Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Junnosuke Toku
3,012 views
Awk勉強会用資料
Read more
7
Save
Share
Embed
Embed presentation
Download
Downloaded 38 times
1
/ 67
2
/ 67
3
/ 67
4
/ 67
5
/ 67
6
/ 67
7
/ 67
8
/ 67
9
/ 67
10
/ 67
11
/ 67
12
/ 67
13
/ 67
14
/ 67
15
/ 67
16
/ 67
17
/ 67
18
/ 67
19
/ 67
20
/ 67
21
/ 67
22
/ 67
23
/ 67
24
/ 67
25
/ 67
26
/ 67
27
/ 67
28
/ 67
29
/ 67
30
/ 67
31
/ 67
32
/ 67
33
/ 67
34
/ 67
35
/ 67
36
/ 67
37
/ 67
38
/ 67
39
/ 67
40
/ 67
41
/ 67
42
/ 67
43
/ 67
44
/ 67
45
/ 67
46
/ 67
47
/ 67
48
/ 67
49
/ 67
50
/ 67
51
/ 67
52
/ 67
53
/ 67
54
/ 67
55
/ 67
56
/ 67
57
/ 67
58
/ 67
59
/ 67
60
/ 67
61
/ 67
62
/ 67
63
/ 67
64
/ 67
65
/ 67
66
/ 67
67
/ 67
More Related Content
PDF
What's new in Spring Batch 5
by
ikeyat
PDF
JDKの選択肢とサーバーサイドでの選び方
by
Takahiro YAMADA
PDF
Django の認証処理実装パターン / Django Authentication Patterns
by
Masashi Shibata
PDF
2017 red hat open stack(rhosp) function overview (samuel,2017-0516)
by
SAMUEL SJ Cheon
PPTX
Mail Merge.pptx
by
Ankita Shirke
PPTX
お絵かきのお話(~nw構成図ってどんな感じで書いてます?~)
by
Tatsuya Maruno
PPT
Spring3.1概要 データアクセスとトランザクション処理
by
土岐 孝平
PDF
そろそろRStudioの話
by
Kazuya Wada
What's new in Spring Batch 5
by
ikeyat
JDKの選択肢とサーバーサイドでの選び方
by
Takahiro YAMADA
Django の認証処理実装パターン / Django Authentication Patterns
by
Masashi Shibata
2017 red hat open stack(rhosp) function overview (samuel,2017-0516)
by
SAMUEL SJ Cheon
Mail Merge.pptx
by
Ankita Shirke
お絵かきのお話(~nw構成図ってどんな感じで書いてます?~)
by
Tatsuya Maruno
Spring3.1概要 データアクセスとトランザクション処理
by
土岐 孝平
そろそろRStudioの話
by
Kazuya Wada
What's hot
PPTX
大量のデータ処理や分析に使えるOSS Apache Sparkのご紹介(Open Source Conference 2020 Online/Kyoto ...
by
NTT DATA Technology & Innovation
PDF
Quarkus入門
by
Norito Agetsuma
PPTX
iostat await svctm の 見かた、考え方
by
歩 柴田
PDF
Svelte JS introduction
by
Mikhail Kuznetcov
PDF
pg_hint_planを知る(第37回PostgreSQLアンカンファレンス@オンライン 発表資料)
by
NTT DATA Technology & Innovation
PDF
Apiドキュメンテーションツールを使いこなす【api blueprint編】
by
dcubeio
PPTX
お手持ちのデータを最高速度で安全に転送してみよう
by
MurataNoriaki1
PDF
Data Engineering with Solr and Spark
by
Lucidworks
PPTX
SQLチューニング入門 入門編
by
Miki Shimogai
PDF
Cours : les listes chainées Prof. KHALIFA MANSOURI
by
Mansouri Khalifa
KEY
Given When Then
by
Richard Green
PPTX
Big data architectures
by
Mariem Khalfaoui
ODP
Highcharts
by
Knoldus Inc.
PPT
Oscon keynote: Working hard to keep it simple
by
Martin Odersky
PDF
並列データベースシステムの概念と原理
by
Makoto Yui
PDF
PostgreSQL - C言語によるユーザ定義関数の作り方
by
Satoshi Nagayasu
PPTX
Introduction à JavaScript
by
Abdoulaye Dieng
PDF
カスタムプランと汎用プラン
by
Masao Fujii
PPT
Test
by
skri_zakariya
PPTX
Découverte de Redis
by
JEMLI Fathi
大量のデータ処理や分析に使えるOSS Apache Sparkのご紹介(Open Source Conference 2020 Online/Kyoto ...
by
NTT DATA Technology & Innovation
Quarkus入門
by
Norito Agetsuma
iostat await svctm の 見かた、考え方
by
歩 柴田
Svelte JS introduction
by
Mikhail Kuznetcov
pg_hint_planを知る(第37回PostgreSQLアンカンファレンス@オンライン 発表資料)
by
NTT DATA Technology & Innovation
Apiドキュメンテーションツールを使いこなす【api blueprint編】
by
dcubeio
お手持ちのデータを最高速度で安全に転送してみよう
by
MurataNoriaki1
Data Engineering with Solr and Spark
by
Lucidworks
SQLチューニング入門 入門編
by
Miki Shimogai
Cours : les listes chainées Prof. KHALIFA MANSOURI
by
Mansouri Khalifa
Given When Then
by
Richard Green
Big data architectures
by
Mariem Khalfaoui
Highcharts
by
Knoldus Inc.
Oscon keynote: Working hard to keep it simple
by
Martin Odersky
並列データベースシステムの概念と原理
by
Makoto Yui
PostgreSQL - C言語によるユーザ定義関数の作り方
by
Satoshi Nagayasu
Introduction à JavaScript
by
Abdoulaye Dieng
カスタムプランと汎用プラン
by
Masao Fujii
Test
by
skri_zakariya
Découverte de Redis
by
JEMLI Fathi
Similar to Awk勉強会用資料
PDF
GNU awk (gawk) を用いた Apache ログ解析方法
by
博文 斉藤
PDF
シェル芸初心者によるシェル芸入門 (修正版)
by
icchy
ODP
シェルスクリプトを極める
by
bsdhack
PDF
awk v.s. bashどっちが強い?@OSC2011Tokyo
by
Ryuichi Ueda
PPTX
運用構築技術者の為のPSプログラミング第2回
by
Shigeharu Yamaoka
PDF
シェル芸初心者によるシェル芸入門
by
icchy
PPTX
Windowsでも使えるシェル
by
Tetsuya Hasegawa
PDF
Linux女子部第二回勉強会usp友の会
by
Ryuichi Ueda
PDF
スクリプト言語入門 - シェル芸のすすめ - 第2回クラウド勉強会
by
Makoto SAKAI
PPTX
シェルスクリプトワークショップ資料 - 初心者向け「シェル芸」
by
博文 斉藤
PDF
awk入門
by
ika take
PDF
Usptomonokai 20111028
by
博文 斉藤
PPTX
シェルスクリプトワークショップ資料 - 上級者向け「シェル芸」
by
博文 斉藤
PPTX
OSC・シェルのプロが語る『make を使ったデータ処理。』 【make 教】 - OSC2015 Tokyo/Spring 発表資料
by
博文 斉藤
PDF
20130223 OSC Tokyo/Spring
by
Ryuichi Ueda
PDF
Let's split text by awk command
by
Yukiya Hayashi
PDF
2012年10月27日 Hbstudy#38
by
Ryuichi Ueda
PDF
jus & USP友の会共催 シェルワンライナー勉強会@関西(第11回シェル芸勉強会)
by
Ryuichi Ueda
PDF
初見では読みづらいPerl
by
Kei Kamikawa
PPTX
ゼロからプログラミング講座(Perl) #1 @越谷 講義ノート
by
Wataru Sekiguchi
GNU awk (gawk) を用いた Apache ログ解析方法
by
博文 斉藤
シェル芸初心者によるシェル芸入門 (修正版)
by
icchy
シェルスクリプトを極める
by
bsdhack
awk v.s. bashどっちが強い?@OSC2011Tokyo
by
Ryuichi Ueda
運用構築技術者の為のPSプログラミング第2回
by
Shigeharu Yamaoka
シェル芸初心者によるシェル芸入門
by
icchy
Windowsでも使えるシェル
by
Tetsuya Hasegawa
Linux女子部第二回勉強会usp友の会
by
Ryuichi Ueda
スクリプト言語入門 - シェル芸のすすめ - 第2回クラウド勉強会
by
Makoto SAKAI
シェルスクリプトワークショップ資料 - 初心者向け「シェル芸」
by
博文 斉藤
awk入門
by
ika take
Usptomonokai 20111028
by
博文 斉藤
シェルスクリプトワークショップ資料 - 上級者向け「シェル芸」
by
博文 斉藤
OSC・シェルのプロが語る『make を使ったデータ処理。』 【make 教】 - OSC2015 Tokyo/Spring 発表資料
by
博文 斉藤
20130223 OSC Tokyo/Spring
by
Ryuichi Ueda
Let's split text by awk command
by
Yukiya Hayashi
2012年10月27日 Hbstudy#38
by
Ryuichi Ueda
jus & USP友の会共催 シェルワンライナー勉強会@関西(第11回シェル芸勉強会)
by
Ryuichi Ueda
初見では読みづらいPerl
by
Kei Kamikawa
ゼロからプログラミング講座(Perl) #1 @越谷 講義ノート
by
Wataru Sekiguchi
Awk勉強会用資料
1.
