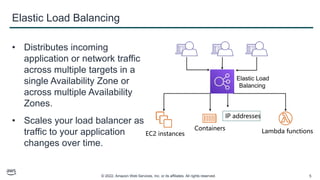
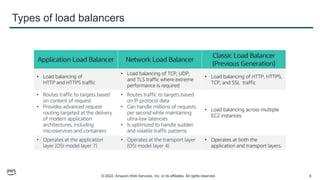
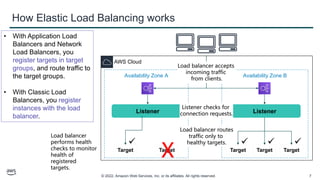
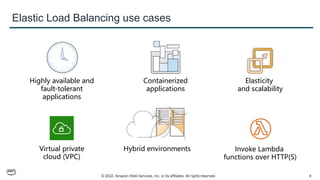
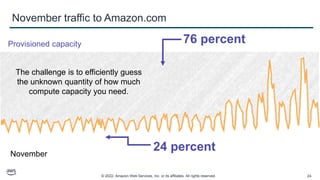
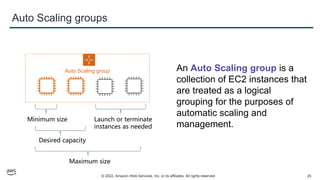
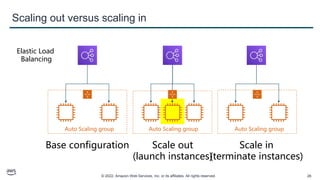
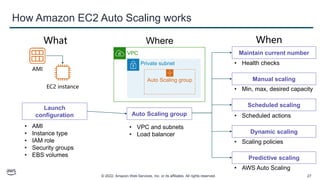
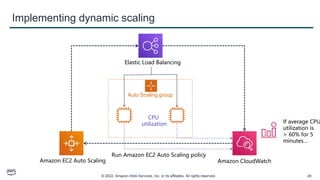
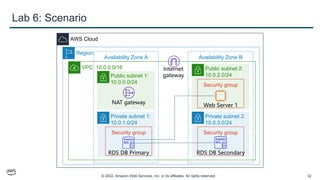
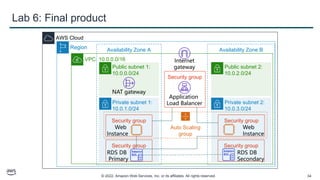
This document provides an overview of automatic scaling and monitoring on AWS. It discusses Elastic Load Balancing and how it distributes traffic across instances, Amazon CloudWatch for real-time monitoring of resources, and Amazon EC2 Auto Scaling for launching and terminating instances in response to workload changes. The objectives are to learn how to distribute traffic with ELB, monitor with CloudWatch, and automatically scale with Auto Scaling.









































![[Jun AWS 201] Technical Workshop](https://cdn.slidesharecdn.com/ss_thumbnails/aws201general201tworkshop-130708040331-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)

![[AWS에서의 미디어 및 엔터테인먼트] AWS 개요, 클라우드 스토리지 및 Amazon CloudFront, Elastic Transcod...](https://cdn.slidesharecdn.com/ss_thumbnails/awsoverview-140219201920-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)






























