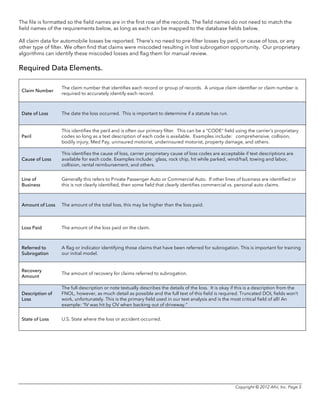
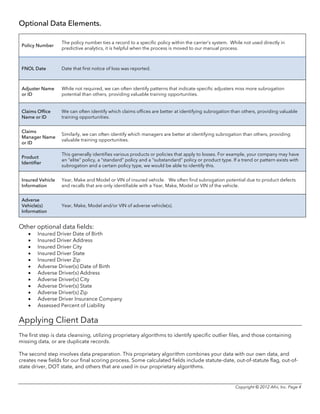
Afni utilizes advanced analytics to identify subrogation potential in closed insurance claims files that traditional methods may miss. Their predictive modeling techniques can identify 99.5% of files that should have been referred to subrogation, and they recover more than competitors at a lower cost. Key aspects of their approach include text mining of loss descriptions, applying categorizations and propensity scores to flag potential, and periodically re-reviewing files to catch more opportunities for subrogation recovery. This can yield insurance companies additional millions in annual recovery compared to traditional file review methods.