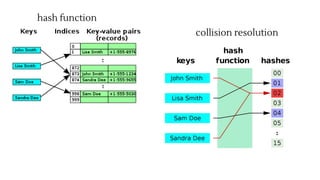
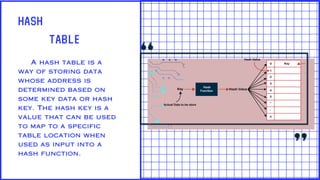
A hash table is a data structure that uses a hash function to map keys to unique indices in an underlying array. Collisions occur when two keys hash to the same index and must be resolved. Open addressing resolves collisions by probing through alternative array locations until an empty slot is found. Double hashing is an open addressing collision resolution technique that uses a secondary hash of the key as an offset when probing for the next index. Hash tables provide efficient lookup, insertion and deletion of key-value pairs and are used widely in applications like databases, caching and cryptography.



























































![谷歌霸屏推广[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130171247-43791db0-thumbnail.jpg?width=640&height=640&fit=bounds)

