More Related Content

PPTX
PRML 5.5.6-5.6 畳み込みネットワーク(CNN)・ソフト重み共有・混合密度ネットワーク 
PPTX

PDF

PPTX

PPTX

PDF
クラシックな機械学習の入門 6. 最適化と学習アルゴリズム 
PDF
クラシックな機械学習の入門 10. マルコフ連鎖モンテカルロ 法 
PDF
Similar to Prml nn

PPTX
数理最適化と機械学習の�融合アプローチ�-分類と新しい枠組み-(改訂版) 
PPTX
Learning sparse neural networks through L0 regularization 
PDF

PDF

PPTX

PDF

PDF

PDF

PDF

PDF

PDF

PDF

PDF
Sparse estimation tutorial 2014 
PDF
スパースモデリング、スパースコーディングとその数理(第11回WBA若手の会) 
PDF
PRML 5.2.1-5.3.3 ニューラルネットワークの学習 (誤差逆伝播) / Training Neural Networks (Backpropa... 
PDF
![[DL Hacks] Deterministic Variational Inference for RobustBayesian Neural Netw...](https://cdn.slidesharecdn.com/ss_thumbnails/adobepdffile2-190628001736-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DL Hacks] Deterministic Variational Inference for RobustBayesian Neural Netw... 
PDF
Casual learning machine learning with_excel_no5 
PDF
PATTERN RECOGNITION AND MACHINE LEARNING (1.1) 
PDF
More from Shota Yasui

PDF

PDF
PaperFriday: The selective labels problem 
PDF
L 05 bandit with causality-公開版 
PDF

