Download as PDF, PPTX







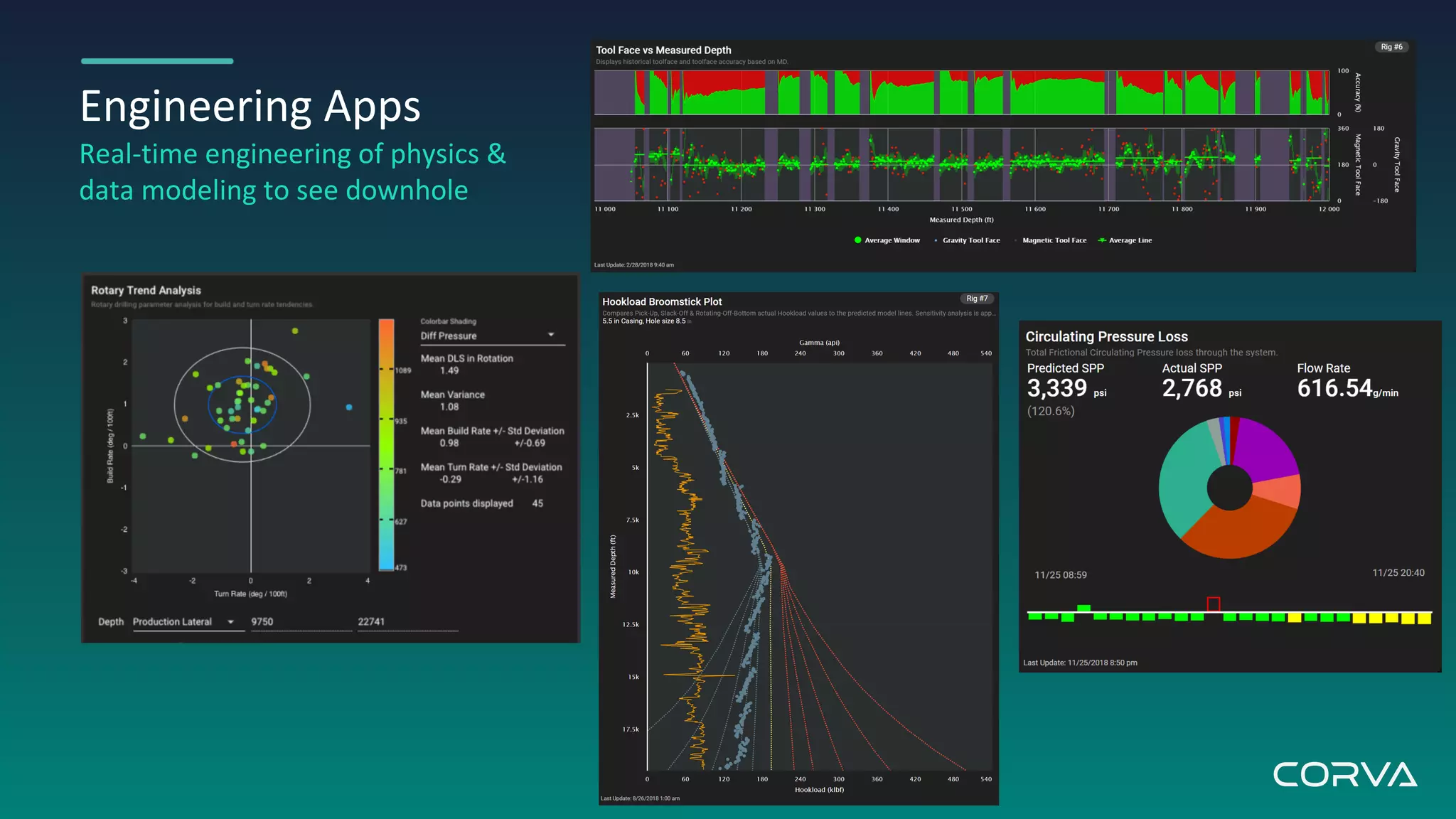
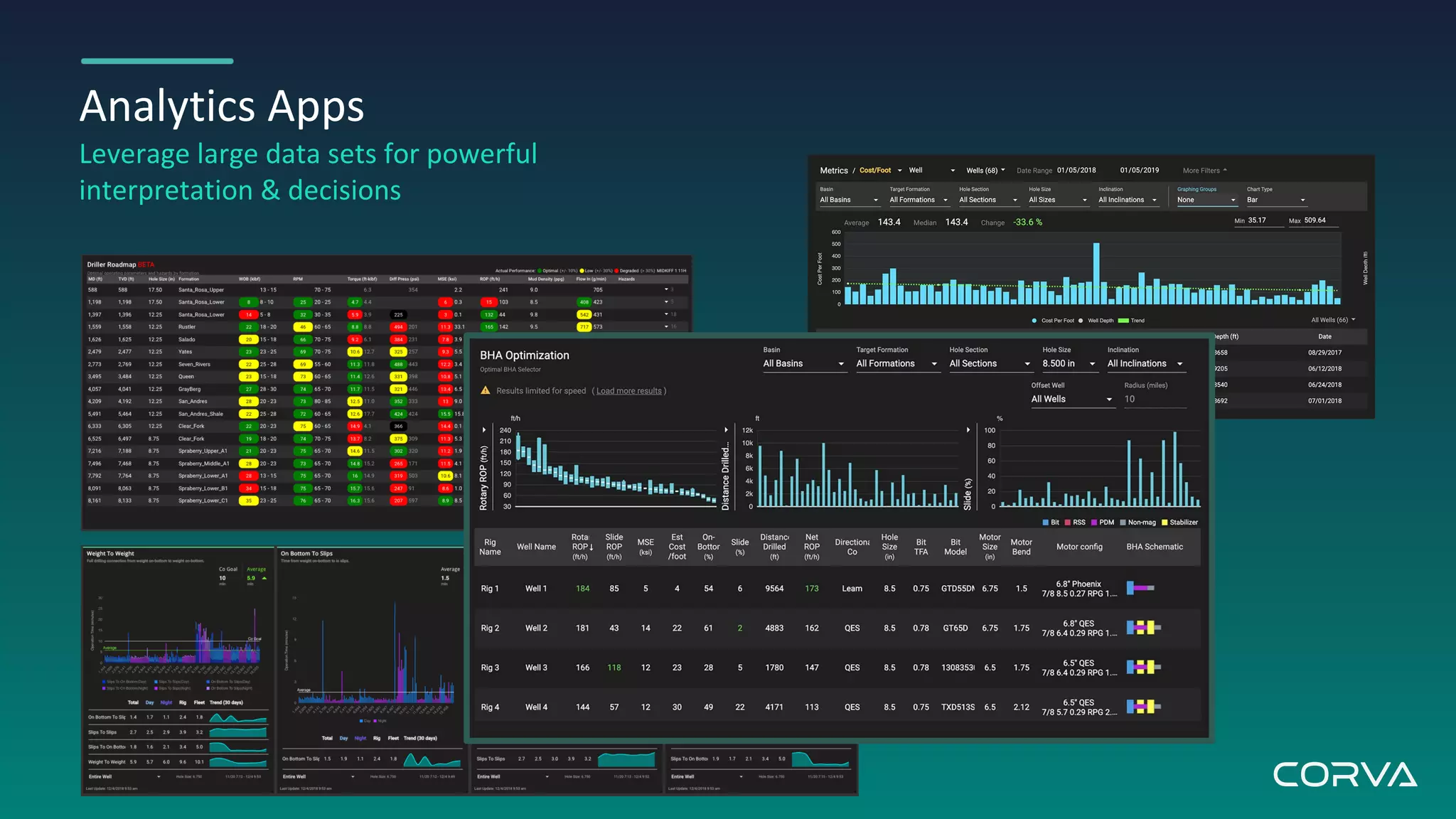

