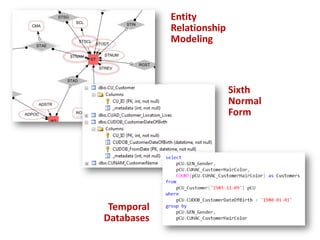
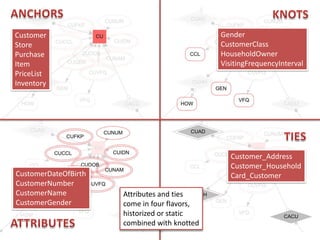
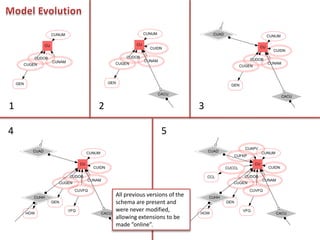
The document discusses an agile modeling technique utilizing the sixth normal form for managing structurally and temporally evolving data. It covers various aspects such as entity relationship modeling, attributes, and query execution, while emphasizing features like ease of modeling, simplified maintenance, and high performance. Additionally, it highlights the ability to handle temporal data efficiently through a combination of historical and current attributes.
![AN AGILE MODELING TECHNIQUE USING THE SIXTH NORMAL FORM
FOR STRUCTURALLY AND TEMPORALLY EVOLVING DATA
Lars Rönnbäck
[ER09]](https://image.slidesharecdn.com/anchormodelinger09presentation-100909130056-phpapp02/85/Anchor-Modeling-1-320.jpg)
![AN AGILE MODELING TECHNIQUE USING THE SIXTH NORMAL FORM
FOR STRUCTURALLY AND TEMPORALLY EVOLVING DATA
Lars Rönnbäck
[ER09]](https://image.slidesharecdn.com/anchormodelinger09presentation-100909130056-phpapp02/75/Anchor-Modeling-1-2048.jpg)



































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)
















