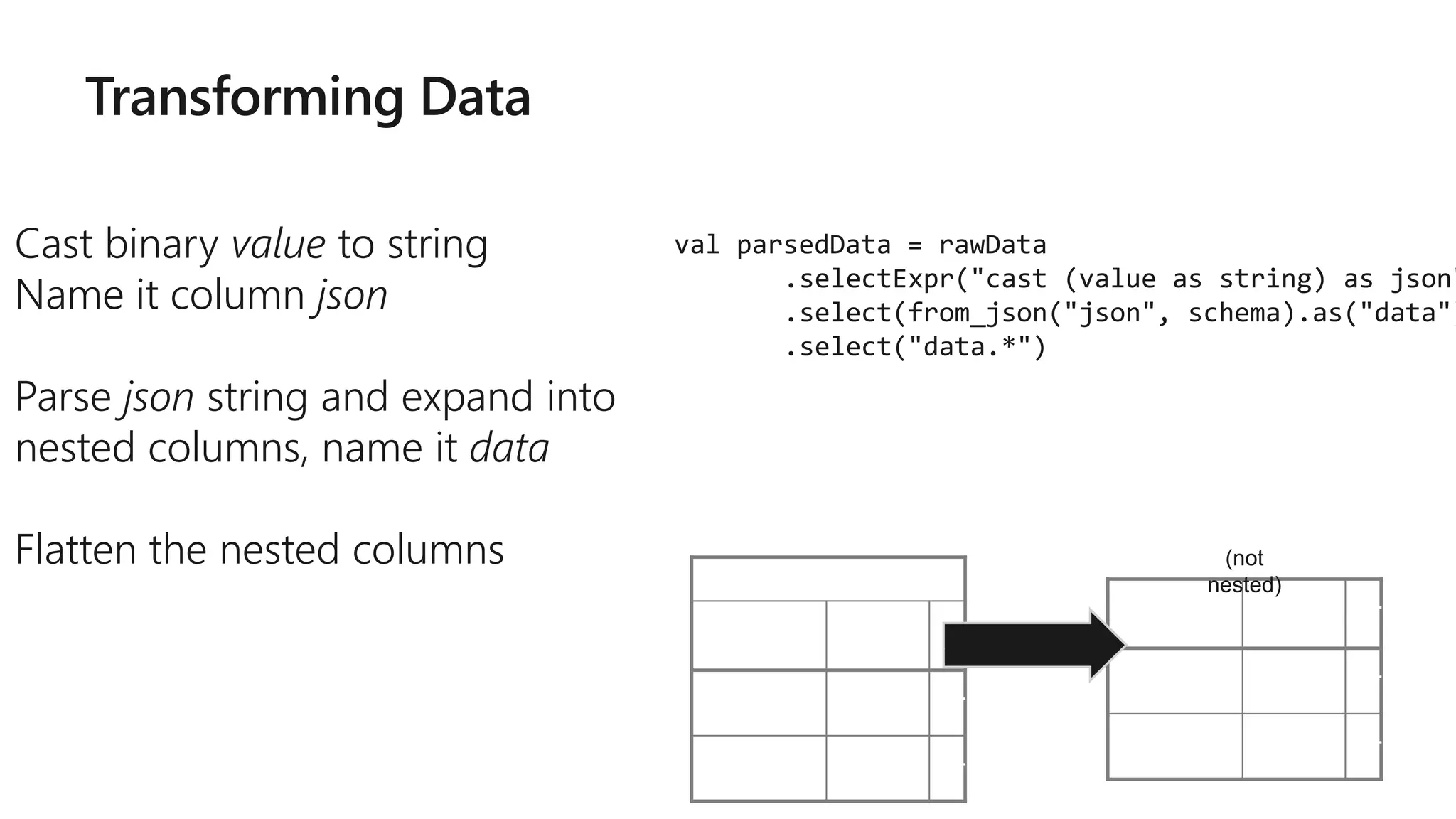
![rawData dataframe has the
following columns
val rawData = spark.readStream
.format("kafka")
.option("kafka.boostrap.servers",...
)
.option("subscribe", "topic")
.load()
key value topic partitio
n
offset timestamp
[binary] [binary] "topicA" 0 345 1486087873
[binary] [binary] "topicB" 3 2890 1486086721](https://image.slidesharecdn.com/brk3314-180515233724/75/Leveraging-Azure-Databricks-to-minimize-time-to-insight-by-combining-Batch-and-Stream-processing-pipelines-50-2048.jpg)