AWKでちょっとしたテキストを 処理する方法。
2.
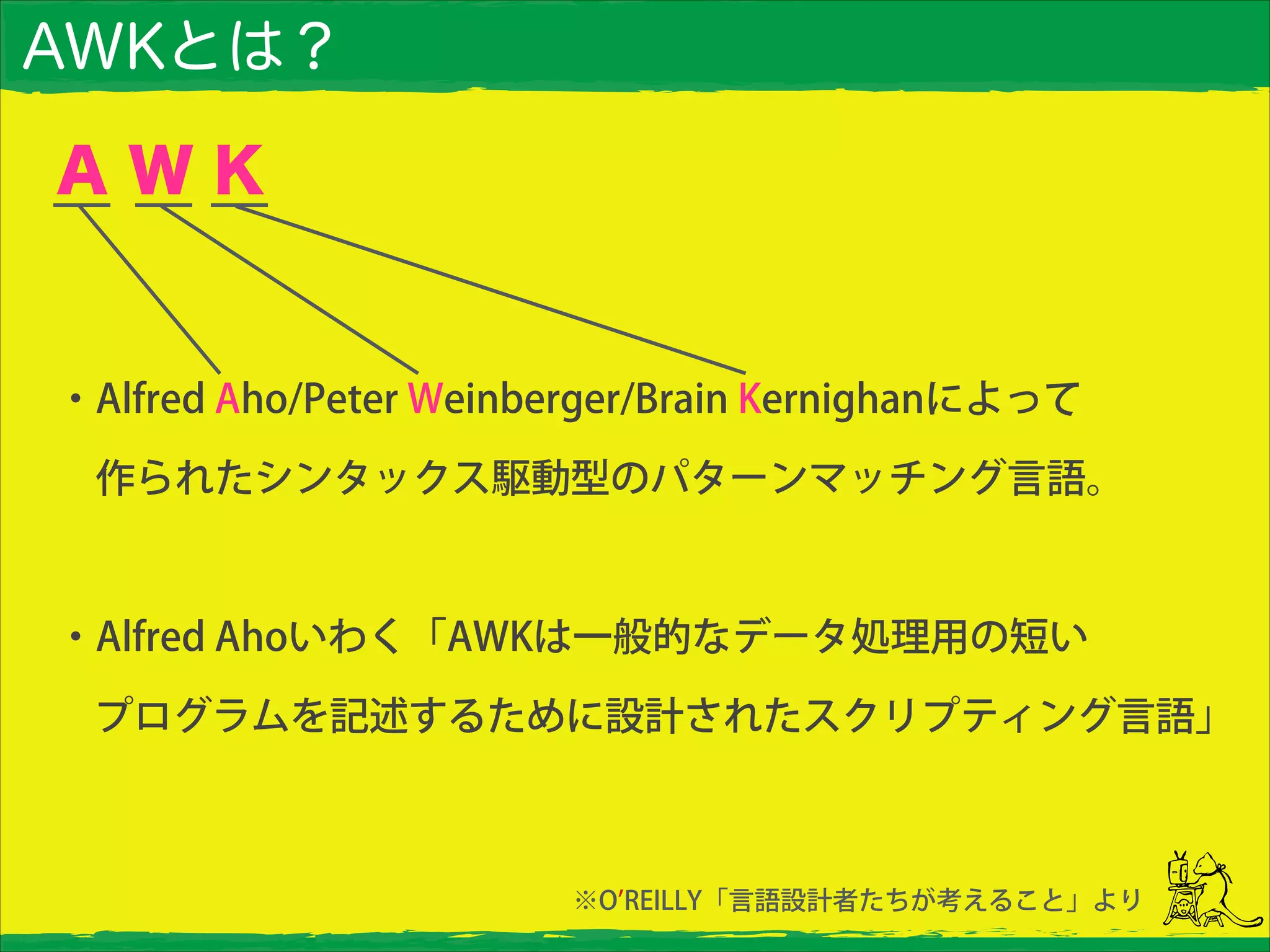
AWKとは? ・Alfred Aho/Peter Weinberger/Brain
Kernighanによって 作られたシンタックス駆動型のパターンマッチング言語。 ! ・Alfred Ahoいわく「AWKは一般的なデータ処理用の短い プログラムを記述するために設計されたスクリプティング言語」 A W K ※O REILLY「言語設計者たちが考えること」より
3.
AWKの(個人的に考える)メリット。 ・最初からテキストファイルを行xカラムに分けられる。 ! ・行に対してのパターンマッチングが行える。 ! ・学習コストが低い。
4.
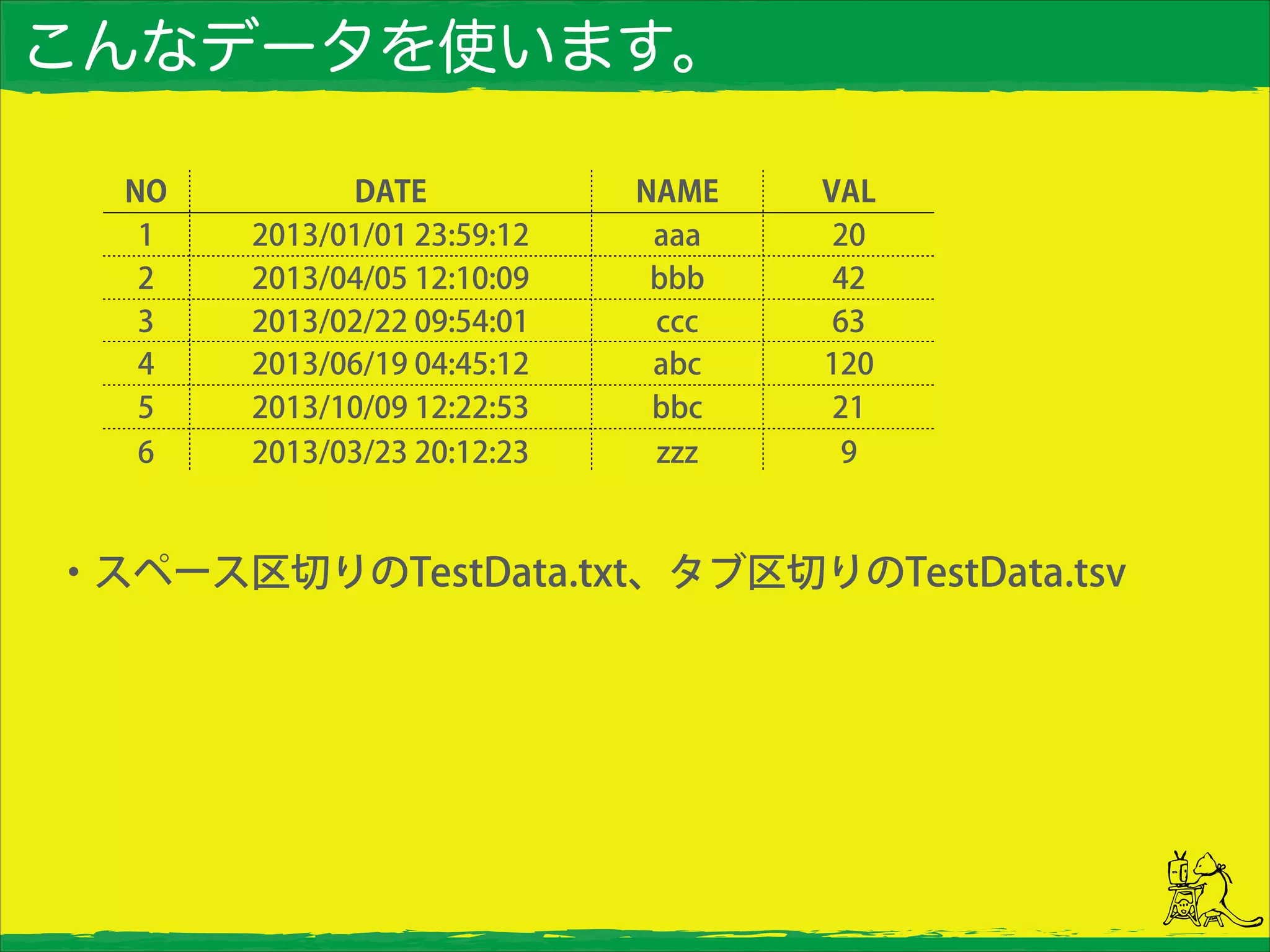
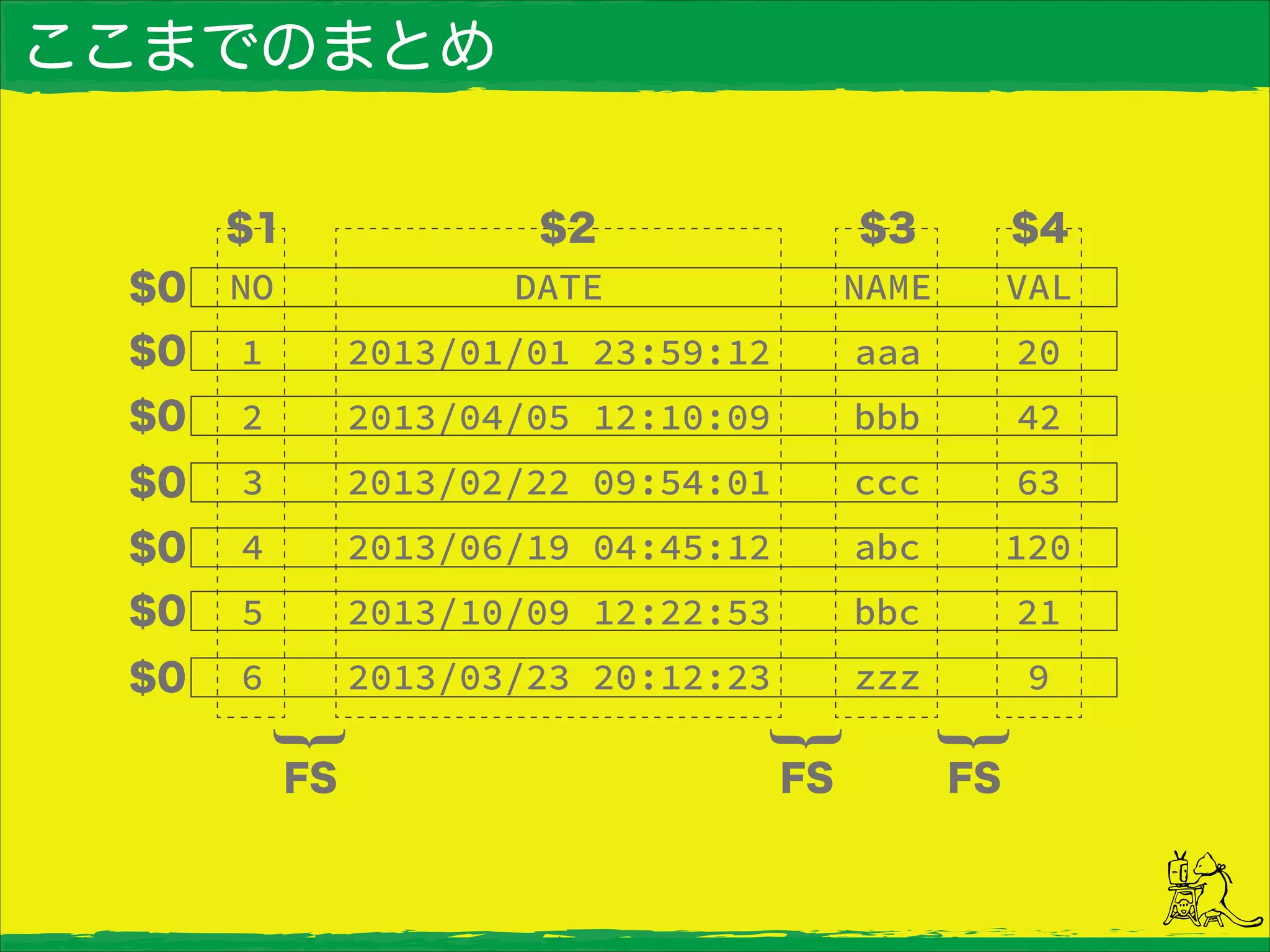
こんなデータを使います。 NO DATE NAME
VAL 1 2013/01/01 23:59:12 aaa 20 2 2013/04/05 12:10:09 bbb 42 3 2013/02/22 09:54:01 ccc 63 4 2013/06/19 04:45:12 abc 120 5 2013/10/09 12:22:53 bbc 21 6 2013/03/23 20:12:23 zzz 9 ・スペース区切りのTestData.txt、タブ区切りのTestData.tsv
5.
