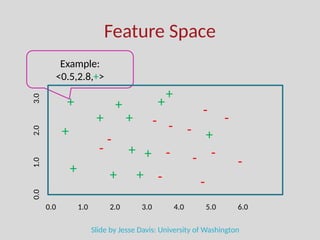
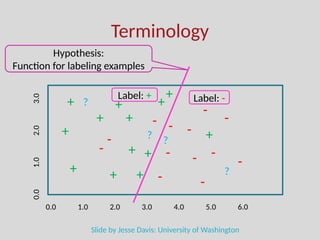
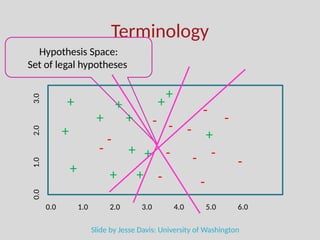
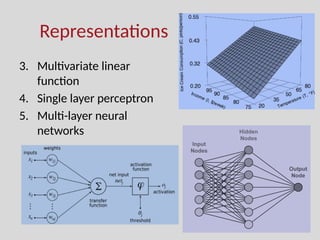
The document discusses the foundations of machine learning, focusing on inductive learning, hypothesis spaces, and inductive bias. It explains key concepts such as classification, regression, and the importance of features, as well as the challenges posed by generalization, overfitting, and underfitting. Additionally, it touches on the need for assumptions and optimal hypothesis spaces in the learning process.