PPTX

PDF
Factorization machines with r 
PDF

PDF

PDF
何故あなたの機械学習はビジネスを改善出来ないのか? 
PPTX

PDF
Estimating the effect of advertising with Machine learning 
PDF

PDF

PDF
Prml nn
- 1.
- 2.
- 3.
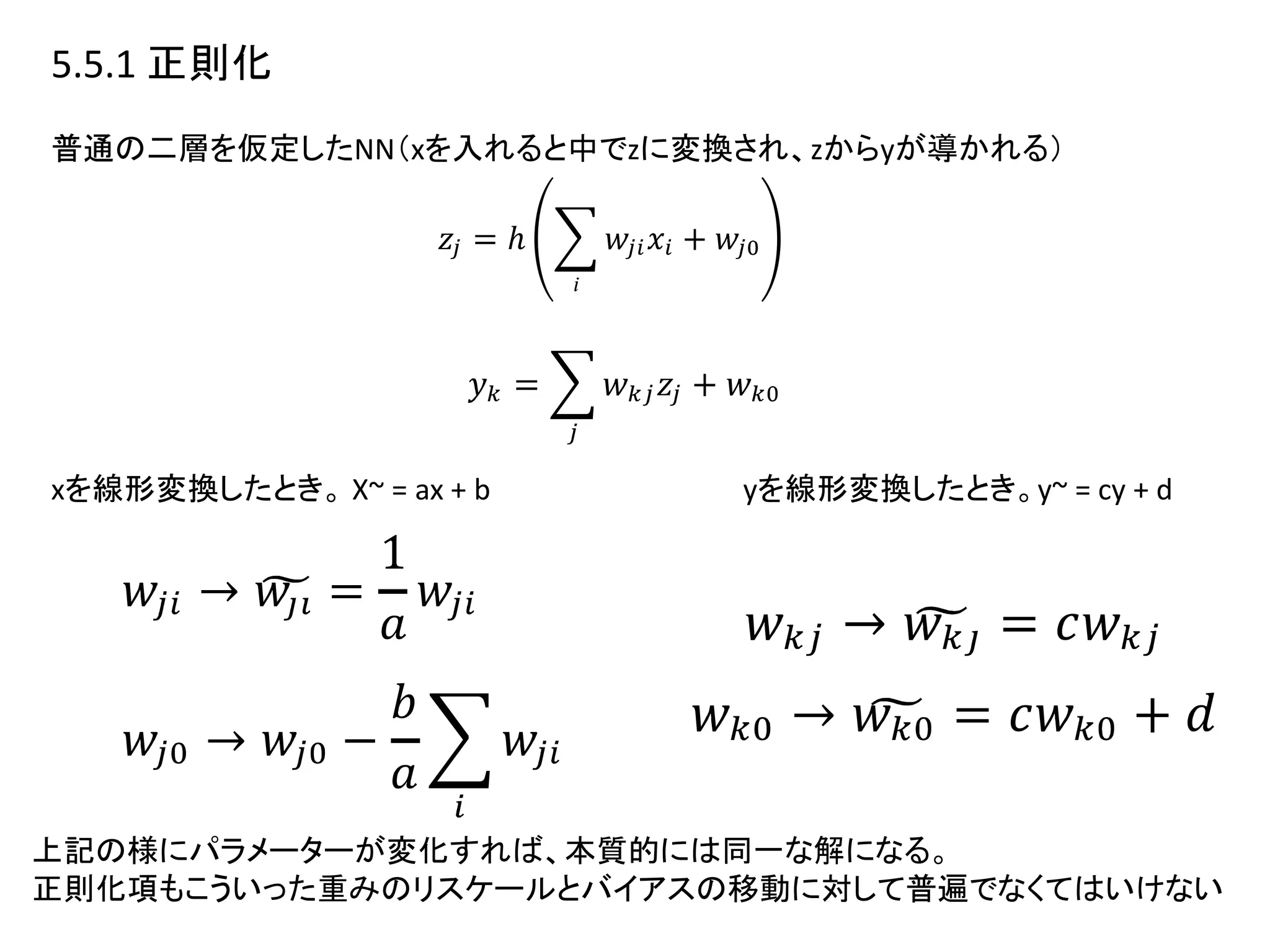
5.5.1 正則化
• 単純な物には限界がある
