Download as PDF, PPTX
























































































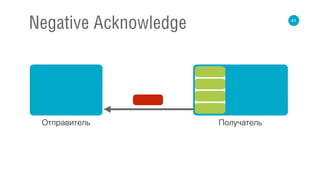
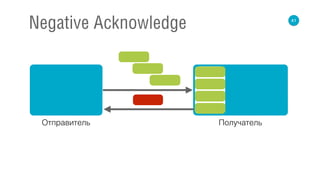
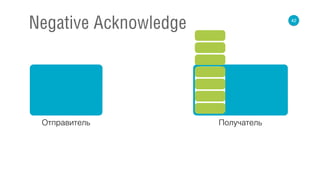





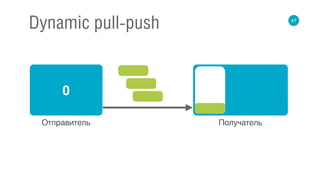




































![62
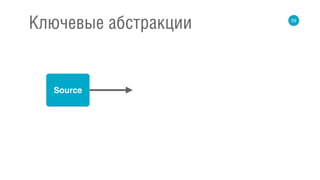
Sink
val blackhole = Sink.ignore
val onComplete = Sink.onComplete { result =>
System.exit(0)
}
val foreach = Sink.foreach(println)
val firstElement = Sink.head[Int]](https://image.slidesharecdn.com/3romanchuk-150412233406-conversion-gate01/85/backend-c-144-320.jpg)

val flow = source.to(sink)
flow.run()](https://image.slidesharecdn.com/3romanchuk-150412233406-conversion-gate01/85/backend-c-145-320.jpg)

val flow = source.to(sink)
flow.run()](https://image.slidesharecdn.com/3romanchuk-150412233406-conversion-gate01/85/backend-c-146-320.jpg)

val flow = source.to(sink)
flow.run()](https://image.slidesharecdn.com/3romanchuk-150412233406-conversion-gate01/85/backend-c-147-320.jpg)

val flow = source.to(sink)
flow.run()](https://image.slidesharecdn.com/3romanchuk-150412233406-conversion-gate01/85/backend-c-148-320.jpg)

val flow = source.to(sink)
flow.run()](https://image.slidesharecdn.com/3romanchuk-150412233406-conversion-gate01/85/backend-c-149-320.jpg)

val flow = source.to(sink)
flow.run()](https://image.slidesharecdn.com/3romanchuk-150412233406-conversion-gate01/85/backend-c-150-320.jpg)

val flow = source.to(sink)
flow.run()](https://image.slidesharecdn.com/3romanchuk-150412233406-conversion-gate01/85/backend-c-151-320.jpg)





val flow2 = source
.map { x => x.toString }
.map { x => x / 13 }
.to(sink)
flow2.run()](https://image.slidesharecdn.com/3romanchuk-150412233406-conversion-gate01/85/backend-c-156-320.jpg)

val flow2 = source
.map { x => x.toString }
.map { x => x / 13 }
.to(sink)
flow2.run()](https://image.slidesharecdn.com/3romanchuk-150412233406-conversion-gate01/85/backend-c-157-320.jpg)