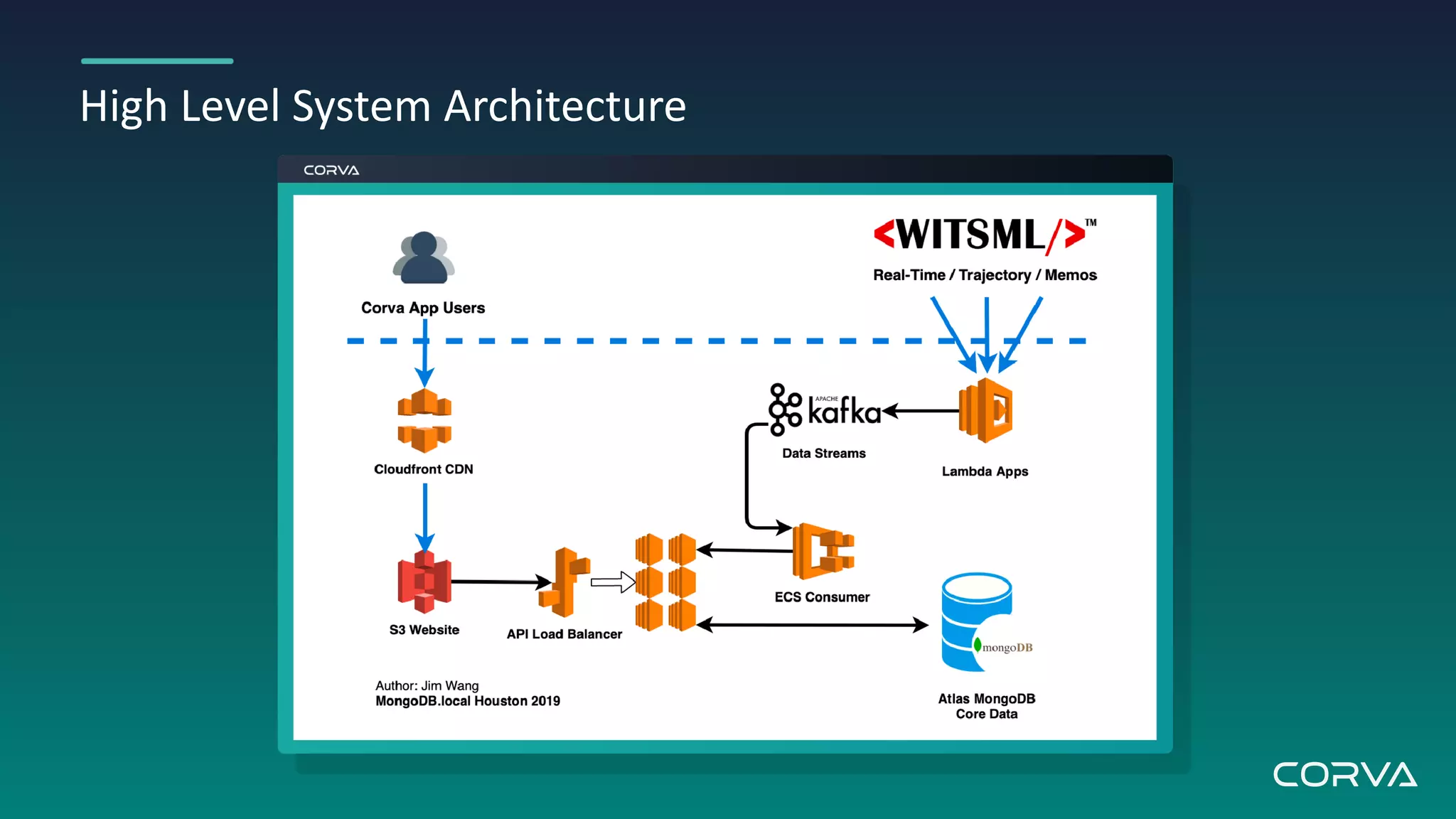
