Download as PDF, PPTX















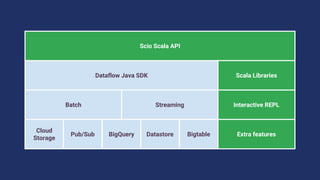
![Scio
Ecclesiastical Latin IPA: /ˈʃi.o/, [ˈʃiː.o], [ˈʃi.i̯o]
Verb: I can, know, understand, have knowledge.](https://image.slidesharecdn.com/sciosbtb-161112004437/85/Scio-A-Scala-API-for-Google-Cloud-Dataflow-Apache-Beam-19-320.jpg)

![WordCount
val sc = ScioContext()
sc.textFile("shakespeare.txt")
.flatMap { _
.split("[^a-zA-Z']+")
.filter(_.nonEmpty)
}
.countByValue
.saveAsTextFile("wordcount.txt")
sc.close()](https://image.slidesharecdn.com/sciosbtb-161112004437/85/Scio-A-Scala-API-for-Google-Cloud-Dataflow-Apache-Beam-21-320.jpg)
![PageRank
def pageRank(in: SCollection[(String, String)]) = {
val links = in.groupByKey()
var ranks = links.mapValues(_ => 1.0)
for (i <- 1 to 10) {
val contribs = links.join(ranks).values
.flatMap { case (urls, rank) =>
val size = urls.size
urls.map((_, rank / size))
}
ranks = contribs.sumByKey.mapValues((1 - 0.85) + 0.85 * _)
}
ranks
}](https://image.slidesharecdn.com/sciosbtb-161112004437/85/Scio-A-Scala-API-for-Google-Cloud-Dataflow-Apache-Beam-22-320.jpg)

![Type safe BigQuery
Macro generated case classes, schemas and converters
@BigQuery.fromQuery("SELECT id, name FROM [users] WHERE ...")
class User // look mom no code!
sc.typedBigQuery[User]().map(u => (u.id, u.name))
@BigQuery.toTable
case class Score(id: String, score: Double)
data.map(kv => Score(kv._1, kv._2)).saveAsTypedBigQuery("table")](https://image.slidesharecdn.com/sciosbtb-161112004437/85/Scio-A-Scala-API-for-Google-Cloud-Dataflow-Apache-Beam-24-320.jpg)
![Future based orchestration
// Job 1
val f: Future[Tap[String]] = data1.saveAsTextFile("output")
sc1.close() // submit job
val t: Tap[String] = Await.result(f)
t.value.foreach(println) // Iterator[String]
// Job 2
val sc2 = ScioContext(options)
val data2: SCollection[String] = t.open(sc2)](https://image.slidesharecdn.com/sciosbtb-161112004437/85/Scio-A-Scala-API-for-Google-Cloud-Dataflow-Apache-Beam-26-320.jpg)
![DistCache
val sw = sc.distCache("gs://bucket/stopwords.txt") { f =>
Source.fromFile(f).getLines().toSet
}
sc.textFile("gs://bucket/shakespeare.txt")
.flatMap { _
.split("[^a-zA-Z']+")
.filter(w => w.nonEmpty && !sw().contains(w))
}
.countByValue
.saveAsTextFile("wordcount.txt")](https://image.slidesharecdn.com/sciosbtb-161112004437/85/Scio-A-Scala-API-for-Google-Cloud-Dataflow-Apache-Beam-27-320.jpg)




![Fan Insights
● Listener stats
[artist|track] ×
[context|geography|demography] ×
[day|week|month]
● BigQuery, GCS, Datastore
● TBs daily
● 150+ Java jobs to < 10 Scio jobs](https://image.slidesharecdn.com/sciosbtb-161112004437/85/Scio-A-Scala-API-for-Google-Cloud-Dataflow-Apache-Beam-32-320.jpg)