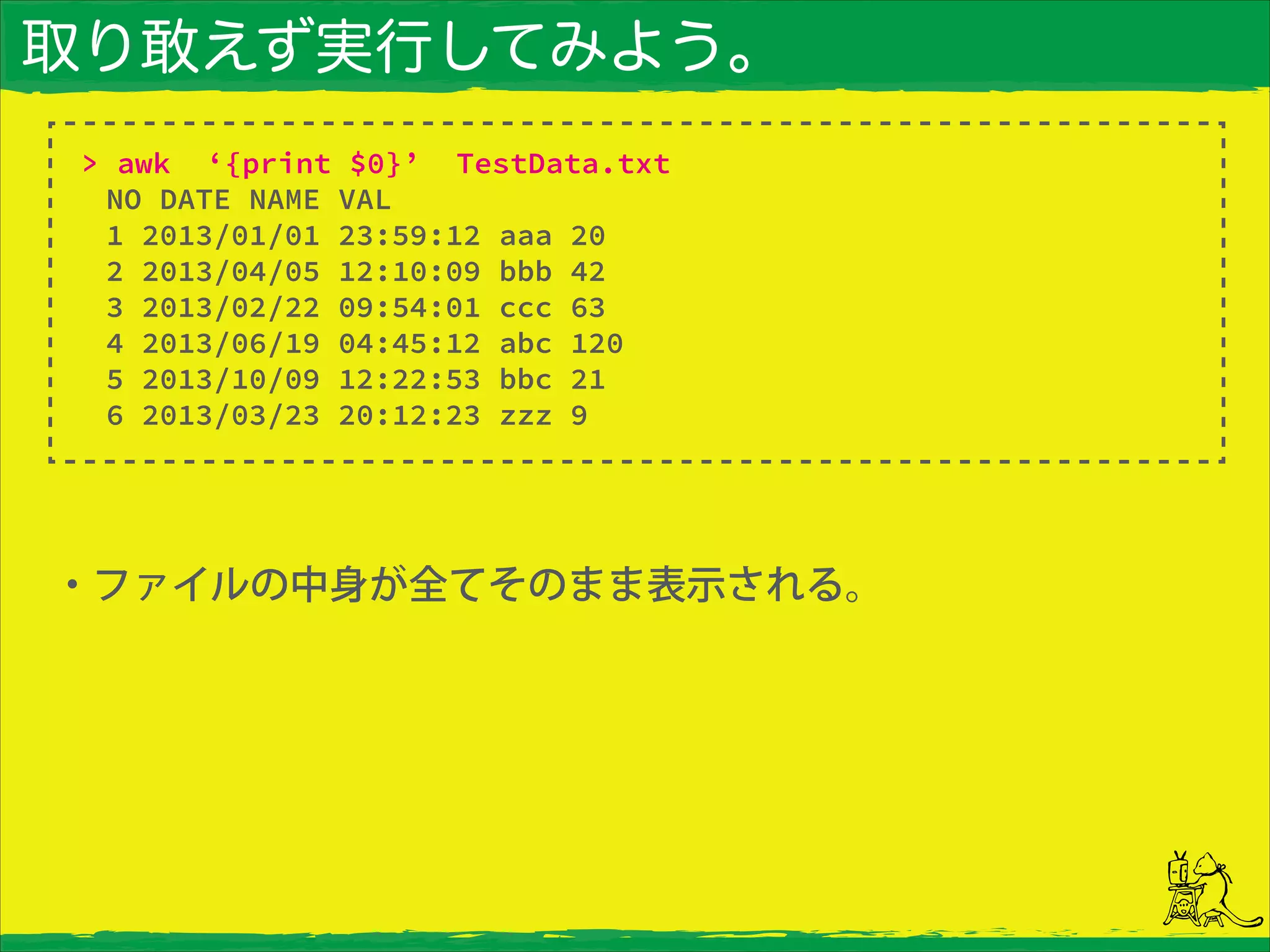
取り敢えず実行してみよう。 ・ファイルの中身が全てそのまま表示される。 > awk ‘{print
$0}’ TestData.txt NO DATE NAME VAL 1 2013/01/01 23:59:12 aaa 20 2 2013/04/05 12:10:09 bbb 42 3 2013/02/22 09:54:01 ccc 63 4 2013/06/19 04:45:12 abc 120 5 2013/10/09 12:22:53 bbc 21 6 2013/03/23 20:12:23 zzz 9
6.
AWKの構造(1) ・awkは指定されたファイルの全ての行に命令文を繰り返す。 awk ‘{print $0}’
TestData.tsv
7.
もう一度実行してみよう。 ・今度はスペース区切り2カラム目と4カラム目が表示される。 ・awkは自動的にスペース区切りでカラムを区切る。 ・$iでiカラム目を選択可能。 ・$0は全てのカラムという意味。 ・上の文はTestData.txtの2カラム目と4カラム目を表示するという命令を 全行にわたって繰り返せという意味。 >awk ‘{print $2,$4}’
TestData.txt DATE VAL 2013/01/01 aaa 2013/04/05 bbb 2013/02/22 ccc 2013/06/19 abc 2013/10/09 bbc 2013/03/23 zzz
8.