•ネットワーク写像のスケーリング性質と矛盾しない状態が欲
しい
• データを線形変換した時、線形変換分だけ重みが異なる
等価なネットワークが得られること。
• 正則化はこの性質を持つべき。
• 正則化は入力データが線形変換されても同一の解を持
つべき。
• が、荷重減衰はその性質を持たない。
• スケールアップ分がWTWに入ってしまうから。
- 4.
- 5.
- 6.
- 7.
- 8.
5.5.4 接線伝搬法
• 正則化を使って入力の変換に対する不変性を持たせる。
•入力の変化に対する出力の変化の関数を定義して、それを誤差関数に追加し
て最小化させてしまおうというアイデア。
• 学習時に誤差関数と一緒に出力の変化も重み付きだけど小さくなるので、入力
が変わっても出力が変わりにくくなる。
• λは訓練データに対するフィッティングと不変性のバランスを学習する。
• 実装時にはtは差分で近似。
• 変換が複数ならその分正則化が必要。
変換後のX
変換
変換が微増した時のXの変化分
変換が微増した時のyの変化分
- 9.
- 10.
- 11.
- 12.
- 13.
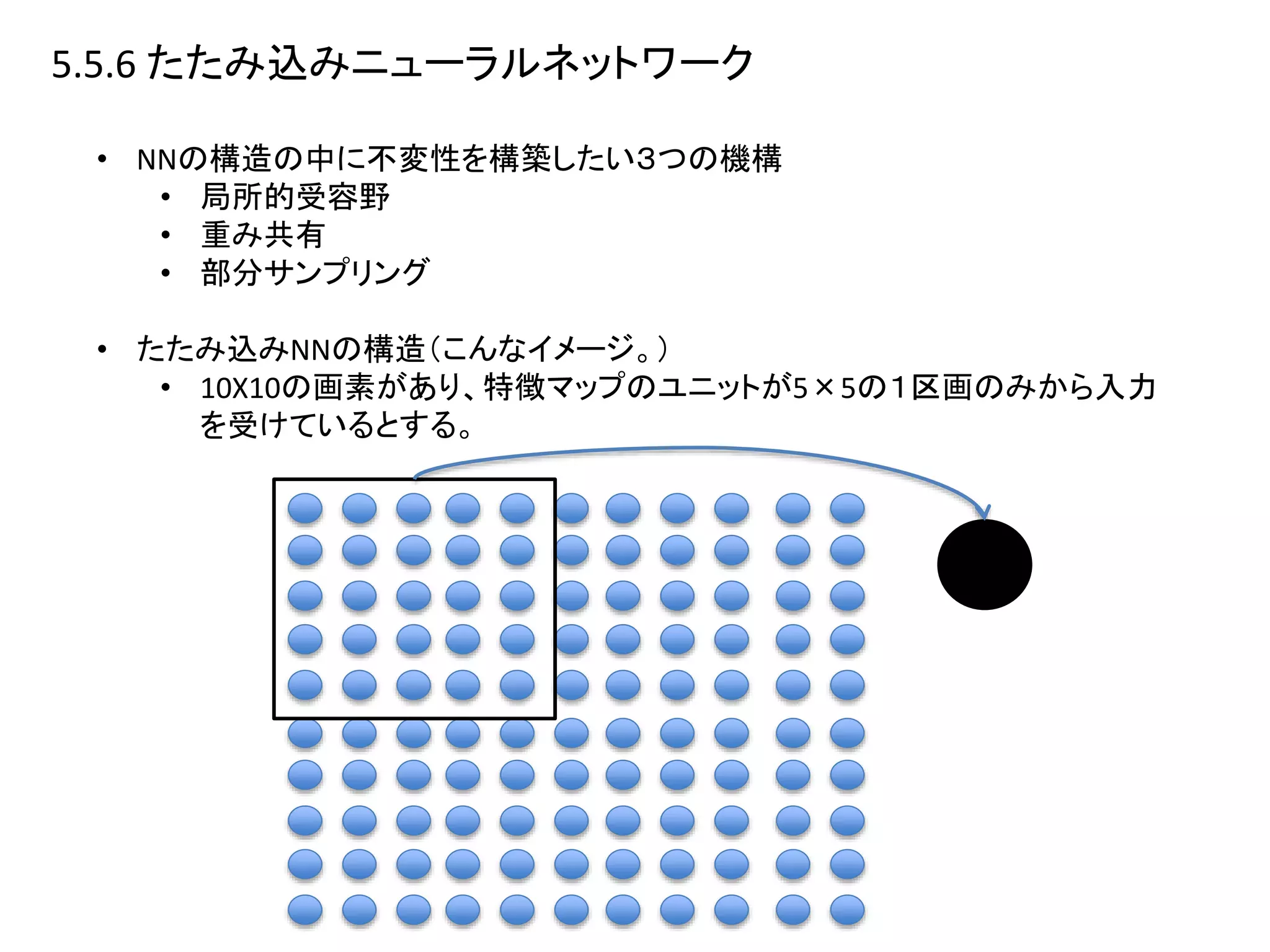
