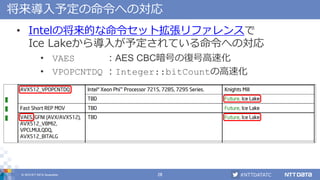
This document discusses optimizations for Java programs to better utilize CPUs, especially newer CPU instructions. It covers how Java code is compiled to bytecode then JIT compiled to machine code at runtime. Improvements in OpenJDK 9-11 are highlighted, including support for Intel AVX-512, fused multiply-add, SHA extensions, and reducing penalties when switching between instruction sets. Optimizing math functions and string processing with SIMD is also discussed.



![© 2019 NTT DATA Corporation 4 #NTTDATATC
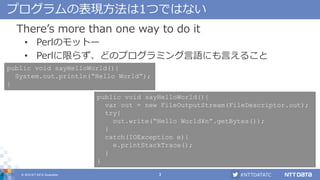
プログラムをCPUで動かす方法も1つではない
処理はCPUが行う
同じプログラムでもCPUの動かし方は何通りも存在する
public void addArray(int[] a, int[] b, int[] result){
for(int i = 0; i < 8; i++){
result[i] = a[i] + b[i];
}
}
mov $7, %rcx # Loop index ([7] to [0])
1:
mov (%rax, %rcx, 4), %esi # Load a[i]
add (%rbx, %rcx, 4), %esi # a[i] + b[i]
mov %esi, (%rdi, %rcx, 4) # Store result
sub $1, %rcx # Decrement index
jns 1b
vmovdqa (%rax), %ymm1 # Load a[]
vpaddd (%rbx), %ymm1, %ymm2 # a[] + b[]
vmovdqa %ymm2, (%rdi) # Store result](https://image.slidesharecdn.com/javamaximizepowercpu2019nttdatasuenaga-190930214721/85/Java-CPU-Java-9-CPU-NTT-2019-2019-09-05-4-320.jpg)










![© 2019 NTT DATA Corporation 15 #NTTDATATC
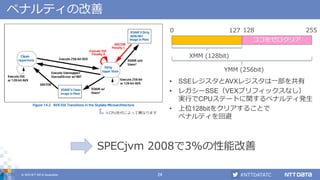
AVX 512:ループ処理のベクタライズ
:
vpaddd 0x50(%r8,%rbx,4),%ymm0,%ymm0
:
vpaddd 0x70(%r8,%rbx,4),%ymm0,%ymm0
:
:
vpaddd 0x90(%r8,%rbp,4),%zmm0,%zmm0
:
vpaddd 0xd0(%r8,%rbp,4),%zmm0,%zmm0
:
public void addArray(int[] a, int[] b, int[] result){
for(int i = 0; i < a.length; i++){
result[i] = a[i] + b[i];
}
}
• ZMMレジスタを使った64バイトずつの処理
• ループ処理がより効率的に!
0x70-0x50=0x20(32バイト) 0xd0-0x90=0x40(64バイト)
AVX 2 AVX 512](https://image.slidesharecdn.com/javamaximizepowercpu2019nttdatasuenaga-190930214721/85/Java-CPU-Java-9-CPU-NTT-2019-2019-09-05-15-320.jpg)


![© 2019 NTT DATA Corporation 18 #NTTDATATC
例:FIRフィルタ
𝑦𝑦[𝑛𝑛] = �
𝑖𝑖=0
𝑁𝑁−1
𝐴𝐴 𝑖𝑖 𝐵𝐵[𝑛𝑛 − 𝑖𝑖]
public double calcFIR(double[] a, double[] b){
int N = a.length;
int n = N – 1;
double result = 0.0d;
for(int i = 0; i < N; i++) {
result += a[i] * b[n – i];
}
return result;
}
public double calcFIR(double[] a, double[] b){
int N = a.length;
int n = N – 1;
double result = 0.0d;
for(int i = 0; i < N; i++) {
result = Math.fma(a[i], b[n – i], result);
}
return result;
}
普通に計算 FMA利用](https://image.slidesharecdn.com/javamaximizepowercpu2019nttdatasuenaga-190930214721/85/Java-CPU-Java-9-CPU-NTT-2019-2019-09-05-18-320.jpg)
![© 2019 NTT DATA Corporation 19 #NTTDATATC
例:FIRフィルタ
result += a[i] * b[n – i]; result = Math.fma(a[i], b[n – i], result);
vmulsd %xmm2,%xmm1,%xmm1
vaddsd %xmm0,%xmm1,%xmm1
vfmadd231sd %xmm2,%xmm1,%xmm0
JITコンパイル JITコンパイル
250112.3323524159 250112.33235242742
計算結果 計算結果
• 普通に計算した場合でもベクタライズされる
• 普通に計算:2命令、FMA:1命令
• 計算結果も若干違う!
普通に計算 FMA利用
N=1,000,000、Randomで生成した配列の計算例](https://image.slidesharecdn.com/javamaximizepowercpu2019nttdatasuenaga-190930214721/85/Java-CPU-Java-9-CPU-NTT-2019-2019-09-05-19-320.jpg)










![© 2019 NTT DATA Corporation 32 #NTTDATATC
VNNI
public void mulAdd(short[] in1, short[] in2, int[] out){
for(int i = 0; i < N; i++){
out[i] += ((in1[2*i] * in2[2*i]) + (in1[2*i+1] * in2[2*i+1]));
}
}
vpmaddwd %ymm0,%ymm1,%ymm0
vpaddd 0x10(%r13,%rbx,4),%ymm0,%ymm0
vpdpwssd %zmm1,%zmm2,%zmm0
• ZMMレジスタを使った64バイトずつの処理
• 掛けて足して(vpmaddwd)また足す(vpaddd)が
VNNIが提供する1命令(vpdpwssd)に
Whiskey Lake Cascade Lake](https://image.slidesharecdn.com/javamaximizepowercpu2019nttdatasuenaga-190930214721/85/Java-CPU-Java-9-CPU-NTT-2019-2019-09-05-32-320.jpg)








![© 2019 NTT DATA Corporation 43 #NTTDATATC
実行
• –XX:+PrintAssembly
• JITにかかったコードすべてをディスアセンブル
• 出力が膨大
• –XX:CompilerDirectivesFile=<JSONファイル>
• Java 9から導入されたJITコンパイラの挙動指定方法
• https://docs.oracle.com/javase/jp/12/vm/writing-directives.html
• 後からjcmdで設定/変更が可能 [
{
“match”: “FMATest.calcFIRFMA”,
“PrintAssembly”: true
}
]
-XX:+UnlockDiagnosticVMOptionsに加えて
以下のいずれかを使用する](https://image.slidesharecdn.com/javamaximizepowercpu2019nttdatasuenaga-190930214721/85/Java-CPU-Java-9-CPU-NTT-2019-2019-09-05-43-320.jpg)



























































