AWKの構造(2) awk ‘BEGIN{}{print $0}END{}’
TestData.tsv
9.
FSとOFS。 ・FSとOFSは特殊な変数。 ・どちらも区切り文字を指定するもの。 ・FSはインプットファイルの区切り文字。 ・OFSはアウトプットファイルの区切り文字。 ・デフォルトではどちらもスペースになっている。
10.
tsvファイルを開いてみよう。 ・BEGINの部分にFS= t を入れる事で今後行われる命令文は全て タブ区切りテキストを対象にしている事を伝えている。 ・タブ区切りテキストもちゃんと指定したカラムが表示される。 ・7枚目のスライドと結果が微妙に違う事に注意。 >
awk ‘BEGIN{FS= “t” }{print $2,$4}’ TestData.tsv DATE VAL 2013/01/01 23:59:12 20 2013/04/05 12:10:09 42 2013/02/22 09:54:01 63 2013/06/19 04:45:12 120 2013/10/09 12:22:53 21 2013/03/23 20:12:23 9
11.
tsvファイルをcsvファイルにしてみよう。 ・BEGINの部分にOFS= , を入れる事で出力されるデータが カンマ区切りになる。 ・
BEGIN{FS= t ;OFS= , }{print $0} ではどういう結果になるか試してみよう。 > awk ‘BEGIN{FS= “t” ;OFS= “,” }{print $1,$2,$3,$4}’ TestData.tsv > TestData.csv >cat TestData.csv NO,DATE,NAME,VAL 1,2013/01/01 23:59:12,aaa,20 2,2013/04/05 12:10:09,bbb,42 3,2013/02/22 09:54:01,ccc,63 4,2013/06/19 04:45:12,abc,120 5,2013/10/09 12:22:53,bbc,21 6,2013/03/23 20:12:23,zzz,9
12.
ここまでのまとめ
13.
NRとNF。 > awk ‘BEGIN{FS=
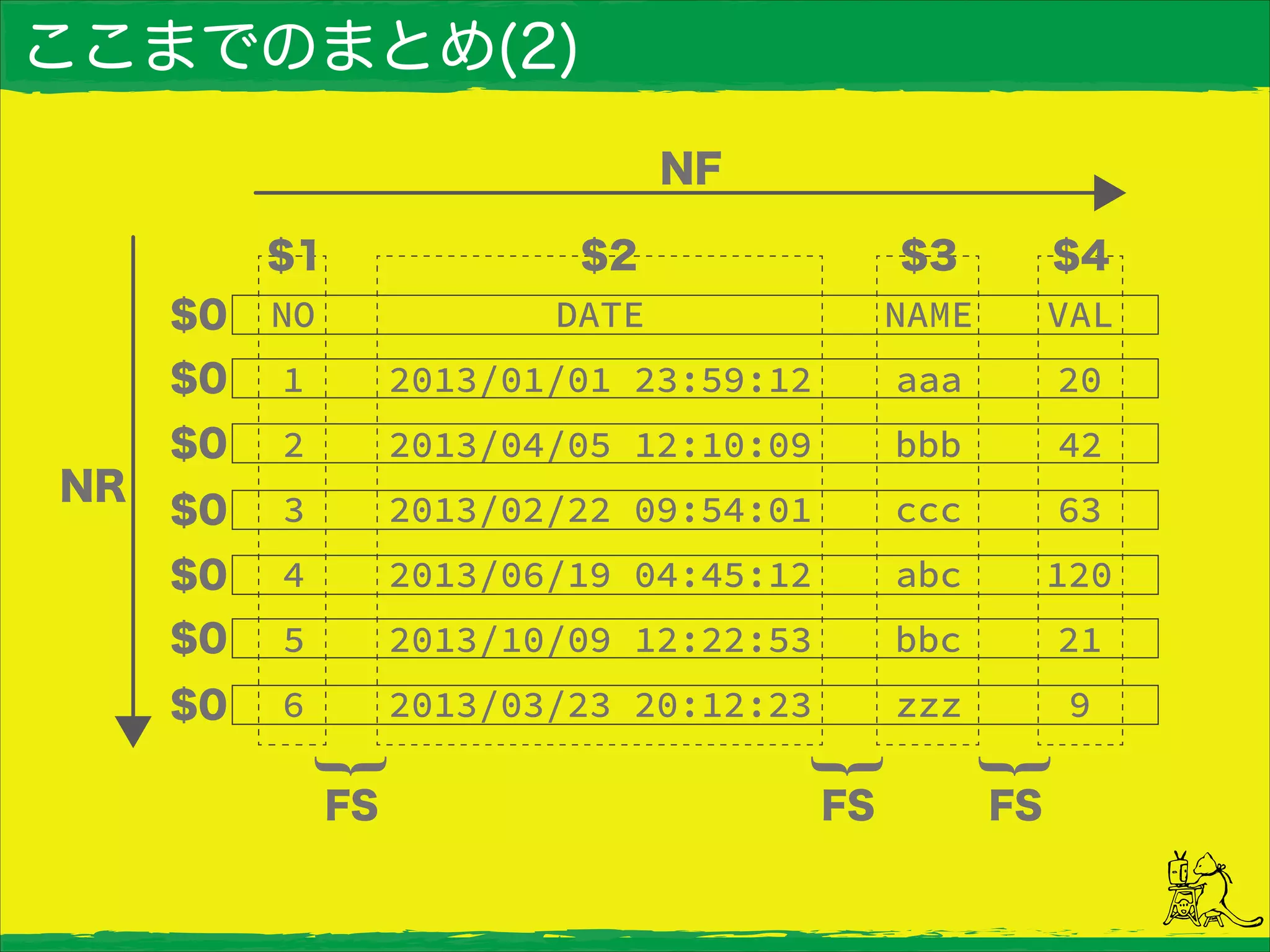
“t” }{print NR,NF,$0}’ TestData.tsv 1 4 NODATE NAME VAL 2 4 1 2013/01/01 23:59:12 aaa 20 3 4 2 2013/04/05 12:10:09 bbb 42 4 4 3 2013/02/22 09:54:01 ccc 63 5 4 4 2013/06/19 04:45:12 abc 120 6 4 5 2013/10/09 12:22:53 bbc 21 7 4 6 2013/03/23 20:12:23 zzz 9 ・NRは行番号、NFはフィールド数が格納される。
14.
ここまでのまとめ(2)
15.
AWKの構造(3) ・中括弧の前に条件式を置くことで中括弧の中の処理を行うか 判別が出来る。 awk ‘EXPR{print $0}’ 条件式
条件式が真なら実行される命令
16.
条件式を使ってみよう(1) ・「4カラム目が20以下」の行を出力する。 ・1行目と6行目は共に20以下なので出力される。 ・それ以外の行は出力されない。 >awk ‘BEGIN{FS=” t”
}$4 <= 20{print $0}’ 1 2013/01/01 23:59:12 aaa 20 6 2013/03/23 20:12:23 zzz 9
17.
条件式を使ってみよう(2) ・ //で正規表現でのマッチングが可能。 ・最初の式は「3カラム目にbが含まれている」行を出力。 ・2番目の式は「3カラム目がcで終わっている」行を出力。 >awk ‘BEGIN{FS=”
t” }$3 ~ /b/{print $0}’ 2 2013/04/05 12:10:09 bbb 42 4 2013/06/19 04:45:12 abc 120 5 2013/10/09 12:22:53 bbc 21 >awk ‘BEGIN{FS=” t” }$3 ~ /c$/{print $0}’ 3 2013/02/22 09:54:01 ccc 63 4 2013/06/19 04:45:12 abc 120 5 2013/10/09 12:22:53 bbc 21
18.
条件式を使ってみよう(3) ・&&や¦¦で複数の条件を与えることも可能。 ・最初の式は「3カラム目がcで終わっている」且つ「4カラム目が 40より大きい」行を出力。 ・2番目の式は「3カラム目がcで終わっている」或いは 「4カラム目が20以下」の行を出力。 >awk ‘BEGIN{FS=” t”
}$3 ~ /c$/ && $4 > 40{print $0}’ 3 2013/02/22 09:54:01 ccc 63 4 2013/06/19 04:45:12 abc 120 >awk ‘BEGIN{FS=” t” }$3 ~ /c$/ || $4 <= 20{print $0}’ 1 2013/01/01 23:59:12 aaa 20 3 2013/02/22 09:54:01 ccc 63 4 2013/06/19 04:45:12 abc 120 5 2013/10/09 12:22:53 bbc 21 6 2013/03/23 20:12:23 zzz 9
19.
条件式を使ってみよう(4) ・中括弧の数だけ処理が出来る。 ・上の例では$4が偶数なら even という文字列と$4を出力。 ・$4が奇数なら
uneven という文字列と$4を出力。 >awk ‘BEGIN{FS=” t” }$4%2==0{print “even” ,$4} $4%2==1{print “uneven” ,$4}’ even VAL even 20 even 42 uneven 63 even 120 uneven 21 uneven 9
20.