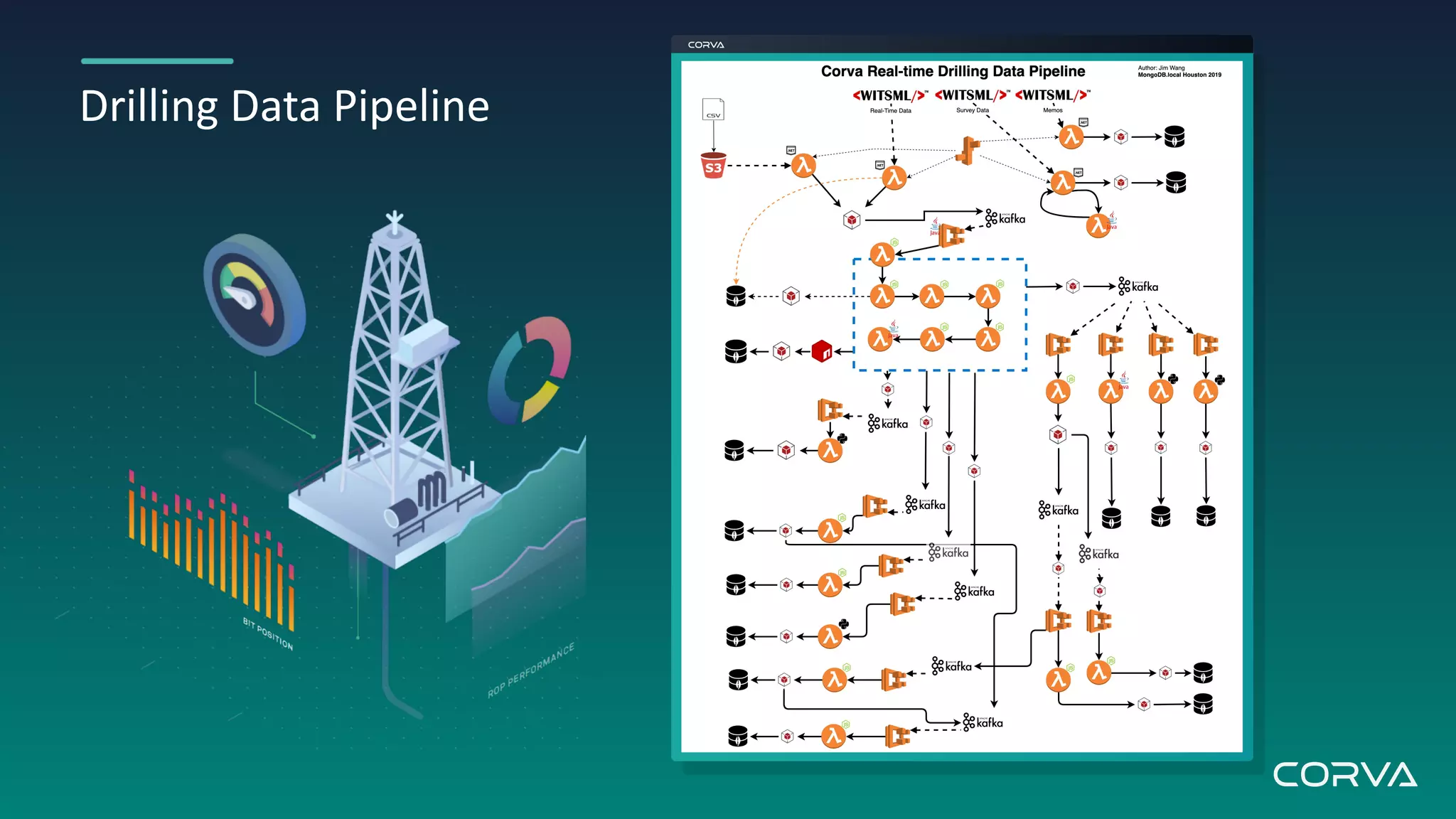