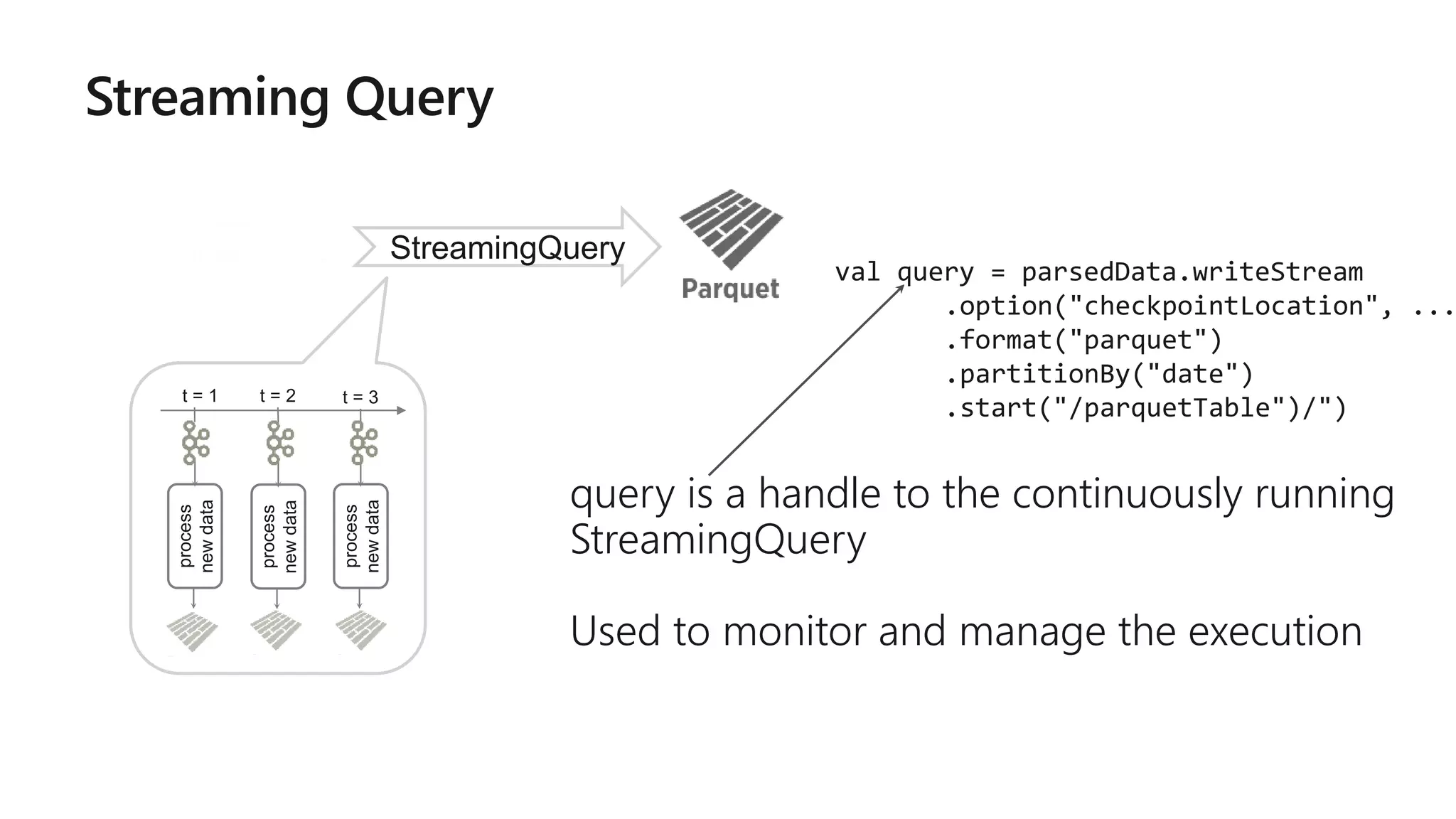

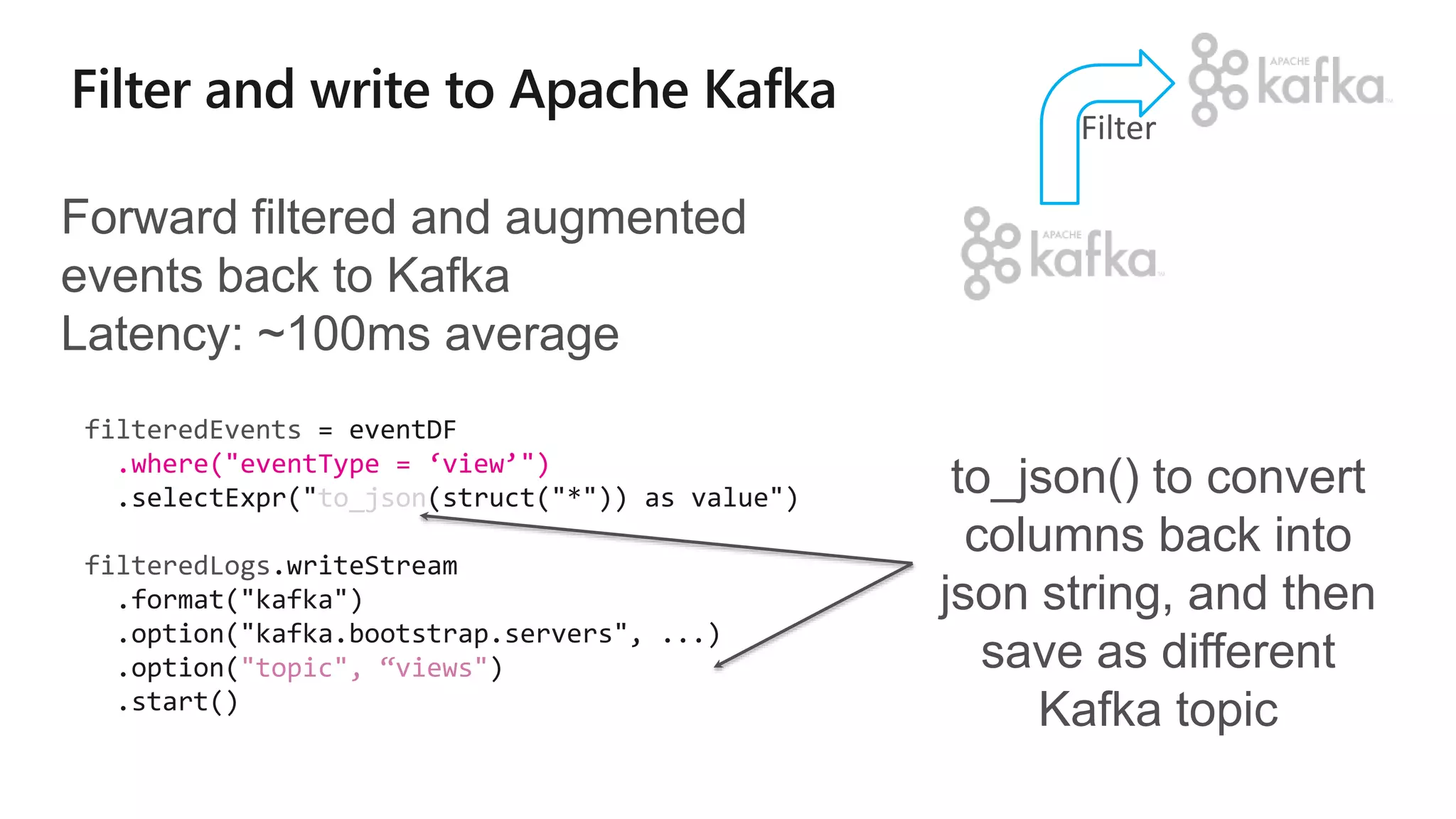
![More Kafka Support [Spark 2.2]
Write out to Kafka
Dataframe must have binary fields named
key and value
Direct, interactive and batch
queries on Kafka
Makes Kafka even more powerful as a
storage platform!
result.writeStream
.format("kafka")
.option("topic", "output")
.start()
val df = spark
.read // not readStream
.format("kafka")
.option("subscribe", "topic")
.load()
df.registerTempTable("topicData")
spark.sql("select value from topicData")](https://image.slidesharecdn.com/brk3314-180515233724/75/Leveraging-Azure-Databricks-to-minimize-time-to-insight-by-combining-Batch-and-Stream-processing-pipelines-59-2048.jpg)