まとめるとこんな感じ。 BEGIN{ print “script start” } EXPR1{ print
“hoge1” $0 } EXPR2{ print “hoge2” ,$0 } { print “all” ,$0 } END{ print “script end” } 行が読まれる前に実行される。 EXPR1 が真なら実行される。 EXPR2 が真なら実行される。 全ての行で実行される。 全ての行が読み終わったら実行される。
21.
AWKの構造(4) awk -f test.awk
TestData.tsv ・-fで命令文を書いたファイルを読みこませるとプログラムを 外部ファイルにする事が出来る。
22.
合計を求めてみよう。 ・BEGINで変数を初期化、ENDで変数を出力。 ・1行目はヘッダなので合計対象から外す。 sum.awk > awk -f
sum.awk TestData.tsv 275
23.
if。 ・sum.awkに条件をひとつ追加。1カラム目が奇数の時のみ 合計対象とする。 if.awk > awk -f
if.awk TestData.tsv 104
24.
for。 for(i=1;i<=10;i++){print i} 初期化式 継続条件式 再初期化式 ・言わずと知れたループ構文。 ・iに1を代入しループを開始する。 iに1を加えながらiが10になるまでループを繰り返す。
25.
for。 ・個人的によく使うカラムチェックスクリプト。 ・forで1カラム目からNカラム目までをナンバリングして 1行ずつ出力する。 > awk -f
for.awk TestData.tsv 1:1 2:2013/01/01 23:59:12 3:aaa 4:20 for.awk
26.
split。 split(str,array,sep) 分割する文字列 分割した結果を格納する配列 区切り文字 ・文字列を分割するための命令文。 ・strに分割したい文字列を、arrayに格納したい配列を、 sepに区切り文字を入れる。
27.
split。 split.awk > awk -f
split.awk TestData.tsv NO DATE TIME NAME VAL 1 2013/01/01 23:59:12 aaa 20 2 2013/04/05 12:10:09 bbb 42 3 2013/02/22 09:54:01 ccc 63 4 2013/06/19 04:45:12 abc 120 5 2013/10/09 12:22:53 bbc 21 6 2013/03/23 20:12:23 zzz 9 BEGIN{ FS="t"; OFS="t"; } NR == 1{ print $1,$2,"TIME",$3,$4; next; } { split($2,datetime," "); print $1,datetime[1],datetime[2],$3,$4; }
28.
split。 ・日時を日付と時間に分割するスクリプト。 ・$2をスペースで分割してdatetimeに放り込む。 ・datetime[n]でn番目の要素にアクセス可能。 つまり日付はdatetime[1]、時間はdatetime[2]。 split.awk BEGIN{ FS="t"; OFS="t"; } NR == 1{ print
$1,$2,"TIME",$3,$4; next; } { split($2,datetime," "); print $1,datetime[1],datetime[2],$3,$4; }
29.
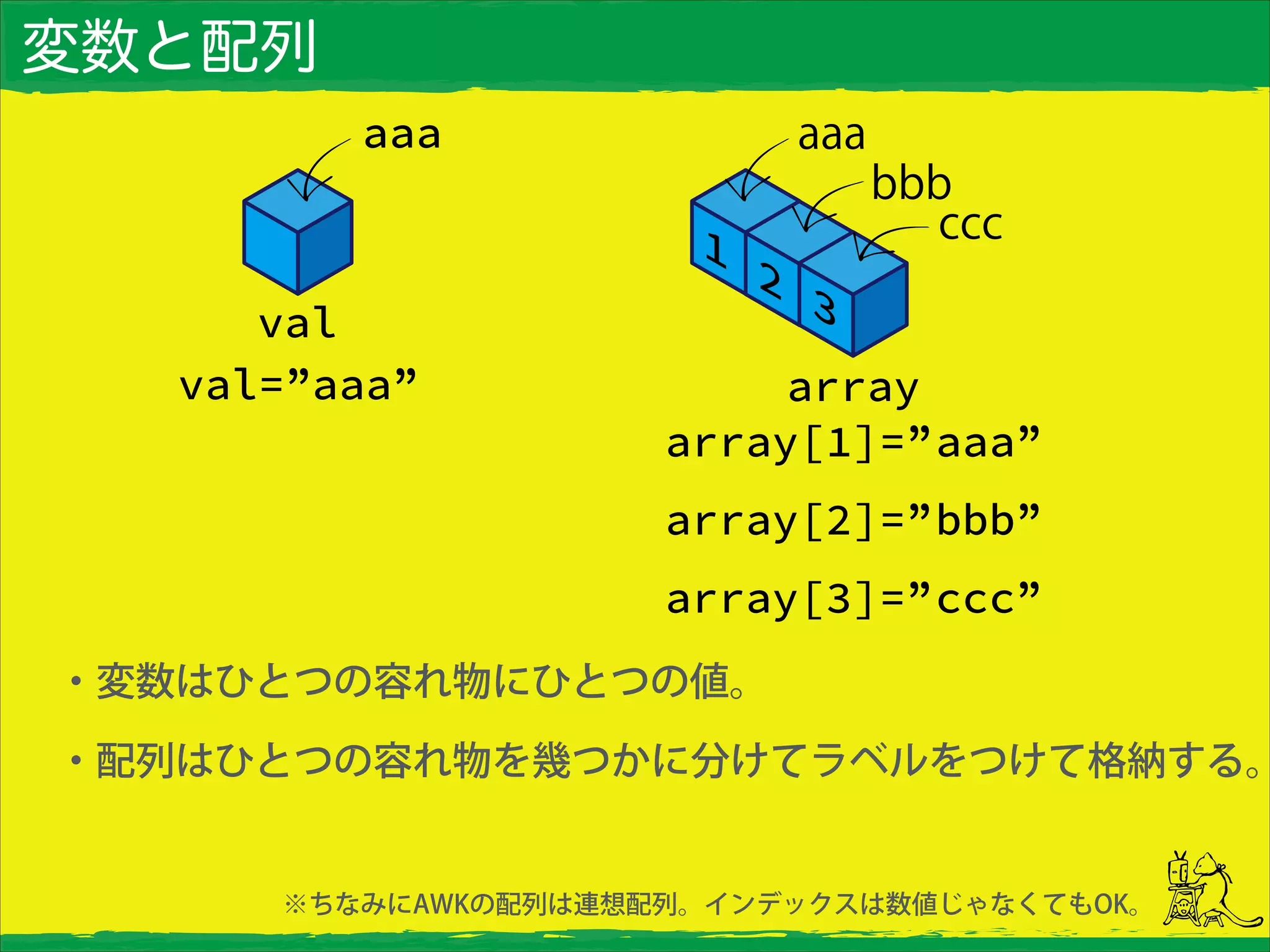
変数と配列 ・変数はひとつの容れ物にひとつの値。 ・配列はひとつの容れ物を幾つかに分けてラベルをつけて格納する。 val array ※ちなみにAWKの配列は連想配列。インデックスは数値じゃなくてもOK。
30.
条件式を使ってみよう(5) nr.awk > awk -f
nr.awk TestData.tsv 2 2013/04/05 12:10:09 bbb 42 3 2013/02/22 09:54:01 ccc 63 4 2013/06/19 04:45:12 abc 120 5 2013/10/09 12:22:53 bbc 21 $1==2,$1==5{ print $0 } ・条件式をカンマで2つ並べると最初の式が成り立ってから 2番目の式が成り立つまでを実行する。 ・上の例だと$1==2がなりたつ3行目から$1==5がなりたつ6行目 までを実行する。 ・$1が2,3,4,5の時に実行されるわけではない事に注意。
31.
条件式を使ってみよう(5) ・$5==20の2行目から$5==21の6行目までが出力される。 nr2.awk > awk -f
nr.awk TestData.tsv 1 2013/01/01 23:59:12 aaa 20 2 2013/04/05 12:10:09 bbb 42 3 2013/02/22 09:54:01 ccc 63 4 2013/06/19 04:45:12 abc 120 5 2013/10/09 12:22:53 bbc 21 BEGIN{ FS="t"; OFS="t"; } $4==20,$4==21{ print $0 }
32.
縦横置換スクリプト transpose.awk BEGIN{ FS="t"; OFS="t"; } { for(i=1;i<=NF;i++){ val[i, NR] =
$i; } } END{ for(i=1;i<=NF;i++){ for(j=1;j<=NR;j++){ printf("%st",val[i,j]); } print ""; } }
33.
縦横置換スクリプト読み解き for(i=1;i<=NF;i++){ val[i, NR] =
$i; } ↓val[1,1] ↓val[2,1] ↓val[3,1] ↓val[4,1] この for 文が何をしているか。 例えば今までと同様 TestData.tsv に対して実行してみると…。 データの最初の 1 行目は配列 val に以下の様に格納される。 2 行目はこんな感じに格納される。 ↓val[1,2] ↓val[2,2] ↓val[3,2] ↓val[4,2]
34.
