Download as PDF, PPTX






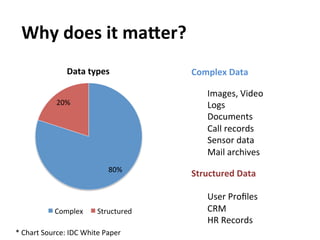


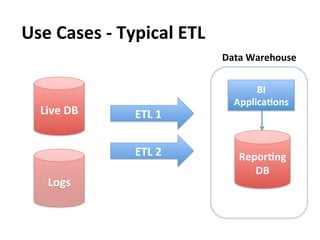
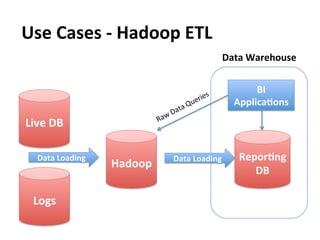







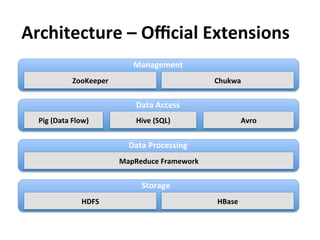
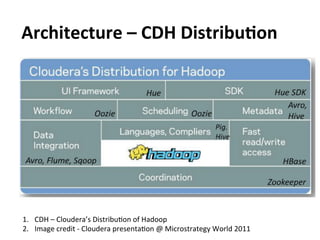

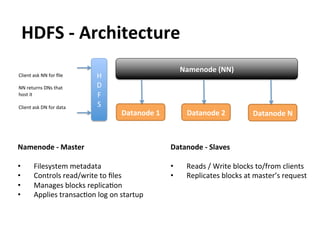


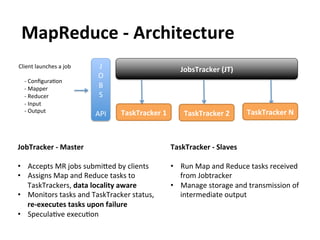
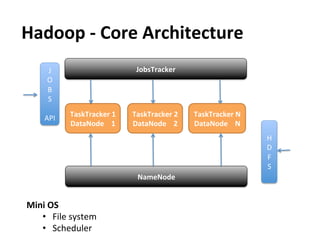



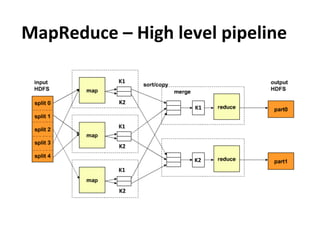
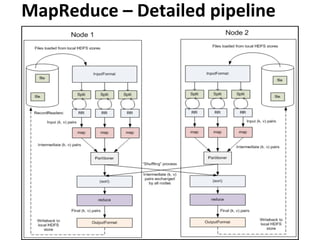
















This document provides an overview and introduction to Hadoop, an open-source framework for storing and processing large datasets in a distributed computing environment. It discusses what Hadoop is, common use cases like ETL and analysis, key architectural components like HDFS and MapReduce, and why Hadoop is useful for solving problems involving "big data" through parallel processing across commodity hardware.












































































