Download as PDF, PPTX





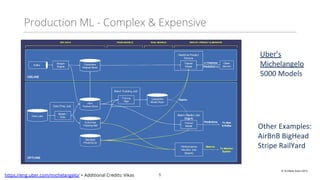
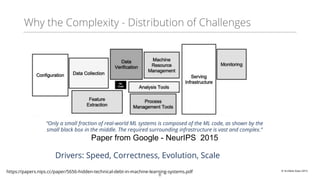
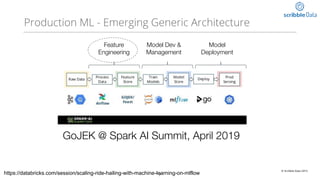


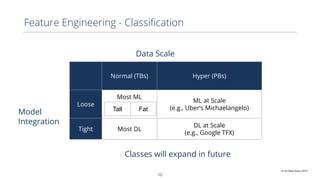

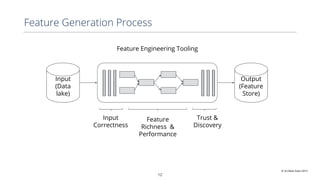
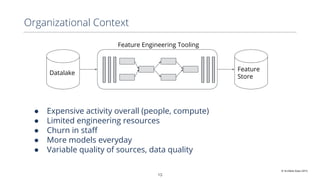



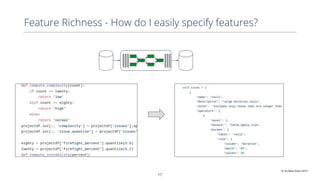

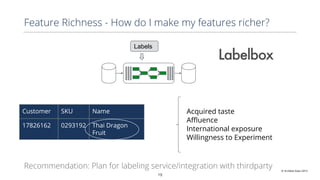


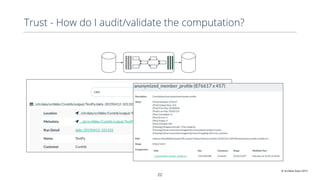

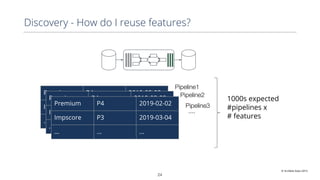













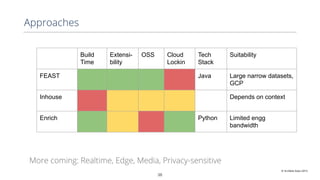



This document discusses production machine learning and feature engineering. It notes that production ML is complex and expensive due to the surrounding infrastructure required. A production feature engineering platform can help by providing capabilities for feature richness and performance, trust and discovery, and input correctness. It discusses challenges such as how to compute features reliably, easily specify features, make features richer, audit feature computation, and discover and reuse features. It also covers considerations for deciding on and implementing a feature engineering platform, such as economics, questions to ask, and different approaches.



![OpenBOM SaaS PLM for Onshape [Webinar Slide Deck]](https://cdn.slidesharecdn.com/ss_thumbnails/openbomsaasplmforonshapewebinar-201205115432-thumbnail.jpg?width=640&height=640&fit=bounds)


















