縦横置換スクリプト読み解き for(i=1;i<=NF;i++){ val[i, NR] =
$i; } 最終的には横がフィールド、縦が行数の配列が出来上がる。 フィールド 行数 val
35.
縦横置換スクリプト読み解き END{ for(i=1;i<=NF;i++){ for(j=1;j<=NR;j++){ printf("%st",val[i,j]); } print ""; } 出力部分のfor部分を読み解いていくと… i=1/j=1の時。
36.
縦横置換スクリプト読み解き END{ for(i=1;i<=NF;i++){ for(j=1;j<=NR;j++){ printf("%st",val[i,j]); } print ""; } 出力部分のfor部分を読み解いていくと… i=1/j=2の時。
37.
縦横置換スクリプト読み解き END{ for(i=1;i<=NF;i++){ for(j=1;j<=NR;j++){ printf("%st",val[i,j]); } print ""; } 出力部分のfor部分を読み解いていくと… i=1/j=3の時。
38.
縦横置換スクリプト読み解き END{ for(i=1;i<=NF;i++){ for(j=1;j<=NR;j++){ printf("%st",val[i,j]); } print ""; } 出力部分のfor部分を読み解いていくと… i=1/j=4の時。
39.
縦横置換スクリプト読み解き END{ for(i=1;i<=NF;i++){ for(j=1;j<=NR;j++){ printf("%st",val[i,j]); } print ""; } 出力部分のfor部分を読み解いていくと… i=1/j=5の時。
40.
縦横置換スクリプト読み解き END{ for(i=1;i<=NF;i++){ for(j=1;j<=NR;j++){ printf("%st",val[i,j]); } print ""; } 出力部分のfor部分を読み解いていくと… i=1/j=6の時。
41.
縦横置換スクリプト読み解き END{ for(i=1;i<=NF;i++){ for(j=1;j<=NR;j++){ printf("%st",val[i,j]); } print ""; } 出力部分のfor部分を読み解いていくと… i=1/j=7の時。
42.
縦横置換スクリプト読み解き END{ for(i=1;i<=NF;i++){ for(j=1;j<=NR;j++){ printf("%st",val[i,j]); } print ""; } 出力部分のfor部分を読み解いていくと… i=1の中のjのループが終わったのでprint “”で改行を行う。
43.
縦横置換スクリプト読み解き END{ for(i=1;i<=NF;i++){ for(j=1;j<=NR;j++){ printf("%st",val[i,j]); } print ""; } 出力部分のfor部分を読み解いていくと… i=2/j=1の時。
44.
縦横置換スクリプト読み解き END{ for(i=1;i<=NF;i++){ for(j=1;j<=NR;j++){ printf("%st",val[i,j]); } print ""; } 出力部分のfor部分を読み解いていくと… i=2/j=2の時。
45.
縦横置換スクリプト読み解き END{ for(i=1;i<=NF;i++){ for(j=1;j<=NR;j++){ printf("%st",val[i,j]); } print ""; } 出力部分のfor部分を読み解いていくと… i=2/j=3の時。
46.
縦横置換スクリプト読み解き END{ for(i=1;i<=NF;i++){ for(j=1;j<=NR;j++){ printf("%st",val[i,j]); } print ""; } 出力部分のfor部分を読み解いていくと… i=2/j=4の時。
47.
縦横置換スクリプト読み解き END{ for(i=1;i<=NF;i++){ for(j=1;j<=NR;j++){ printf("%st",val[i,j]); } print ""; } 出力部分のfor部分を読み解いていくと… i=2/j=5の時。
48.
縦横置換スクリプト読み解き END{ for(i=1;i<=NF;i++){ for(j=1;j<=NR;j++){ printf("%st",val[i,j]); } print ""; } 出力部分のfor部分を読み解いていくと… i=2/j=6の時。
49.
縦横置換スクリプト読み解き END{ for(i=1;i<=NF;i++){ for(j=1;j<=NR;j++){ printf("%st",val[i,j]); } print ""; } 出力部分のfor部分を読み解いていくと… i=2/j=7の時。
50.
縦横置換スクリプト読み解き END{ for(i=1;i<=NF;i++){ for(j=1;j<=NR;j++){ printf("%st",val[i,j]); } print ""; } 出力部分のfor部分を読み解いていくと… i=2の中のjのループが終わったのでprint “”で改行を行う。
51.
縦横置換スクリプト読み解き END{ for(i=1;i<=NF;i++){ for(j=1;j<=NR;j++){ printf("%st",val[i,j]); } print ""; } 出力部分のfor部分を読み解いていくと… i=3/j=1の時。
52.
縦横置換スクリプト読み解き END{ for(i=1;i<=NF;i++){ for(j=1;j<=NR;j++){ printf("%st",val[i,j]); } print ""; } 出力部分のfor部分を読み解いていくと… i=3/j=2の時。
53.
縦横置換スクリプト読み解き END{ for(i=1;i<=NF;i++){ for(j=1;j<=NR;j++){ printf("%st",val[i,j]); } print ""; } 出力部分のfor部分を読み解いていくと… i=3/j=3の時。
54.
縦横置換スクリプト読み解き END{ for(i=1;i<=NF;i++){ for(j=1;j<=NR;j++){ printf("%st",val[i,j]); } print ""; } 出力部分のfor部分を読み解いていくと… i=3/j=4の時。
55.
縦横置換スクリプト読み解き END{ for(i=1;i<=NF;i++){ for(j=1;j<=NR;j++){ printf("%st",val[i,j]); } print ""; } 出力部分のfor部分を読み解いていくと… i=3/j=5の時。
56.
縦横置換スクリプト読み解き END{ for(i=1;i<=NF;i++){ for(j=1;j<=NR;j++){ printf("%st",val[i,j]); } print ""; } 出力部分のfor部分を読み解いていくと… i=3/j=6の時。
57.
縦横置換スクリプト読み解き END{ for(i=1;i<=NF;i++){ for(j=1;j<=NR;j++){ printf("%st",val[i,j]); } print ""; } 出力部分のfor部分を読み解いていくと… i=3/j=7の時。
58.
縦横置換スクリプト読み解き END{ for(i=1;i<=NF;i++){ for(j=1;j<=NR;j++){ printf("%st",val[i,j]); } print ""; } 出力部分のfor部分を読み解いていくと… i=3の中のjのループが終わったのでprint “”で改行を行う。
59.
縦横置換スクリプト読み解き END{ for(i=1;i<=NF;i++){ for(j=1;j<=NR;j++){ printf("%st",val[i,j]); } print ""; } 出力部分のfor部分を読み解いていくと… i=4/j=1の時。
60.
縦横置換スクリプト読み解き END{ for(i=1;i<=NF;i++){ for(j=1;j<=NR;j++){ printf("%st",val[i,j]); } print ""; } 出力部分のfor部分を読み解いていくと… i=4/j=2の時。
61.
縦横置換スクリプト読み解き END{ for(i=1;i<=NF;i++){ for(j=1;j<=NR;j++){ printf("%st",val[i,j]); } print ""; } 出力部分のfor部分を読み解いていくと… i=4/j=3の時。
62.
縦横置換スクリプト読み解き END{ for(i=1;i<=NF;i++){ for(j=1;j<=NR;j++){ printf("%st",val[i,j]); } print ""; } 出力部分のfor部分を読み解いていくと… i=4/j=4の時。
63.
縦横置換スクリプト読み解き END{ for(i=1;i<=NF;i++){ for(j=1;j<=NR;j++){ printf("%st",val[i,j]); } print ""; } 出力部分のfor部分を読み解いていくと… i=4/j=5の時。
64.
縦横置換スクリプト読み解き END{ for(i=1;i<=NF;i++){ for(j=1;j<=NR;j++){ printf("%st",val[i,j]); } print ""; } 出力部分のfor部分を読み解いていくと… i=4/j=6の時。
65.
縦横置換スクリプト読み解き END{ for(i=1;i<=NF;i++){ for(j=1;j<=NR;j++){ printf("%st",val[i,j]); } print ""; } 出力部分のfor部分を読み解いていくと… i=4/j=7の時。
66.