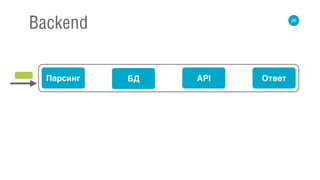
![67
Flow
val request: Source[Request] = ???
def parser: Request => Query = ???
def dbCall: Query => Future[List[Int]] = ???
def apiCall: List[Int] => Future[List[String]] = ???
def buildResponse: List[String] => Response = ???](https://image.slidesharecdn.com/3romanchuk-150412233406-conversion-gate01/85/backend-c-159-320.jpg)
![67
Flow
val request: Source[Request] = ???
def parser: Request => Query = ???
def dbCall: Query => Future[List[Int]] = ???
def apiCall: List[Int] => Future[List[String]] = ???
def buildResponse: List[String] => Response = ???](https://image.slidesharecdn.com/3romanchuk-150412233406-conversion-gate01/85/backend-c-160-320.jpg)
![67
Flow
val request: Source[Request] = ???
def parser: Request => Query = ???
def dbCall: Query => Future[List[Int]] = ???
def apiCall: List[Int] => Future[List[String]] = ???
def buildResponse: List[String] => Response = ???](https://image.slidesharecdn.com/3romanchuk-150412233406-conversion-gate01/85/backend-c-161-320.jpg)
![67
Flow
val request: Source[Request] = ???
def parser: Request => Query = ???
def dbCall: Query => Future[List[Int]] = ???
def apiCall: List[Int] => Future[List[String]] = ???
def buildResponse: List[String] => Response = ???](https://image.slidesharecdn.com/3romanchuk-150412233406-conversion-gate01/85/backend-c-162-320.jpg)
![67
Flow
val request: Source[Request] = ???
def parser: Request => Query = ???
def dbCall: Query => Future[List[Int]] = ???
def apiCall: List[Int] => Future[List[String]] = ???
def buildResponse: List[String] => Response = ???](https://image.slidesharecdn.com/3romanchuk-150412233406-conversion-gate01/85/backend-c-163-320.jpg)
![67
Flow
val request: Source[Request] = ???
def parser: Request => Query = ???
def dbCall: Query => Future[List[Int]] = ???
def apiCall: List[Int] => Future[List[String]] = ???
def buildResponse: List[String] => Response = ???](https://image.slidesharecdn.com/3romanchuk-150412233406-conversion-gate01/85/backend-c-164-320.jpg)
![67
Flow
val request: Source[Request] = ???
def parser: Request => Query = ???
def dbCall: Query => Future[List[Int]] = ???
def apiCall: List[Int] => Future[List[String]] = ???
def buildResponse: List[String] => Response = ???](https://image.slidesharecdn.com/3romanchuk-150412233406-conversion-gate01/85/backend-c-165-320.jpg)
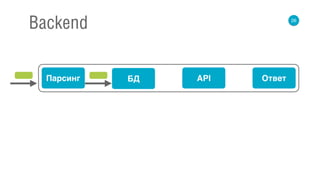
![67
Flow
val request: Source[Request] = ???
def parser: Request => Query = ???
def dbCall: Query => Future[List[Int]] = ???
def apiCall: List[Int] => Future[List[String]] = ???
def buildResponse: List[String] => Response = ???
val flow3 = request
.map(parser)
.mapAsync(dbCall)
.mapAsync(apiCall)
.map(buildResponse)
.to(response)](https://image.slidesharecdn.com/3romanchuk-150412233406-conversion-gate01/85/backend-c-166-320.jpg)
![67
Flow
val request: Source[Request] = ???
def parser: Request => Query = ???
def dbCall: Query => Future[List[Int]] = ???
def apiCall: List[Int] => Future[List[String]] = ???
def buildResponse: List[String] => Response = ???
val flow3 = request
.map(parser)
.mapAsync(dbCall)
.mapAsync(apiCall)
.map(buildResponse)
.to(response)](https://image.slidesharecdn.com/3romanchuk-150412233406-conversion-gate01/85/backend-c-167-320.jpg)
![67
Flow
