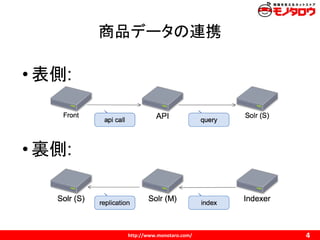
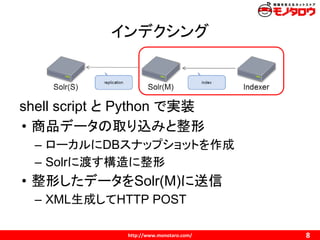
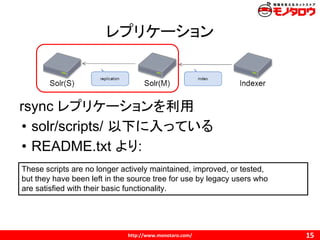
レプリケーション
rsync レプリケーションを利用
• solr/scripts/以下に入っている
• README.txt より:
These scripts are no longer actively maintained, improved, or tested,
but they have been left in the source tree for use by legacy users who
are satisfied with their basic functionality.




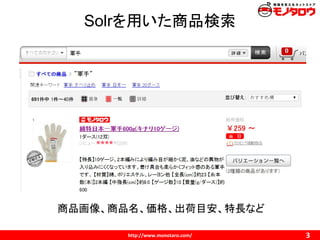




















































![Collaborating for Success: Seller Perspective [Tokyo]](https://cdn.slidesharecdn.com/ss_thumbnails/aribacommercesummittokyomisumi-150916173556-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
















![[ITmedia Cloud Native 2023] モノタロウのクラウドネイティブ.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/itmediacloudnative2023-230609023902-1d32cbbd-thumbnail.jpg?width=640&height=640&fit=bounds)












