Downloaded 13 times







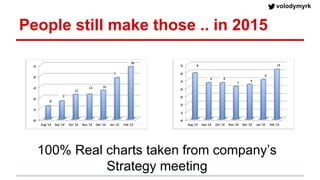


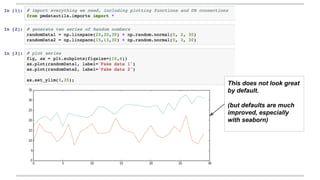
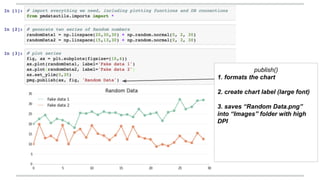
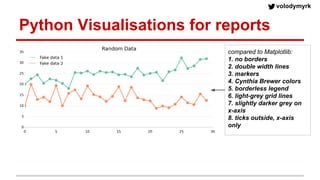
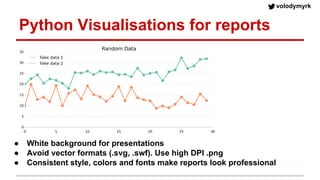

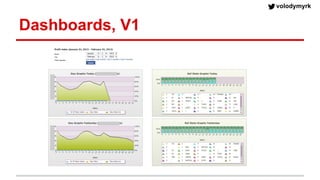
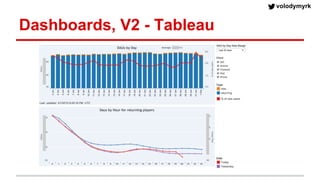



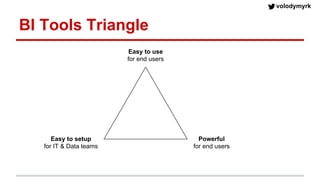
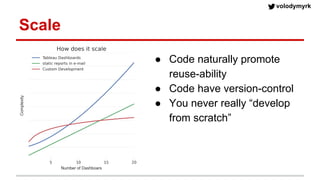
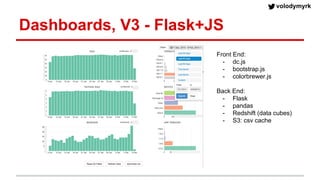





Volodymyr Kazantsev, head of data science at Product Madness, discusses effective data visualization strategies used in their social casino games sector. He emphasizes the importance of simplicity, consistency, and context in visualizations, while outlining best practices for creating web-based dashboards. The document also covers the tech stack used for data analysis and the significance of interactive and visually appealing presentations for deriving insights.
















































































