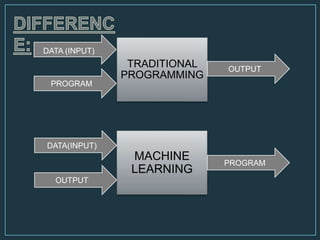
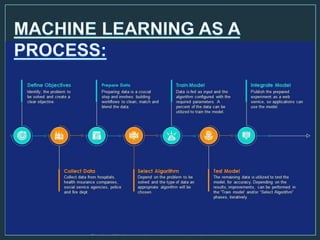
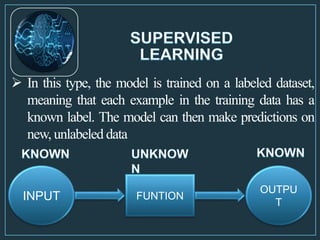
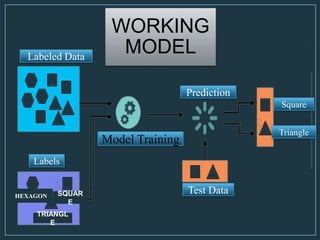
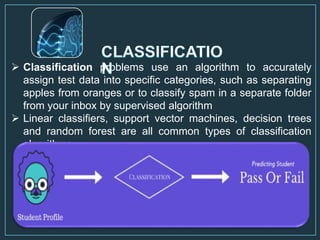
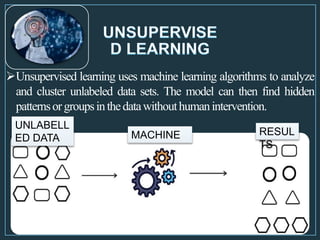
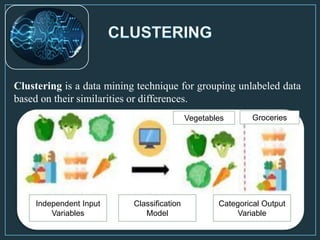
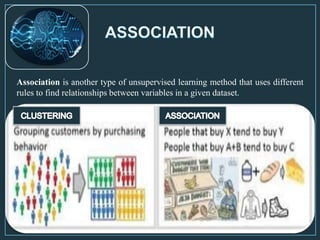
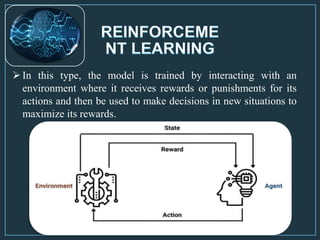
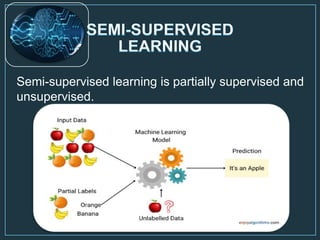
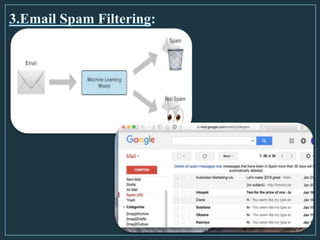
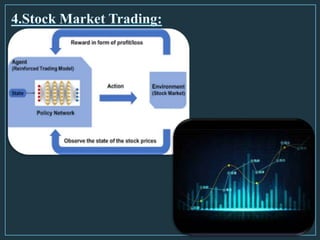
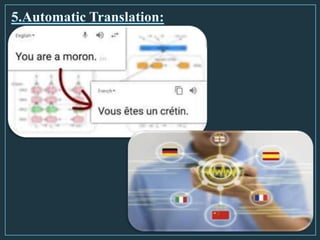
Machine learning is a form of artificial intelligence that allows computers to learn without being explicitly programmed by exploring data, identifying patterns, and improving with experience. The document outlines the history of machine learning and how it works, describing different types including supervised learning, unsupervised learning, reinforcement learning, and semi-supervised learning. It also discusses applications and advantages/disadvantages of machine learning.