![BigDiffy
● Pairwise field-level statistical diff
● Diff 2 SCollection[T] given keyFn: T => String
● T: Avro, BigQuery, Protobuf
● Field level Δ - numeric, string, vector
● Δ statistics - min, max, μ, σ, etc.
● Non-deterministic fields
○ ignore field
○ treat "repeated" field as unordered list
Part of github.com/spotify/ratatool](https://image.slidesharecdn.com/sciosbtb-161112004437/85/Scio-A-Scala-API-for-Google-Cloud-Dataflow-Apache-Beam-35-320.jpg)

![Pairwise field-level deltas
val lKeyed = lhs.keyBy(keyFn)
val rKeyed = rhs.keyBy(keyFn)
val deltas = (lKeyed outerJoin rKeyed).map { case (k, (lOpt, rOpt)) =>
(lOpt, rOpt) match {
case (Some(l), Some(r)) =>
val ds = diffy(l, r) // Seq[Delta]
val dt = if (ds.isEmpty) SAME else DIFFERENT
(k, (ds, dt))
case (_, _) =>
val dt = if (lOpt.isDefined) MISSING_RHS else MISSING_LHS
(k, (Nil, dt))
}
}](https://image.slidesharecdn.com/sciosbtb-161112004437/85/Scio-A-Scala-API-for-Google-Cloud-Dataflow-Apache-Beam-37-320.jpg)
![Summing deltas
import com.twitter.algebird._
// convert deltas to map of (field → summable stats)
def deltasToMap(ds: Seq[Delta], dt: DeltaType)
: Map[String, (Long, Option[(DeltaType, Min[Double], Max[Double], Moments)])] = {
// ...
}
deltas
.map { case (_, (ds, dt)) => deltasToMap(ds, dt) }
.sum // Semigroup!](https://image.slidesharecdn.com/sciosbtb-161112004437/85/Scio-A-Scala-API-for-Google-Cloud-Dataflow-Apache-Beam-38-320.jpg)


![Serialization
● Data ser/de
○ Scalding, Spark and Storm uses Kryo and Chill
○ Dataflow/Beam requires explicit Coder[T]
Sometimes inferable via Guava TypeToken
○ ClassTag to the rescue, fallback to Kryo/Chill
● Lambda ser/de
○ ClosureCleaner
○ Serializable and @transient lazy val](https://image.slidesharecdn.com/sciosbtb-161112004437/85/Scio-A-Scala-API-for-Google-Cloud-Dataflow-Apache-Beam-41-320.jpg)
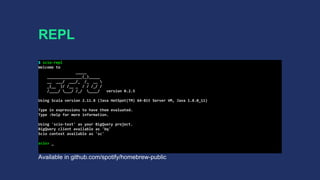
![REPL
● Spark REPL transports lambda bytecode via HTTP
● Dataflow requires job jar for execution (no master)
● Custom class loader and ILoop
● Interpreted classes → job jar → job submission
● SCollection[T]#closeAndCollect(): Iterator[T]
to mimic Spark actions](https://image.slidesharecdn.com/sciosbtb-161112004437/85/Scio-A-Scala-API-for-Google-Cloud-Dataflow-Apache-Beam-42-320.jpg)



![What's Next?
● Better streaming support [#163]
● Support Beam 0.3.0-incubating
● Support other runners
● Donate to Beam as Scala DSL [BEAM-302]](https://image.slidesharecdn.com/sciosbtb-161112004437/85/Scio-A-Scala-API-for-Google-Cloud-Dataflow-Apache-Beam-46-320.jpg)


This document summarizes Scio, a Scala API for Google Cloud Dataflow and Apache Beam. Scio provides a DSL for writing pipelines in Scala to process large datasets. It originated from Scalding and was moved to use Dataflow/Beam for its managed service, integration with Google Cloud Platform services, and unified batch and streaming model. Scio aims to make Beam concepts accessible from Scala and provides features like type-safe BigQuery and Bigtable access, distributed caching, and future-based job orchestration to make Scala pipelines on Dataflow/Beam more productive.




















![Naver속도의, 속도에 의한, 속도를 위한 몽고DB (네이버 컨텐츠검색과 몽고DB) [Naver]](https://cdn.slidesharecdn.com/ss_thumbnails/naver-190916181334-thumbnail.jpg?width=640&height=640&fit=bounds)








































![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)