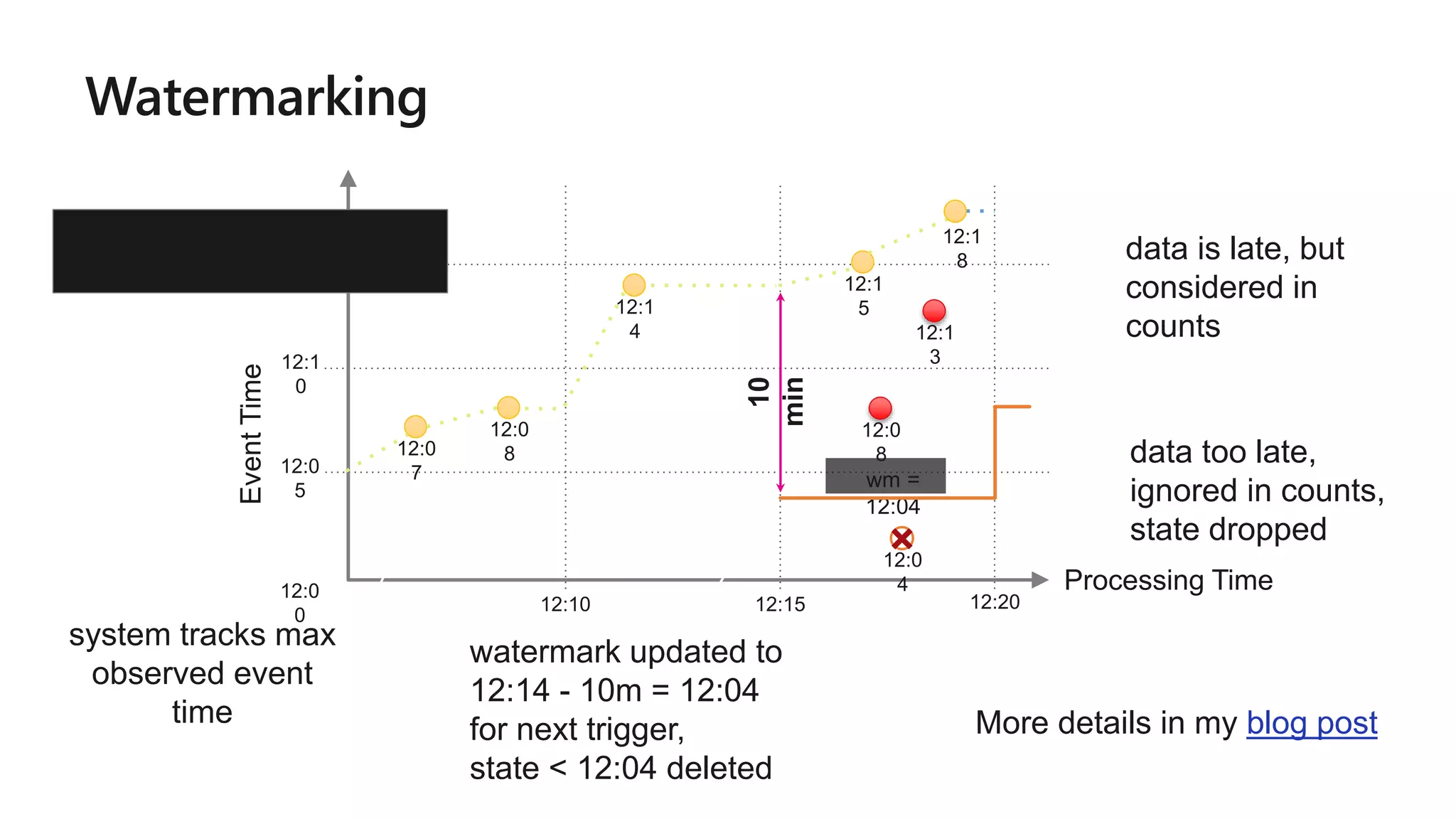




![Arbitrary Stateful Operations [Spark 2.2]
mapGroupsWithState
allows any user-defined
stateful function to a
user-defined state
Direct support for per-key
timeouts in event-time or
processing-time
Supports Scala and Java
73
ds.groupByKey(_.id)
.mapGroupsWithState
(timeoutConf)
(mappingWithStateFunc)
def mappingWithStateFunc(
key: K,
values: Iterator[V],
state: GroupState[S]): U = {
// update or remove state
// set timeouts
// return mapped value
}](https://image.slidesharecdn.com/brk3314-180515233724/75/Leveraging-Azure-Databricks-to-minimize-time-to-insight-by-combining-Batch-and-Stream-processing-pipelines-73-2048.jpg)











































































![[BDD 2025 - Artificial Intelligence] Building AI Systems That Users (and Comp...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-buildingaisystemsthatusersandcompanieslove-251124030845-038f7732-thumbnail.jpg?width=640&height=640&fit=bounds)


![[BDD 2025 - Mobile Development] Mobile Engineer and Software Engineer: Are we...](https://cdn.slidesharecdn.com/ss_thumbnails/md-mobileengineerandsoftwareengineerarewestillrelevantsidiqpermana-251127010650-55224ef1-thumbnail.jpg?width=640&height=640&fit=bounds)


![[BDD 2025 - Artificial Intelligence] AI for the Underdogs: Innovation for Sma...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-aifortheunderdogsinnovationforsmallbusinesses-251124030839-72a599a4-thumbnail.jpg?width=640&height=640&fit=bounds)




![[BDD 2025 - Full-Stack Development] PHP in AI Age: The Laravel Way. (Rizqy Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-phpinaiagethelaravelway-251125012602-ef9d330e-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Mobile Development] Crafting Immersive UI with E2E and AGSL Shade...](https://cdn.slidesharecdn.com/ss_thumbnails/md-craftingimmersiveuiwithe2eandagslshaderveronicaputrianggraini-251124030840-0c677f44-thumbnail.jpg?width=640&height=640&fit=bounds)