val request: Source[Request] = ???
def parser: Request => Query = ???
def dbCall: Query => Future[List[Int]] = ???
def apiCall: List[Int] => Future[List[String]] = ???
def buildResponse: List[String] => Response = ???
val flow3 = request
.map(parser)
.mapAsync(dbCall)
.mapAsync(apiCall)
.map(buildResponse)
.to(response)](https://image.slidesharecdn.com/3romanchuk-150412233406-conversion-gate01/85/backend-c-168-320.jpg)
![67
Flow
val request: Source[Request] = ???
def parser: Request => Query = ???
def dbCall: Query => Future[List[Int]] = ???
def apiCall: List[Int] => Future[List[String]] = ???
def buildResponse: List[String] => Response = ???
val flow3 = request
.map(parser)
.mapAsync(dbCall)
.mapAsync(apiCall)
.map(buildResponse)
.to(response)](https://image.slidesharecdn.com/3romanchuk-150412233406-conversion-gate01/85/backend-c-169-320.jpg)
![67
Flow
val request: Source[Request] = ???
def parser: Request => Query = ???
def dbCall: Query => Future[List[Int]] = ???
def apiCall: List[Int] => Future[List[String]] = ???
def buildResponse: List[String] => Response = ???
val flow3 = request
.map(parser)
.mapAsync(dbCall)
.mapAsync(apiCall)
.map(buildResponse)
.to(response)](https://image.slidesharecdn.com/3romanchuk-150412233406-conversion-gate01/85/backend-c-170-320.jpg)
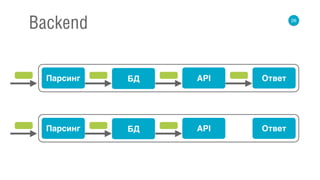
![67
Flow
val request: Source[Request] = ???
def parser: Request => Query = ???
def dbCall: Query => Future[List[Int]] = ???
def apiCall: List[Int] => Future[List[String]] = ???
def buildResponse: List[String] => Response = ???
val flow3 = request
.map(parser)
.mapAsync(dbCall)
.mapAsync(apiCall)
.map(buildResponse)
.to(response)](https://image.slidesharecdn.com/3romanchuk-150412233406-conversion-gate01/85/backend-c-171-320.jpg)
![67
Flow
val request: Source[Request] = ???
def parser: Request => Query = ???
def dbCall: Query => Future[List[Int]] = ???
def apiCall: List[Int] => Future[List[String]] = ???
def buildResponse: List[String] => Response = ???
val flow3 = request
.map(parser)
.mapAsync(dbCall)
.mapAsync(apiCall)
.map(buildResponse)
.to(response)](https://image.slidesharecdn.com/3romanchuk-150412233406-conversion-gate01/85/backend-c-172-320.jpg)
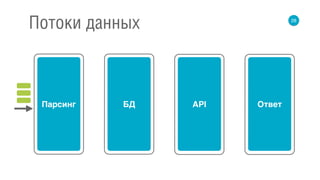
![67
Flow
val request: Source[Request] = ???
def parser: Request => Query = ???
def dbCall: Query => Future[List[Int]] = ???
def apiCall: List[Int] => Future[List[String]] = ???
def buildResponse: List[String] => Response = ???
val flow3 = request
.map(parser)
.mapAsync(dbCall)
.mapAsync(apiCall)
.map(buildResponse)
.to(response)](https://image.slidesharecdn.com/3romanchuk-150412233406-conversion-gate01/85/backend-c-173-320.jpg)















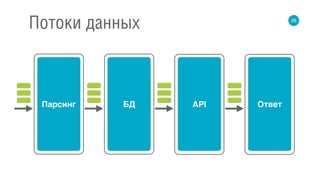
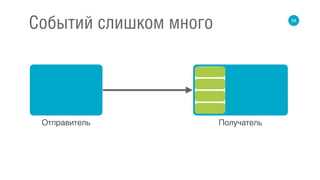
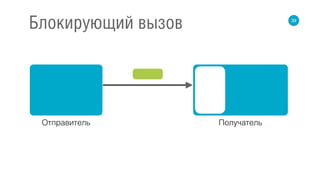
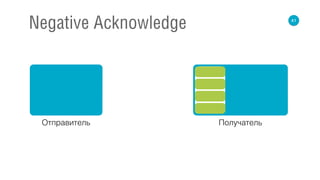
Документ освещает принципы реактивных потоков и их применение в высокопроизводительных backend-системах. Обсуждаются модели синхронного и асинхронного взаимодействия, а также проблемы, связанные с обработкой данных и управлением событиями. Приведены примеры, касающиеся реализации на различных библиотеках, таких как RxJava и Akka Stream.























































































