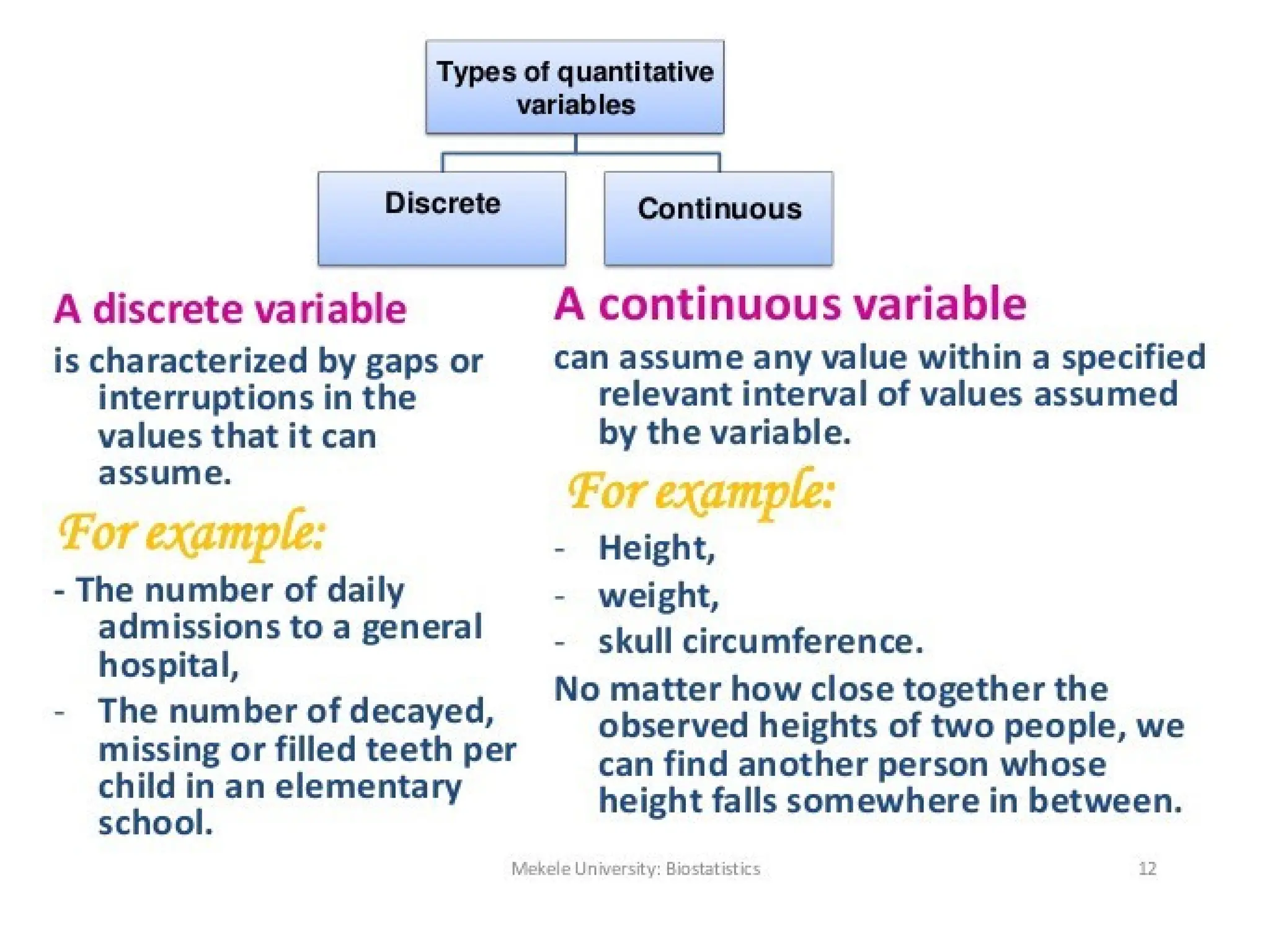
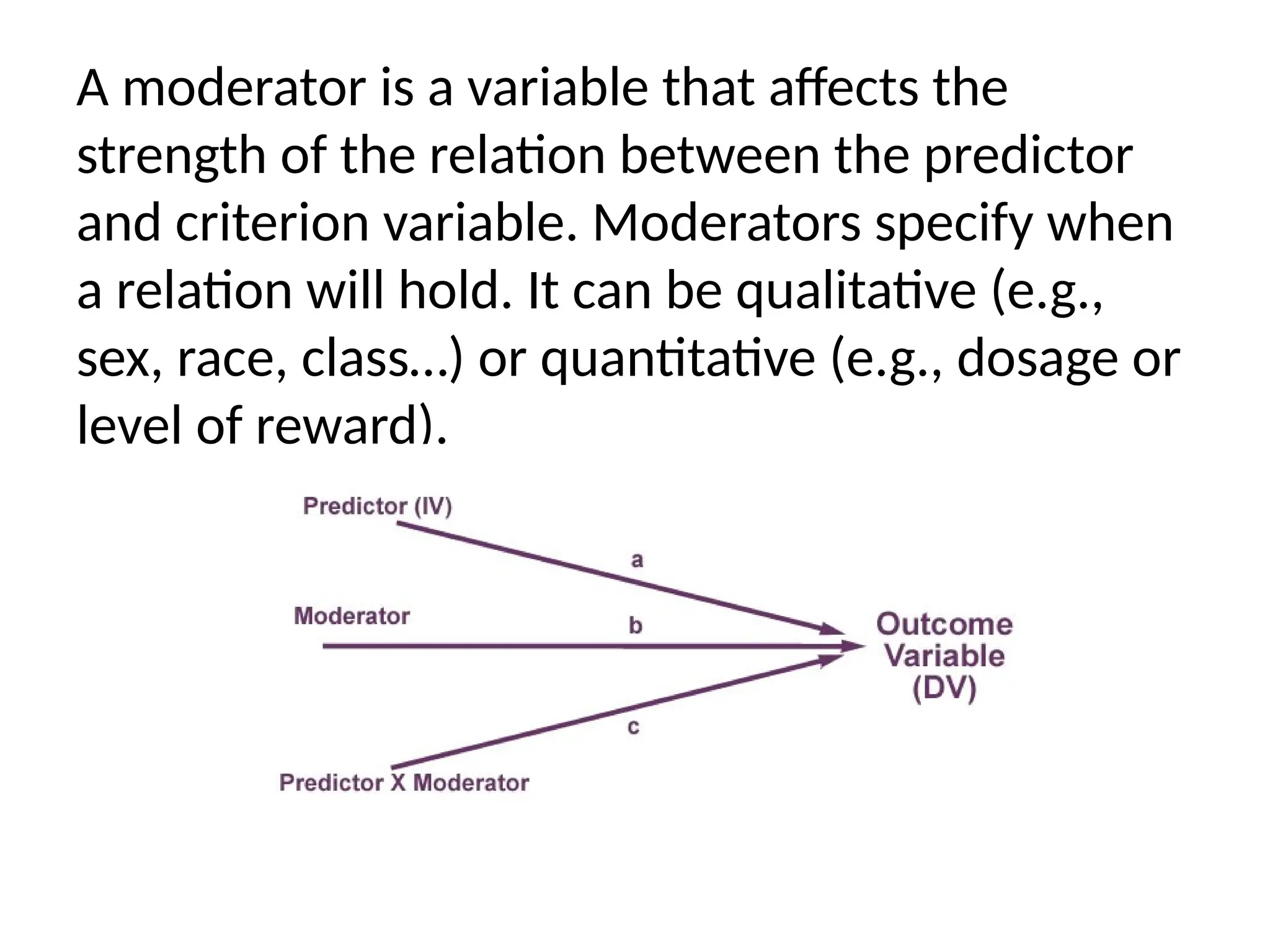
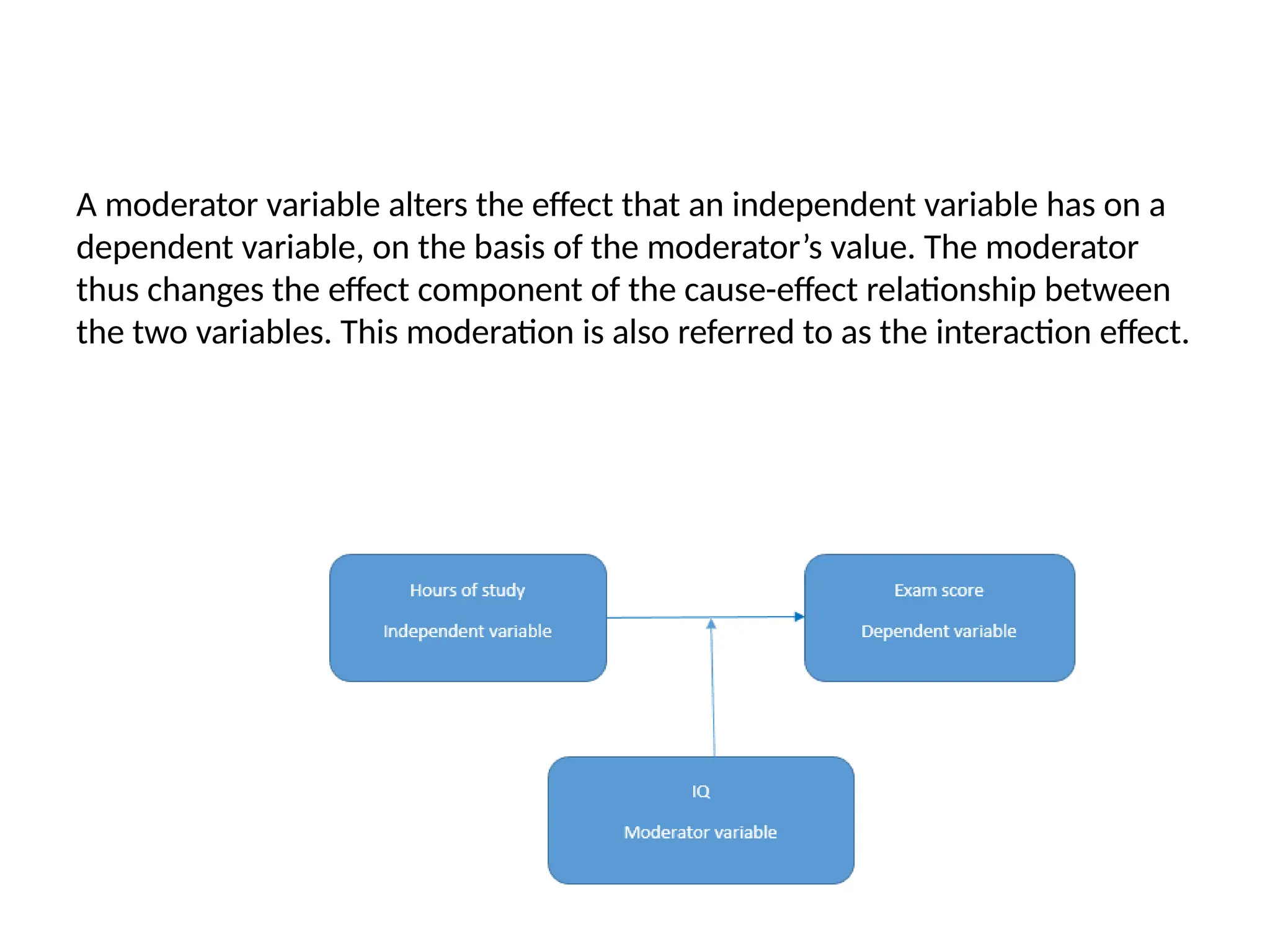