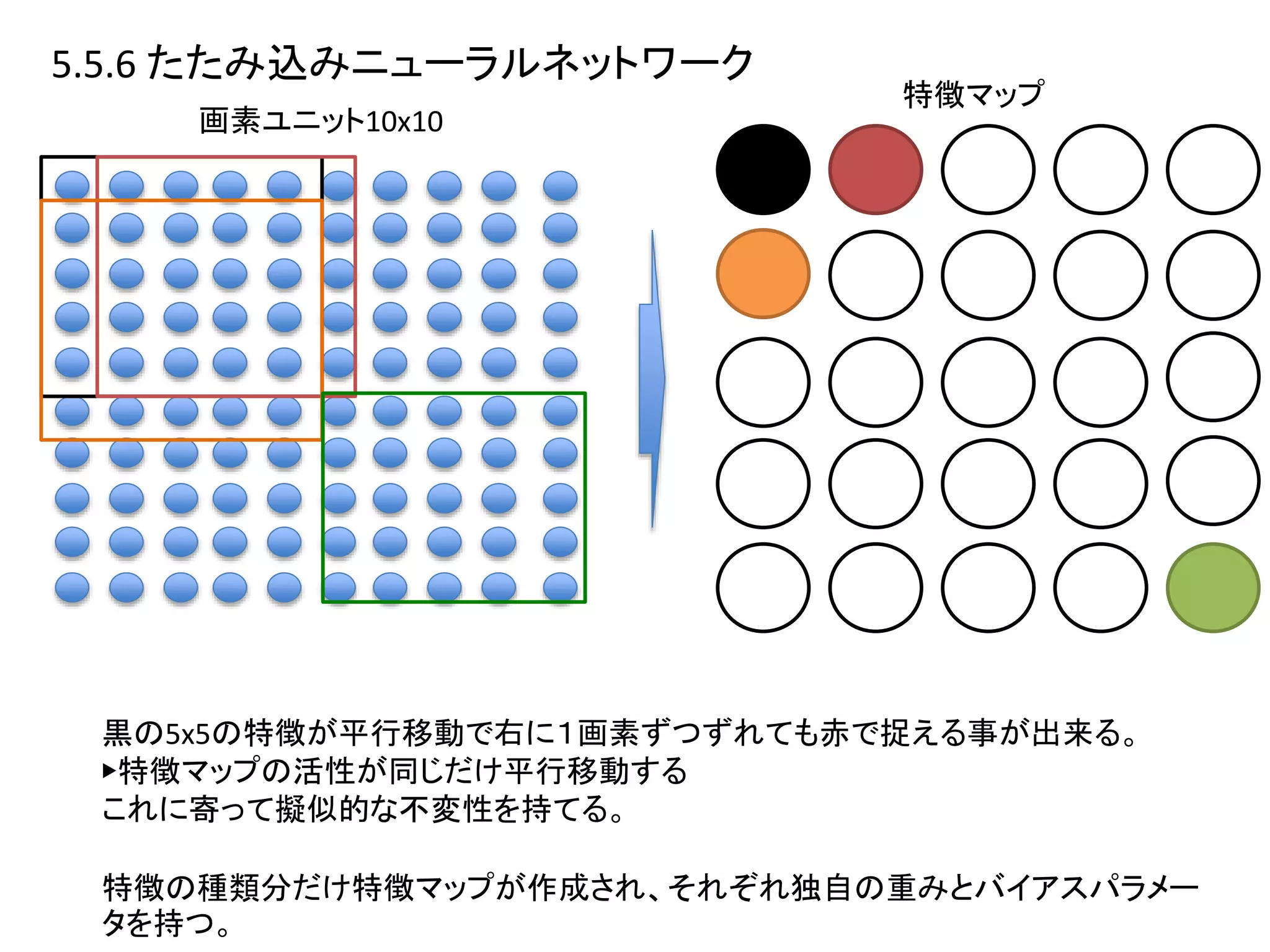
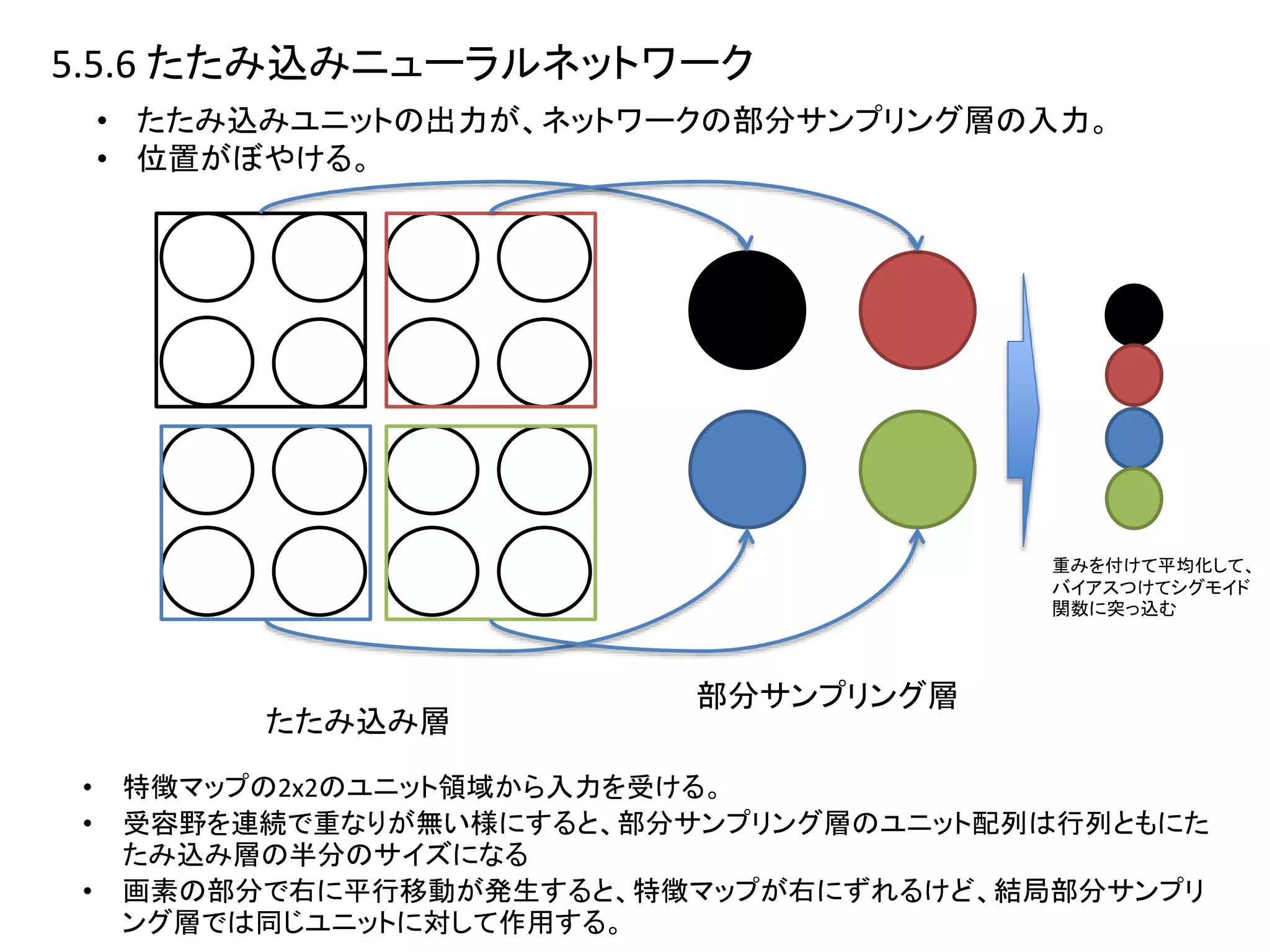
5.5.7 ソフト重み共有
• 重み共有は一定のグループに属する重みを等しくして不変性を作っていた。
•ただ、制限の形が先にわかっていないとだめ。
• =どの位平行移動するってわかっててその制約をつける。
• 正則化の導入に置き換えて、同じグループに属する重みがにた様な値を取り
やすいという状態にしてあげる。▶︎ソフト重み共有