縦横置換スクリプト読み解き END{ for(i=1;i<=NF;i++){ for(j=1;j<=NR;j++){ printf("%st",val[i,j]); } print ""; } 出力部分のfor部分を読み解いていくと… i=4の中のjのループが終わったのでprint “”で改行を行う。
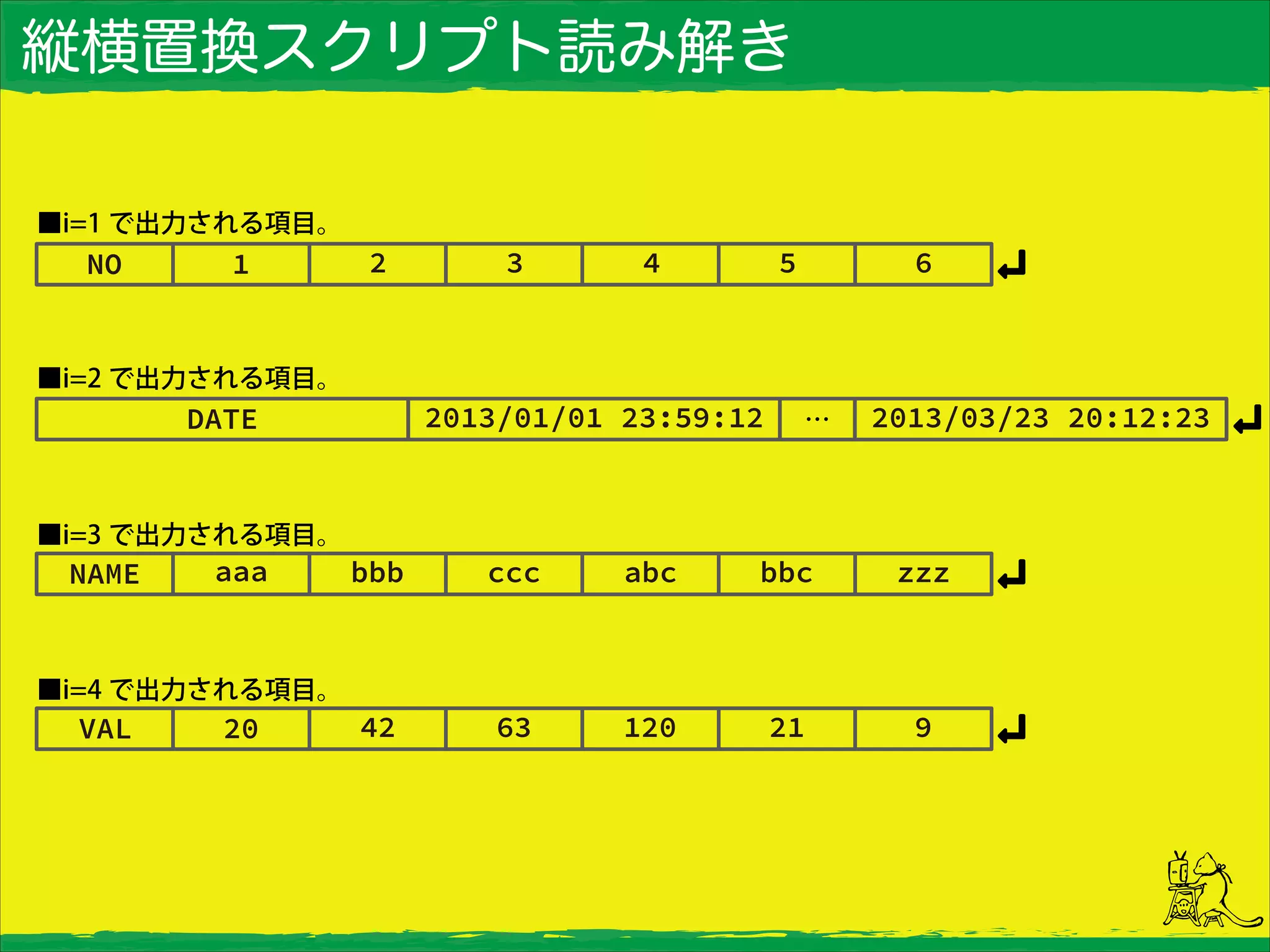
67.
縦横置換スクリプト読み解き ■i=1 で出力される項目。 ■i=2 で出力される項目。 ■i=3
で出力される項目。 ■i=4 で出力される項目。
Download






















![split。
split.awk
> awk -f split.awk TestData.tsv
NO DATE TIME NAME VAL
1 2013/01/01 23:59:12 aaa 20
2 2013/04/05 12:10:09 bbb 42
3 2013/02/22 09:54:01 ccc 63
4 2013/06/19 04:45:12 abc 120
5 2013/10/09 12:22:53 bbc 21
6 2013/03/23 20:12:23 zzz 9
BEGIN{
FS="t";
OFS="t";
}
NR == 1{
print $1,$2,"TIME",$3,$4;
next;
}
{
split($2,datetime," ");
print $1,datetime[1],datetime[2],$3,$4;
}](https://image.slidesharecdn.com/awk-140602215259-phpapp01/75/Awk-27-2048.jpg)
![split。
・日時を日付と時間に分割するスクリプト。
・$2をスペースで分割してdatetimeに放り込む。
・datetime[n]でn番目の要素にアクセス可能。
つまり日付はdatetime[1]、時間はdatetime[2]。
split.awk
BEGIN{
FS="t";
OFS="t";
}
NR == 1{
print $1,$2,"TIME",$3,$4;
next;
}
{
split($2,datetime," ");
print $1,datetime[1],datetime[2],$3,$4;
}](https://image.slidesharecdn.com/awk-140602215259-phpapp01/75/Awk-28-2048.jpg)


![縦横置換スクリプト
transpose.awk
BEGIN{
FS="t";
OFS="t";
}
{
for(i=1;i<=NF;i++){
val[i, NR] = $i;
}
}
END{
for(i=1;i<=NF;i++){
for(j=1;j<=NR;j++){
printf("%st",val[i,j]);
}
print "";
}
}](https://image.slidesharecdn.com/awk-140602215259-phpapp01/75/Awk-32-2048.jpg)
![縦横置換スクリプト読み解き
for(i=1;i<=NF;i++){
val[i, NR] = $i;
}
↓val[1,1] ↓val[2,1] ↓val[3,1] ↓val[4,1]
この for 文が何をしているか。
例えば今までと同様 TestData.tsv に対して実行してみると…。
データの最初の 1 行目は配列 val に以下の様に格納される。
2 行目はこんな感じに格納される。
↓val[1,2] ↓val[2,2] ↓val[3,2] ↓val[4,2]](https://image.slidesharecdn.com/awk-140602215259-phpapp01/75/Awk-33-2048.jpg)
![縦横置換スクリプト読み解き
for(i=1;i<=NF;i++){
val[i, NR] = $i;
}
最終的には横がフィールド、縦が行数の配列が出来上がる。
フィールド
行数
val](https://image.slidesharecdn.com/awk-140602215259-phpapp01/75/Awk-34-2048.jpg)
![縦横置換スクリプト読み解き
END{
for(i=1;i<=NF;i++){
for(j=1;j<=NR;j++){
printf("%st",val[i,j]);
}
print "";
}
出力部分のfor部分を読み解いていくと…
i=1/j=1の時。](https://image.slidesharecdn.com/awk-140602215259-phpapp01/75/Awk-35-2048.jpg)
![縦横置換スクリプト読み解き
END{
for(i=1;i<=NF;i++){
for(j=1;j<=NR;j++){
printf("%st",val[i,j]);
}
print "";
}
出力部分のfor部分を読み解いていくと…
i=1/j=2の時。](https://image.slidesharecdn.com/awk-140602215259-phpapp01/75/Awk-36-2048.jpg)
![縦横置換スクリプト読み解き
END{
for(i=1;i<=NF;i++){
for(j=1;j<=NR;j++){
printf("%st",val[i,j]);
}
print "";
}
出力部分のfor部分を読み解いていくと…
i=1/j=3の時。](https://image.slidesharecdn.com/awk-140602215259-phpapp01/75/Awk-37-2048.jpg)
![縦横置換スクリプト読み解き
END{
for(i=1;i<=NF;i++){
for(j=1;j<=NR;j++){
printf("%st",val[i,j]);
}
print "";
}
出力部分のfor部分を読み解いていくと…
i=1/j=4の時。](https://image.slidesharecdn.com/awk-140602215259-phpapp01/75/Awk-38-2048.jpg)
![縦横置換スクリプト読み解き
END{
for(i=1;i<=NF;i++){
for(j=1;j<=NR;j++){
printf("%st",val[i,j]);
}
print "";
}
出力部分のfor部分を読み解いていくと…
i=1/j=5の時。](https://image.slidesharecdn.com/awk-140602215259-phpapp01/75/Awk-39-2048.jpg)
![縦横置換スクリプト読み解き
END{
for(i=1;i<=NF;i++){
for(j=1;j<=NR;j++){
printf("%st",val[i,j]);
}
print "";
}
出力部分のfor部分を読み解いていくと…
i=1/j=6の時。](https://image.slidesharecdn.com/awk-140602215259-phpapp01/75/Awk-40-2048.jpg)
![縦横置換スクリプト読み解き
END{
for(i=1;i<=NF;i++){
for(j=1;j<=NR;j++){
printf("%st",val[i,j]);
}
print "";
}
出力部分のfor部分を読み解いていくと…
i=1/j=7の時。](https://image.slidesharecdn.com/awk-140602215259-phpapp01/75/Awk-41-2048.jpg)
![縦横置換スクリプト読み解き
END{
for(i=1;i<=NF;i++){
for(j=1;j<=NR;j++){
printf("%st",val[i,j]);
}
print "";
}
出力部分のfor部分を読み解いていくと…
i=1の中のjのループが終わったのでprint “”で改行を行う。](https://image.slidesharecdn.com/awk-140602215259-phpapp01/75/Awk-42-2048.jpg)
![縦横置換スクリプト読み解き
END{
for(i=1;i<=NF;i++){
for(j=1;j<=NR;j++){
printf("%st",val[i,j]);
}
print "";
}
出力部分のfor部分を読み解いていくと…
i=2/j=1の時。](https://image.slidesharecdn.com/awk-140602215259-phpapp01/75/Awk-43-2048.jpg)
![縦横置換スクリプト読み解き
END{
for(i=1;i<=NF;i++){
for(j=1;j<=NR;j++){
printf("%st",val[i,j]);
}
print "";
}
出力部分のfor部分を読み解いていくと…
i=2/j=2の時。](https://image.slidesharecdn.com/awk-140602215259-phpapp01/75/Awk-44-2048.jpg)
![縦横置換スクリプト読み解き
END{
for(i=1;i<=NF;i++){
for(j=1;j<=NR;j++){
printf("%st",val[i,j]);
}
print "";
}
出力部分のfor部分を読み解いていくと…
i=2/j=3の時。](https://image.slidesharecdn.com/awk-140602215259-phpapp01/75/Awk-45-2048.jpg)
![縦横置換スクリプト読み解き
END{
for(i=1;i<=NF;i++){
for(j=1;j<=NR;j++){
printf("%st",val[i,j]);
}
print "";
}
出力部分のfor部分を読み解いていくと…