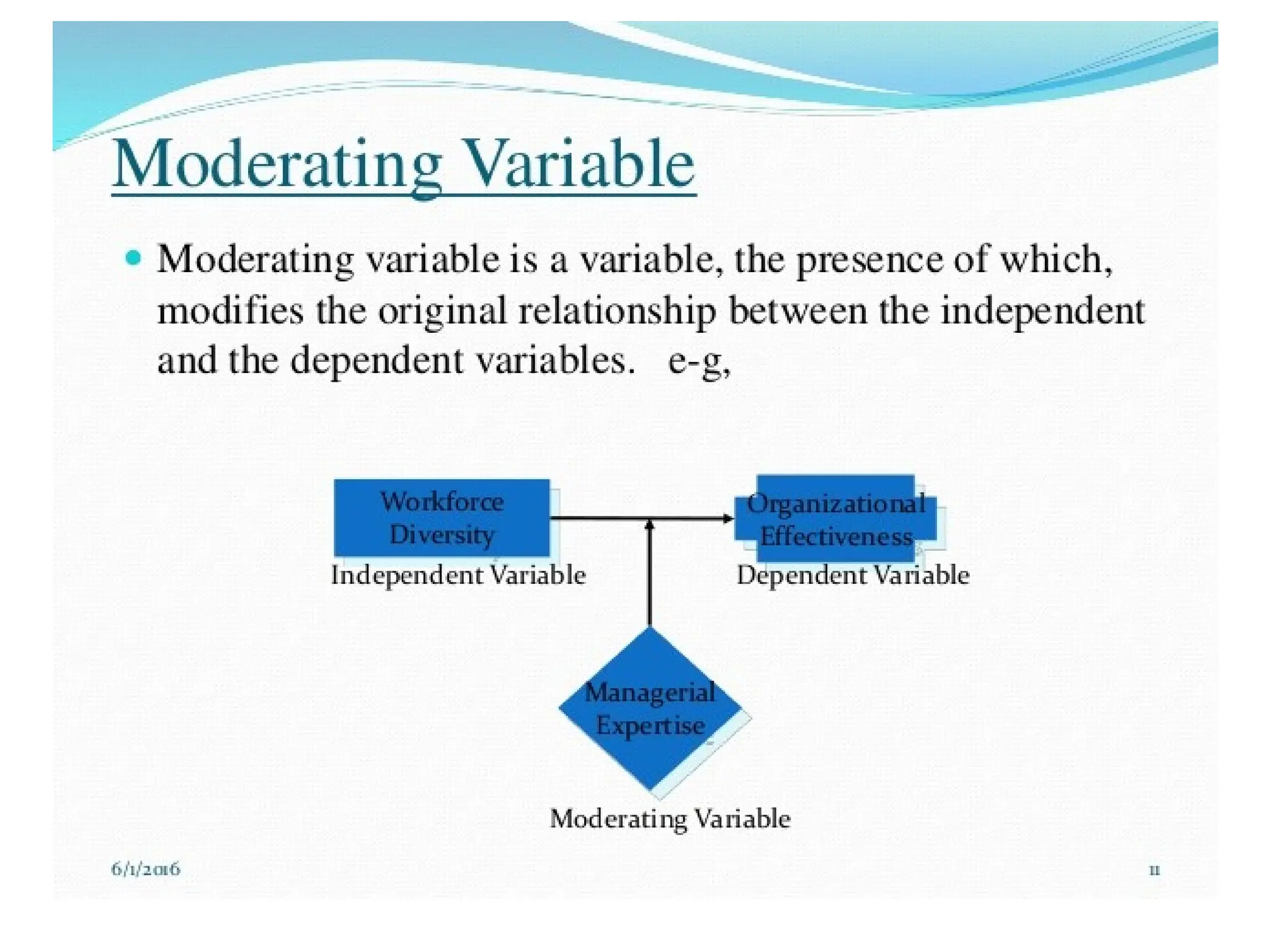
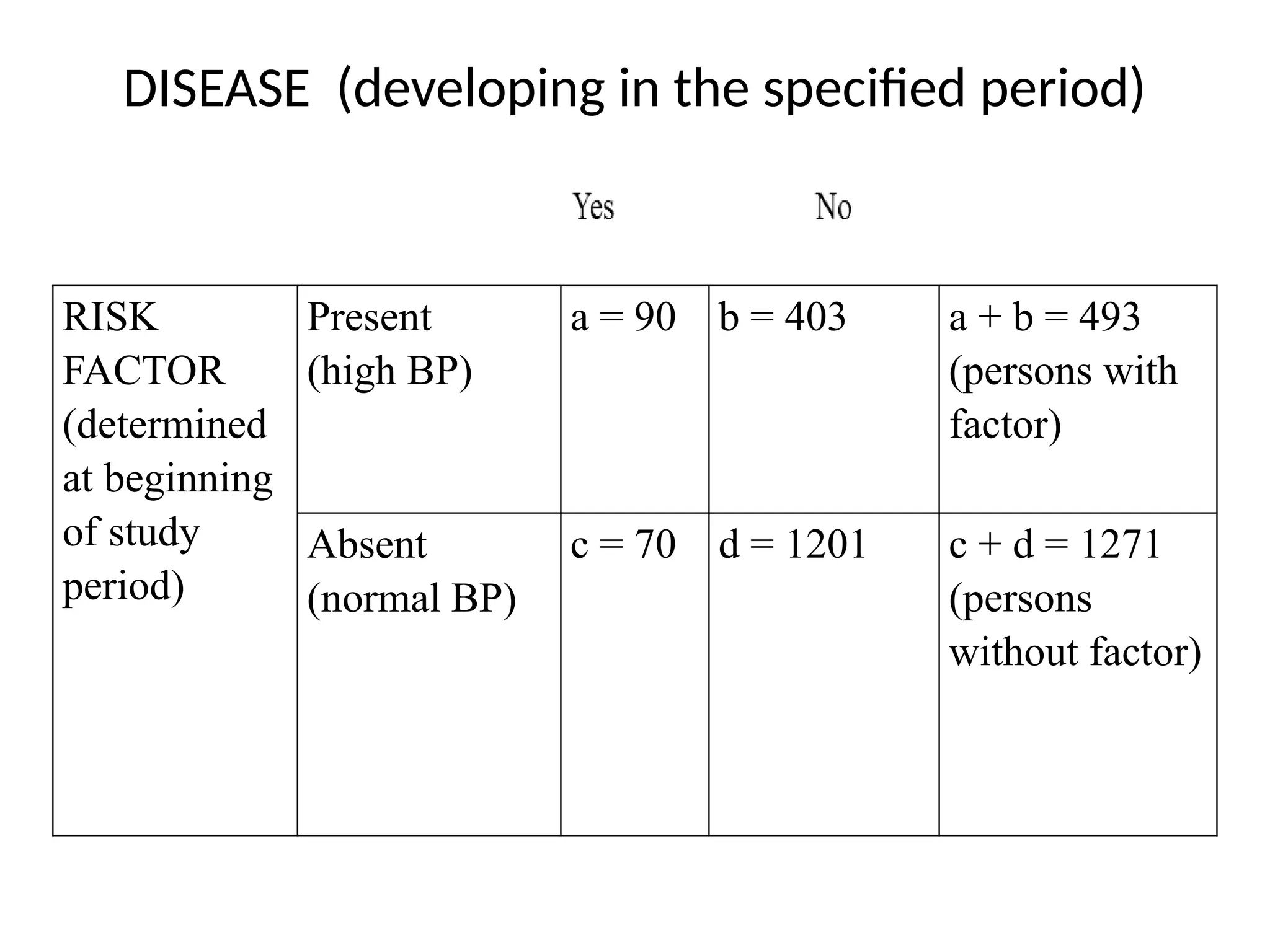
The document discusses various types of variables used in research, including independent, dependent, control, and extraneous variables, and their relationships in experimental designs. It emphasizes the importance of distinguishing between these variables to ensure valid results, as well as explaining concepts of relative risk in epidemiological studies. Additionally, it provides examples illustrating how these variables interact and affect study outcomes.