This document discusses the labs for an AI course. It provides:
1. An overview of the labs covered, including DNN, CNN, and reinforcement learning labs.
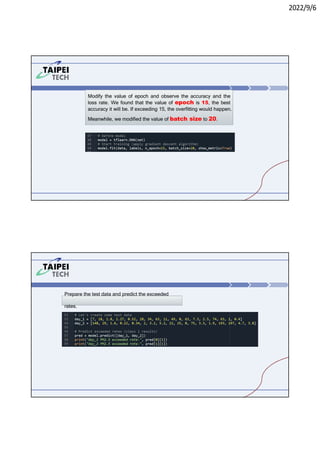
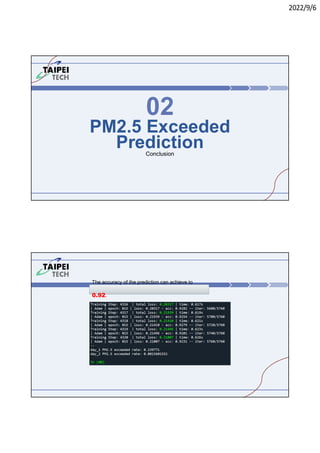
2. Guidelines for lab reports including getting reasonable results, tuning hyperparameters, and changing datasets.
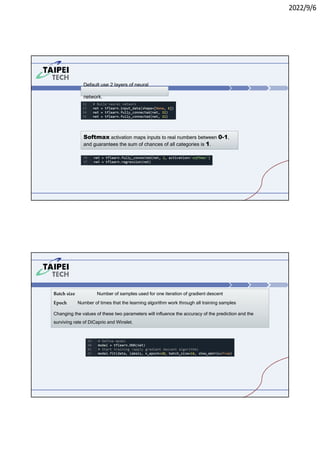
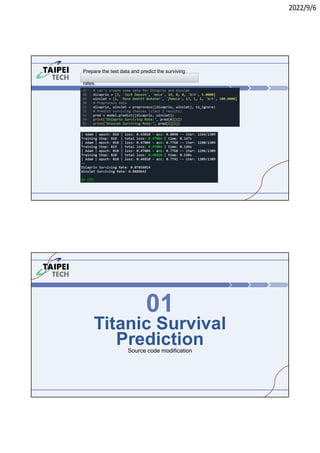
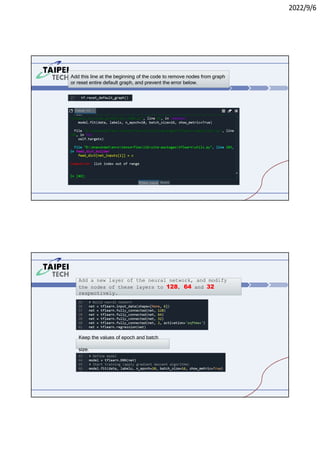
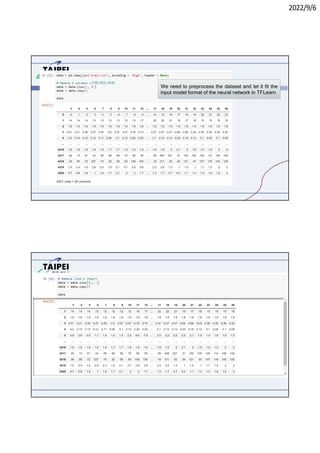
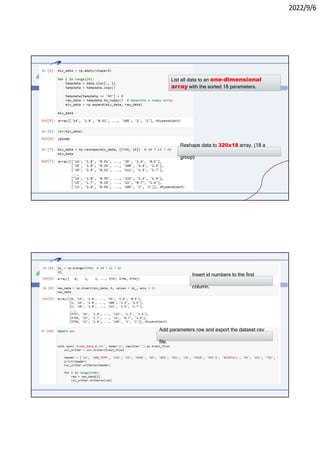
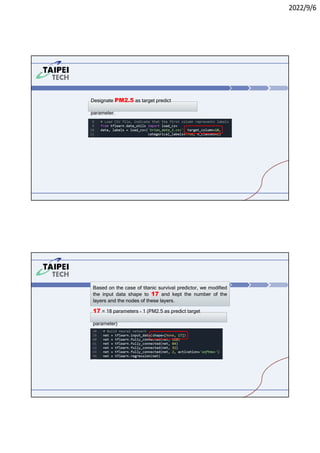
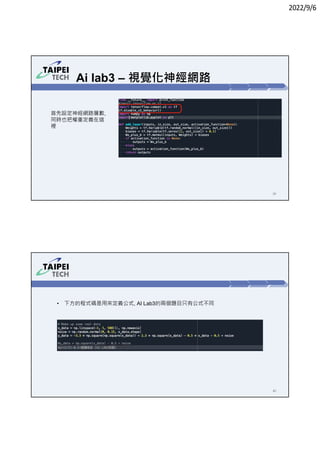
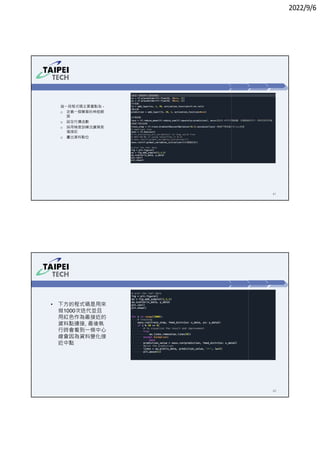
3. Instructions for running Lab 1 (titanic survival prediction) and Lab 3 (curve fitting), including code snippets and directories to navigate.