i=2/j=4の時。](https://image.slidesharecdn.com/awk-140602215259-phpapp01/75/Awk-46-2048.jpg)
![縦横置換スクリプト読み解き
END{
for(i=1;i<=NF;i++){
for(j=1;j<=NR;j++){
printf("%st",val[i,j]);
}
print "";
}
出力部分のfor部分を読み解いていくと…
i=2/j=5の時。](https://image.slidesharecdn.com/awk-140602215259-phpapp01/75/Awk-47-2048.jpg)
![縦横置換スクリプト読み解き
END{
for(i=1;i<=NF;i++){
for(j=1;j<=NR;j++){
printf("%st",val[i,j]);
}
print "";
}
出力部分のfor部分を読み解いていくと…
i=2/j=6の時。](https://image.slidesharecdn.com/awk-140602215259-phpapp01/75/Awk-48-2048.jpg)
![縦横置換スクリプト読み解き
END{
for(i=1;i<=NF;i++){
for(j=1;j<=NR;j++){
printf("%st",val[i,j]);
}
print "";
}
出力部分のfor部分を読み解いていくと…
i=2/j=7の時。](https://image.slidesharecdn.com/awk-140602215259-phpapp01/75/Awk-49-2048.jpg)
![縦横置換スクリプト読み解き
END{
for(i=1;i<=NF;i++){
for(j=1;j<=NR;j++){
printf("%st",val[i,j]);
}
print "";
}
出力部分のfor部分を読み解いていくと…
i=2の中のjのループが終わったのでprint “”で改行を行う。](https://image.slidesharecdn.com/awk-140602215259-phpapp01/75/Awk-50-2048.jpg)
![縦横置換スクリプト読み解き
END{
for(i=1;i<=NF;i++){
for(j=1;j<=NR;j++){
printf("%st",val[i,j]);
}
print "";
}
出力部分のfor部分を読み解いていくと…
i=3/j=1の時。](https://image.slidesharecdn.com/awk-140602215259-phpapp01/75/Awk-51-2048.jpg)
![縦横置換スクリプト読み解き
END{
for(i=1;i<=NF;i++){
for(j=1;j<=NR;j++){
printf("%st",val[i,j]);
}
print "";
}
出力部分のfor部分を読み解いていくと…
i=3/j=2の時。](https://image.slidesharecdn.com/awk-140602215259-phpapp01/75/Awk-52-2048.jpg)
![縦横置換スクリプト読み解き
END{
for(i=1;i<=NF;i++){
for(j=1;j<=NR;j++){
printf("%st",val[i,j]);
}
print "";
}
出力部分のfor部分を読み解いていくと…
i=3/j=3の時。](https://image.slidesharecdn.com/awk-140602215259-phpapp01/75/Awk-53-2048.jpg)
![縦横置換スクリプト読み解き
END{
for(i=1;i<=NF;i++){
for(j=1;j<=NR;j++){
printf("%st",val[i,j]);
}
print "";
}
出力部分のfor部分を読み解いていくと…
i=3/j=4の時。](https://image.slidesharecdn.com/awk-140602215259-phpapp01/75/Awk-54-2048.jpg)
![縦横置換スクリプト読み解き
END{
for(i=1;i<=NF;i++){
for(j=1;j<=NR;j++){
printf("%st",val[i,j]);
}
print "";
}
出力部分のfor部分を読み解いていくと…
i=3/j=5の時。](https://image.slidesharecdn.com/awk-140602215259-phpapp01/75/Awk-55-2048.jpg)
![縦横置換スクリプト読み解き
END{
for(i=1;i<=NF;i++){
for(j=1;j<=NR;j++){
printf("%st",val[i,j]);
}
print "";
}
出力部分のfor部分を読み解いていくと…
i=3/j=6の時。](https://image.slidesharecdn.com/awk-140602215259-phpapp01/75/Awk-56-2048.jpg)
![縦横置換スクリプト読み解き
END{
for(i=1;i<=NF;i++){
for(j=1;j<=NR;j++){
printf("%st",val[i,j]);
}
print "";
}
出力部分のfor部分を読み解いていくと…
i=3/j=7の時。](https://image.slidesharecdn.com/awk-140602215259-phpapp01/75/Awk-57-2048.jpg)
![縦横置換スクリプト読み解き
END{
for(i=1;i<=NF;i++){
for(j=1;j<=NR;j++){
printf("%st",val[i,j]);
}
print "";
}
出力部分のfor部分を読み解いていくと…
i=3の中のjのループが終わったのでprint “”で改行を行う。](https://image.slidesharecdn.com/awk-140602215259-phpapp01/75/Awk-58-2048.jpg)
![縦横置換スクリプト読み解き
END{
for(i=1;i<=NF;i++){
for(j=1;j<=NR;j++){
printf("%st",val[i,j]);
}
print "";
}
出力部分のfor部分を読み解いていくと…
i=4/j=1の時。](https://image.slidesharecdn.com/awk-140602215259-phpapp01/75/Awk-59-2048.jpg)
![縦横置換スクリプト読み解き
END{
for(i=1;i<=NF;i++){
for(j=1;j<=NR;j++){
printf("%st",val[i,j]);
}
print "";
}
出力部分のfor部分を読み解いていくと…
i=4/j=2の時。](https://image.slidesharecdn.com/awk-140602215259-phpapp01/75/Awk-60-2048.jpg)
![縦横置換スクリプト読み解き
END{
for(i=1;i<=NF;i++){
for(j=1;j<=NR;j++){
printf("%st",val[i,j]);
}
print "";
}
出力部分のfor部分を読み解いていくと…
i=4/j=3の時。](https://image.slidesharecdn.com/awk-140602215259-phpapp01/75/Awk-61-2048.jpg)
![縦横置換スクリプト読み解き
END{
for(i=1;i<=NF;i++){
for(j=1;j<=NR;j++){
printf("%st",val[i,j]);
}
print "";
}
出力部分のfor部分を読み解いていくと…
i=4/j=4の時。](https://image.slidesharecdn.com/awk-140602215259-phpapp01/75/Awk-62-2048.jpg)
![縦横置換スクリプト読み解き
END{
for(i=1;i<=NF;i++){
for(j=1;j<=NR;j++){
printf("%st",val[i,j]);
}
print "";
}
出力部分のfor部分を読み解いていくと…
i=4/j=5の時。](https://image.slidesharecdn.com/awk-140602215259-phpapp01/75/Awk-63-2048.jpg)
![縦横置換スクリプト読み解き
END{
for(i=1;i<=NF;i++){
for(j=1;j<=NR;j++){
printf("%st",val[i,j]);
}
print "";
}
出力部分のfor部分を読み解いていくと…
i=4/j=6の時。](https://image.slidesharecdn.com/awk-140602215259-phpapp01/75/Awk-64-2048.jpg)
![縦横置換スクリプト読み解き
END{
for(i=1;i<=NF;i++){
for(j=1;j<=NR;j++){
printf("%st",val[i,j]);
}
print "";
}
出力部分のfor部分を読み解いていくと…
i=4/j=7の時。](https://image.slidesharecdn.com/awk-140602215259-phpapp01/75/Awk-65-2048.jpg)
![縦横置換スクリプト読み解き
END{
for(i=1;i<=NF;i++){
for(j=1;j<=NR;j++){
printf("%st",val[i,j]);
}
print "";
}
出力部分のfor部分を読み解いていくと…
i=4の中のjのループが終わったのでprint “”で改行を行う。](https://image.slidesharecdn.com/awk-140602215259-phpapp01/75/Awk-66-2048.jpg)