• その際グループ分けや、グループの重みの平均や分散をすべて学習過程の一
部として決定してしまう。
荷重減衰正則化項が重みのガウス事前分布の負の対数尤度と見なせる事から、混合
ガウス分布を用いれば複数グループを表現出来る。
混合係数π
負の対数を取るとこうなる。
後は誤差関数に加えて最小化
- 14.
5.5.7 ソフト重み共有
• 最小化の為に微分する。
•混合係数πを事前分布と見なし、事後分布γを導出。
w-μが0に近づく。が、そのその程度は重みiに対する事後
分布γjに比例した大きさになる。
そのグループに属する可能性が高い程0に近づきやすい。
重みと平均の誤差が、事後確率に従って最小化される。
混合係数の合計は1である必要があるので、ソフトマックス関数が用いられる。
正則化誤差関数をnっぽいので偏微分。平均事後分布へと近づく。
w-μがσjに近づく。
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
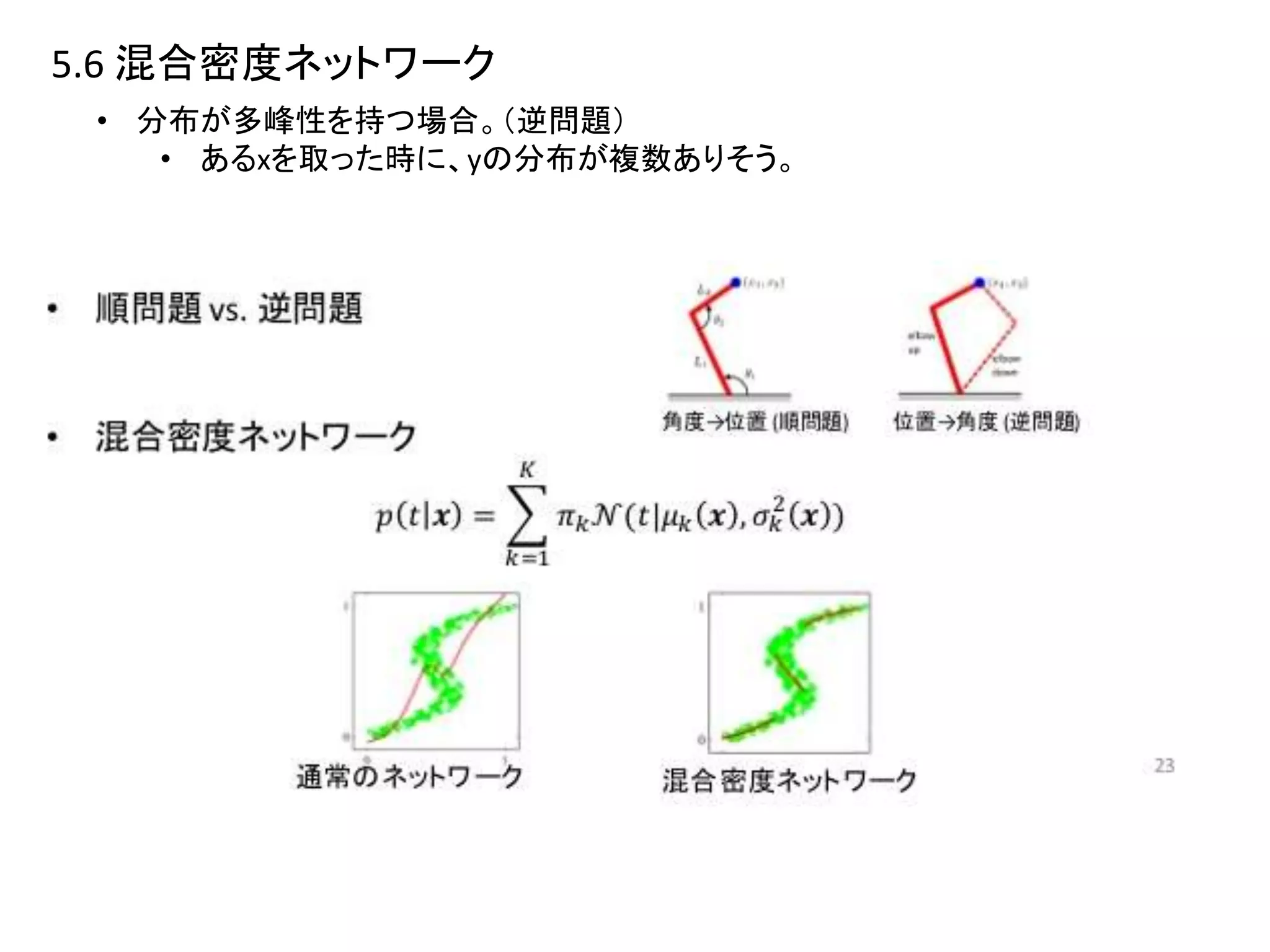
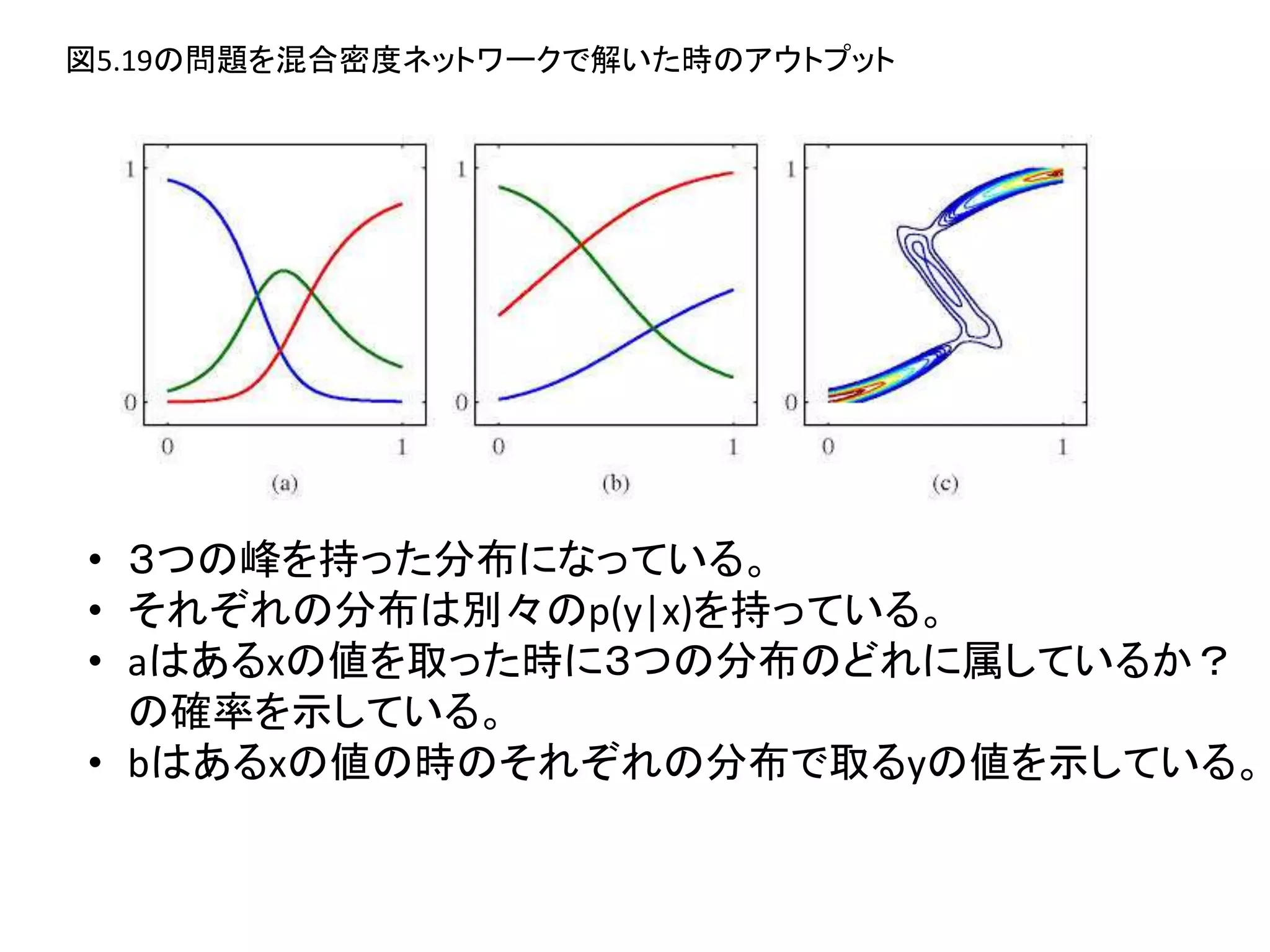
- 23.