Download to read offline










![Предсказание успешности сессии
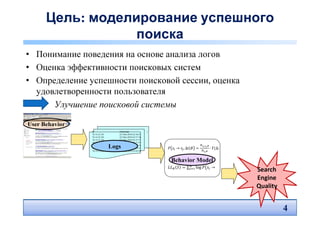
• Метод машинного обучения
– Input: лог для отдельной поисковой сессии
(запросы, клики, движения мыши, scrolling)
– Output: флаг «поисковая сессия успешна»?
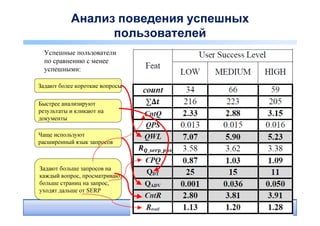
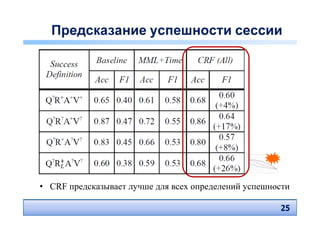
• 4 определения успешности – QRAV model
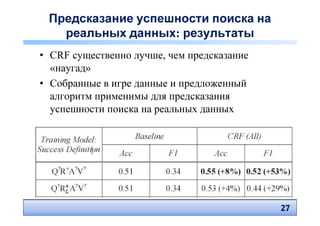
• Baseline: Markov Model + Time distribution
[Hassan et al. WSDM 2010], 2 фактора
– STATE ∈ { QUERY, R1, R>1, END }
– Time delta ∆t
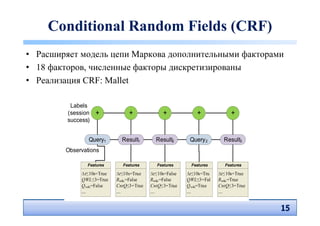
• Наш подход: Conditional Random Fields (CRF)
– 18 факторов, извлекаемых из логов
14
14](https://image.slidesharecdn.com/ageev-120529054940-phpapp01/85/Ageev-14-320.jpg)




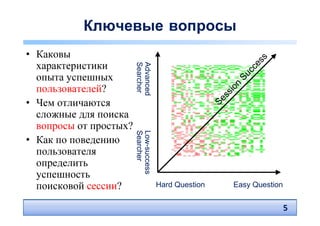
![Разные определения успешности
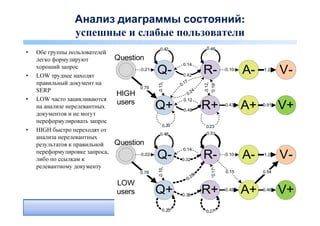
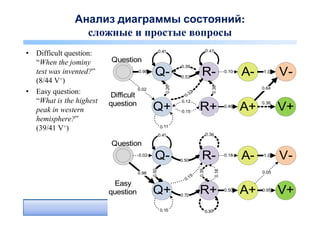
поисковой сессии
• Q+R+A+V+: Найден
правильный ответ Question
[TREC QA track] Q- R- A- V-
• Q+R+A+V?: Пользователь
нашел некоторый ответ и
верит, что его ответ Q+ R+ A+ V+
правильный; пользователь
удовлетворен, хотя ответ
может быть неправильным
[Aula et al. CHI 2010]
• Q+R+A?V?: Пользователь нашел хороший документ и посмотрел его (но не
обязательно нашел в нем ответ) – [Hassan et al. WSDM 2010]
• Q?RL+A?V?: Пользователь нашел хороший документ и остановил свой выбор на
нем (просмотрел последним в сессии), после этого пользователь
(предположительно) удовлетворен [Dupret et al., WSDM 2010]
21
21](https://image.slidesharecdn.com/ageev-120529054940-phpapp01/85/Ageev-21-320.jpg)




Документ представляет анализ поведения пользователей интернет-поисковых систем с использованием игровых подходов для сбора данных. Основное внимание уделяется моделированию успешных поисковых сессий, оценке качества поисковых систем и предсказанию успешности поиска через методы машинного обучения. Выявлены ключевые характеристики успешных пользователей, а также разработана иерархическая модель успешной поисковой сессии.




























![[ИТ-лекторий ФКН ВШЭ]: Диалоговые системы. Татьяна Ландо](https://cdn.slidesharecdn.com/ss_thumbnails/fknlando-160519095450-thumbnail.jpg?width=640&height=640&fit=bounds)


















