Download as PDF, PPTX










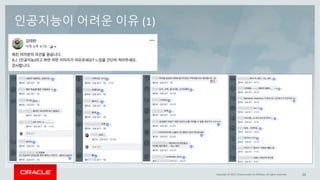
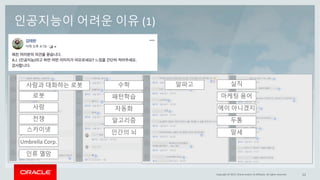
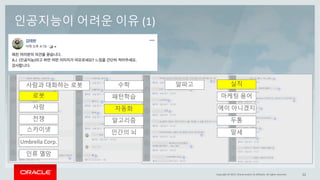

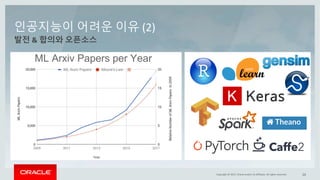










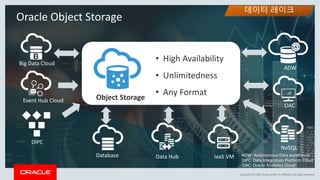
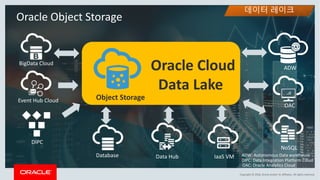
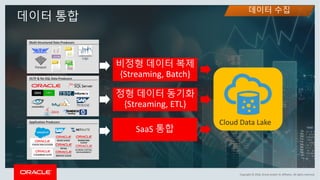
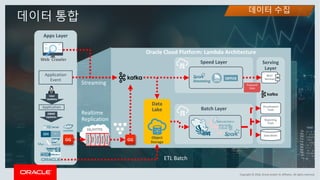
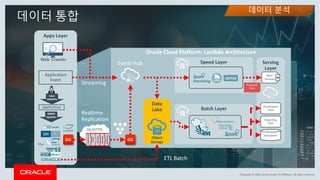

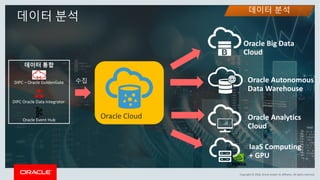
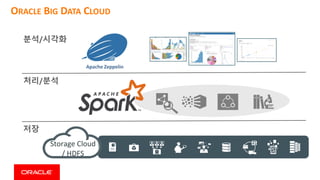
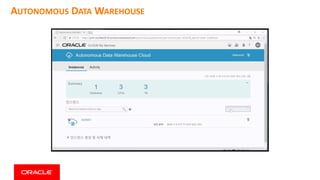
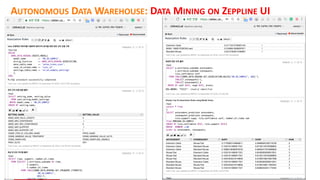
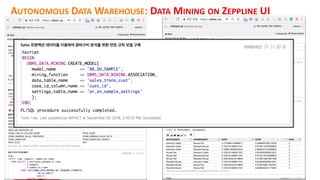
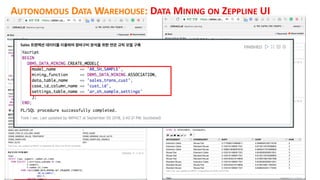

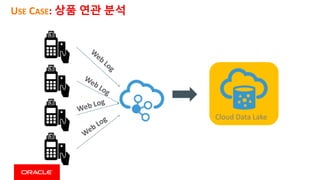
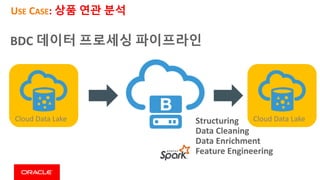


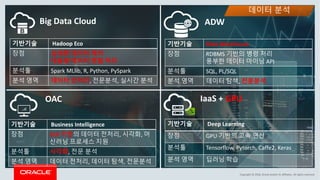
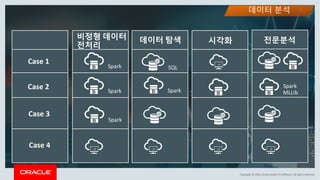
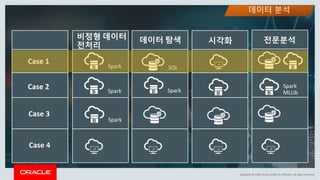
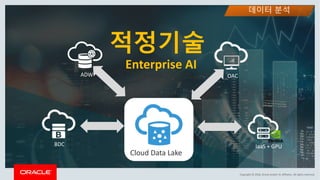
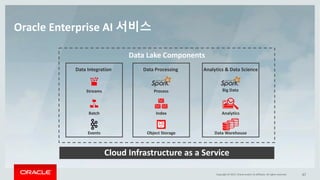



