Download to read offline





![Algorithm 1
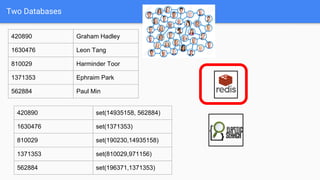
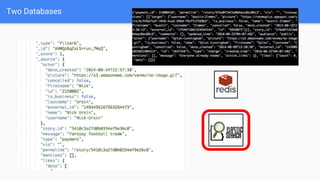
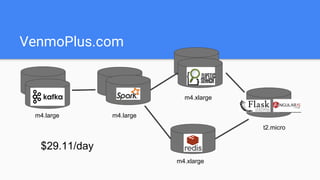
Shortest distance -> intersection of sets (friend lists)
● 1st degree friends of A ∩ 1st degree friends of B == [] ?
● 2nd degree friends of A ∩ 1st degree friends of B == []?](https://image.slidesharecdn.com/0629venmoplus-160629143239/85/0629venmoplus-10-320.jpg)
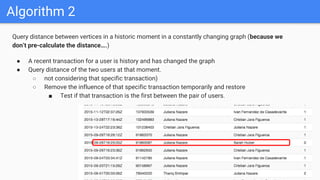
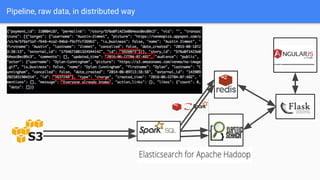


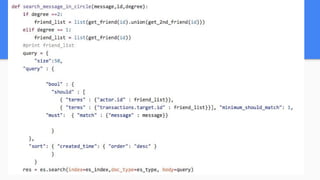

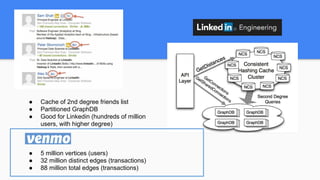
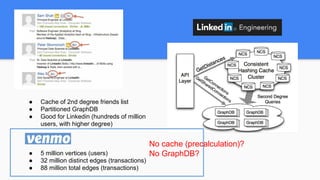

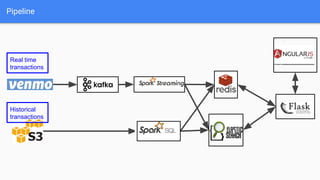
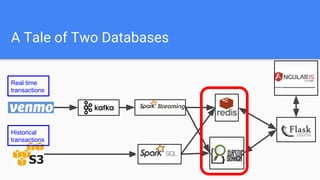
Introducing VenmoPlus.com, a service that allows users to explore their Venmo network in more depth. The document discusses the challenges of calculating and querying the graph distance between users in real-time as the graph is constantly changing. It describes how the service uses two databases - a real-time database to track new transactions and a historical database to store older transaction data. It also discusses algorithms and optimizations used to query distances and recommend connections between users efficiently.

















![[Data Innovation Summit 2015] Belga Big Content Platform](https://cdn.slidesharecdn.com/ss_thumbnails/disbelgabigdata-150330084608-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)



































































