






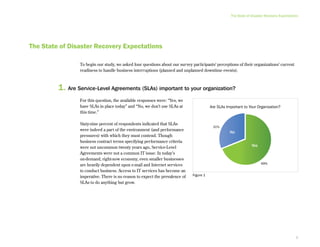
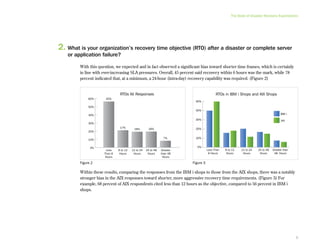
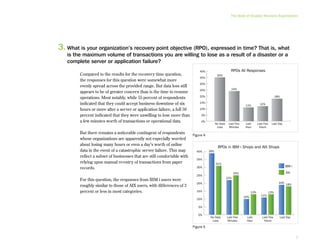
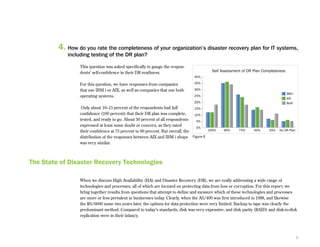
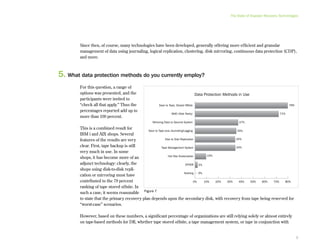

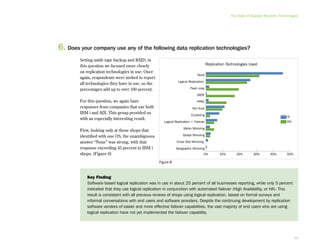

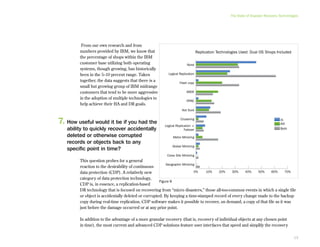


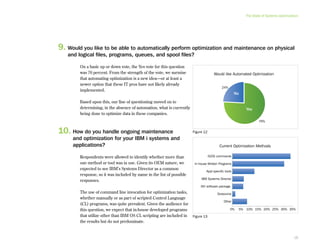





This document provides an executive summary and introduction to a research report on the state of disaster recovery and systems optimization for IBM Power Systems customers running IBM i and AIX. The report focuses on customer expectations for recovery time and recovery point objectives, the disaster recovery technologies and methods in use, and the state of systems optimization capabilities, tools, automation, and requirements. It provides an overview of key findings and issues for executives to consider regarding data protection, availability, quality, and efficiency.














