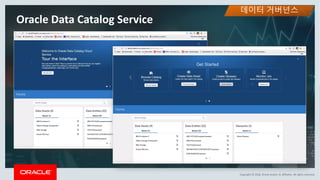
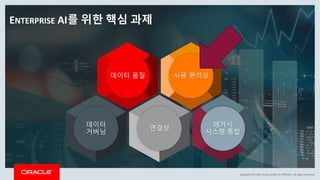
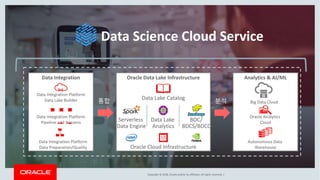
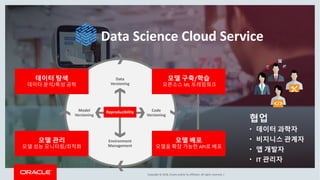
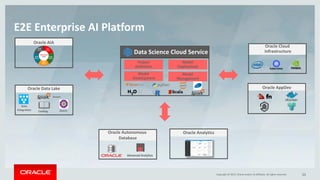
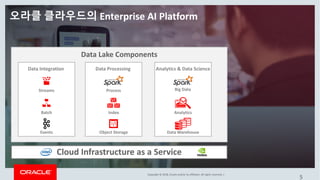
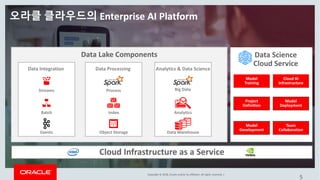

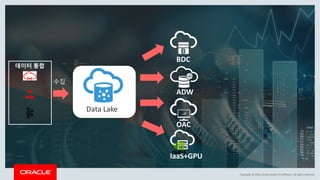
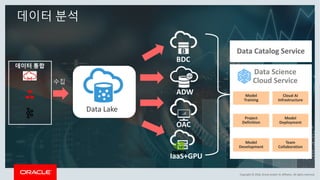




This document discusses enterprise artificial intelligence (AI) and Oracle's cloud AI platform. It begins by providing background on the AI revolution and increasing data generation. It then discusses Oracle's cloud AI platform and services for enterprise AI, including a data lake, data integration, analysis, and machine learning/deep learning tools. As an example, it outlines using the platform for product association analysis based on transaction log data from retail stores. The document emphasizes that Oracle's cloud AI platform provides tools and services suited for different types of data and analysis.

















![【旧版】Oracle Cloud Infrastructure:サービス概要のご紹介 [2020年6月版]](https://cdn.slidesharecdn.com/ss_thumbnails/ocioverview200601dl-200601023800-thumbnail.jpg?width=640&height=640&fit=bounds)

![[非公開]Oracle Cloud Infrastructure Classic ネットワーク機能詳細](https://cdn.slidesharecdn.com/ss_thumbnails/ociclassicnetwork2-171222085226-thumbnail.jpg?width=640&height=640&fit=bounds)











![[발표본] 너의 과제는 클라우드에 있어_KTDS_김동현_20250524.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/ktds20250524-250804103857-22eedc71-thumbnail.jpg?width=640&height=640&fit=bounds)
![[금융사를 위한 AWS Generative AI Day 2023] 8_Wrap-up과 QnA_금융사의 AI와 관련하...](https://cdn.slidesharecdn.com/ss_thumbnails/8wrap-upqnaaiaws-230818064528-6153c04e-thumbnail.jpg?width=640&height=640&fit=bounds)
![[금융사를 위한 AWS Generative AI Day 2023] 7_다양한 AI 워크로드를 위한 최적의 ...](https://cdn.slidesharecdn.com/ss_thumbnails/7aiacceleratorawsaws-230818064304-2a40fb19-thumbnail.jpg?width=640&height=640&fit=bounds)




![제 14회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [BICS팀] : Boaz Industry Classification Standard](https://cdn.slidesharecdn.com/ss_thumbnails/bics-210806012608-thumbnail.jpg?width=640&height=640&fit=bounds)
![[AWS summit 2019] 마이크로 서비스 패턴 데이터 베이스](https://cdn.slidesharecdn.com/ss_thumbnails/awssummit2019jkhkyd20190417final-191217131802-thumbnail.jpg?width=640&height=640&fit=bounds)




![[AWS Dev Day] 인공지능 / 기계 학습 | AWS 기반 기계 학습 자동화 및 최적화를 위한 실전 기법 - 남궁영환 AWS 솔루션...](https://cdn.slidesharecdn.com/ss_thumbnails/20190926-devday-aiml3-younghwan-final-190930020120-thumbnail.jpg?width=640&height=640&fit=bounds)





![[OCI 새소식] OCI Burstable Instance](https://cdn.slidesharecdn.com/ss_thumbnails/bustablevm-210419141804-thumbnail.jpg?width=640&height=640&fit=bounds)






