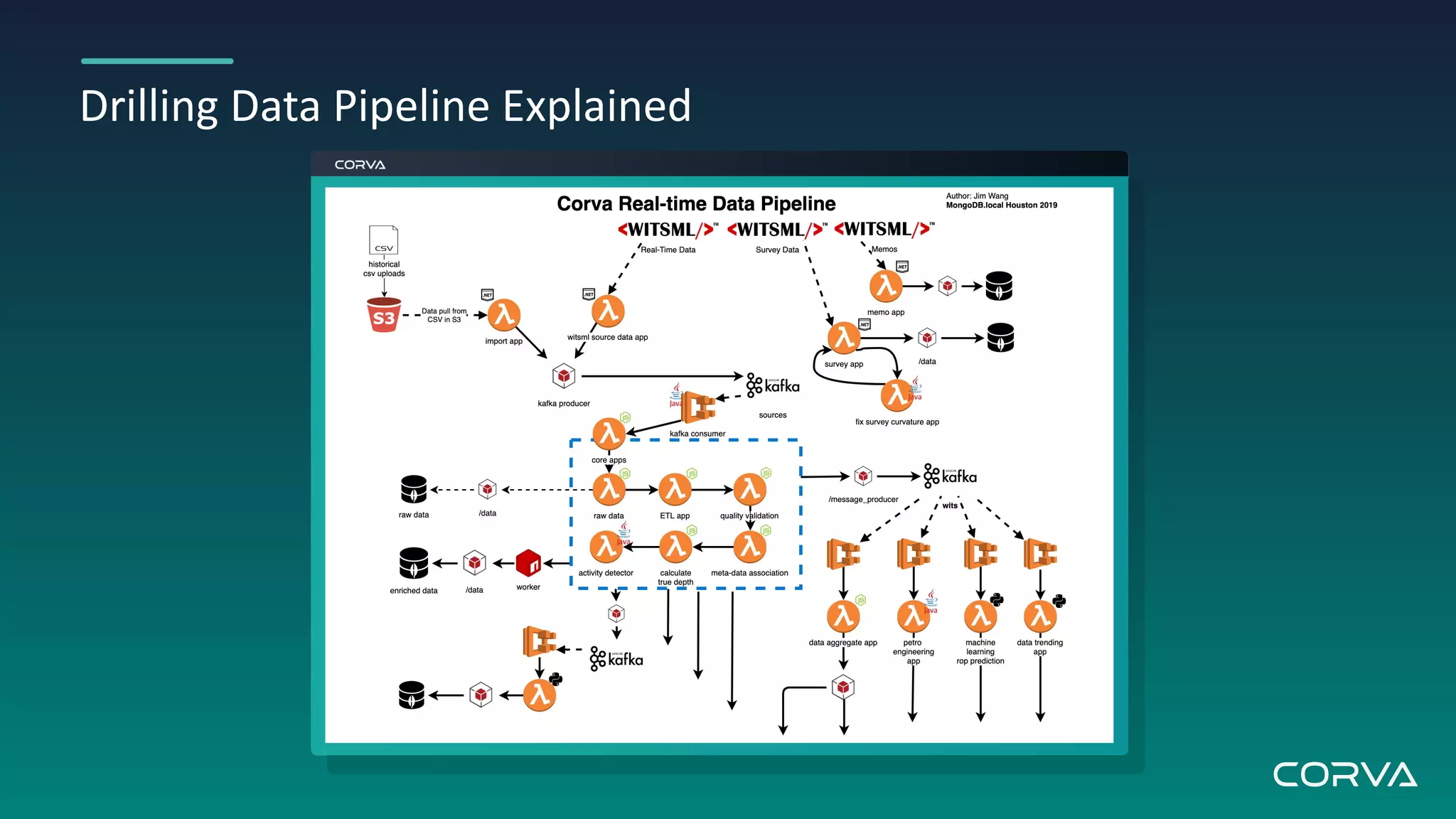
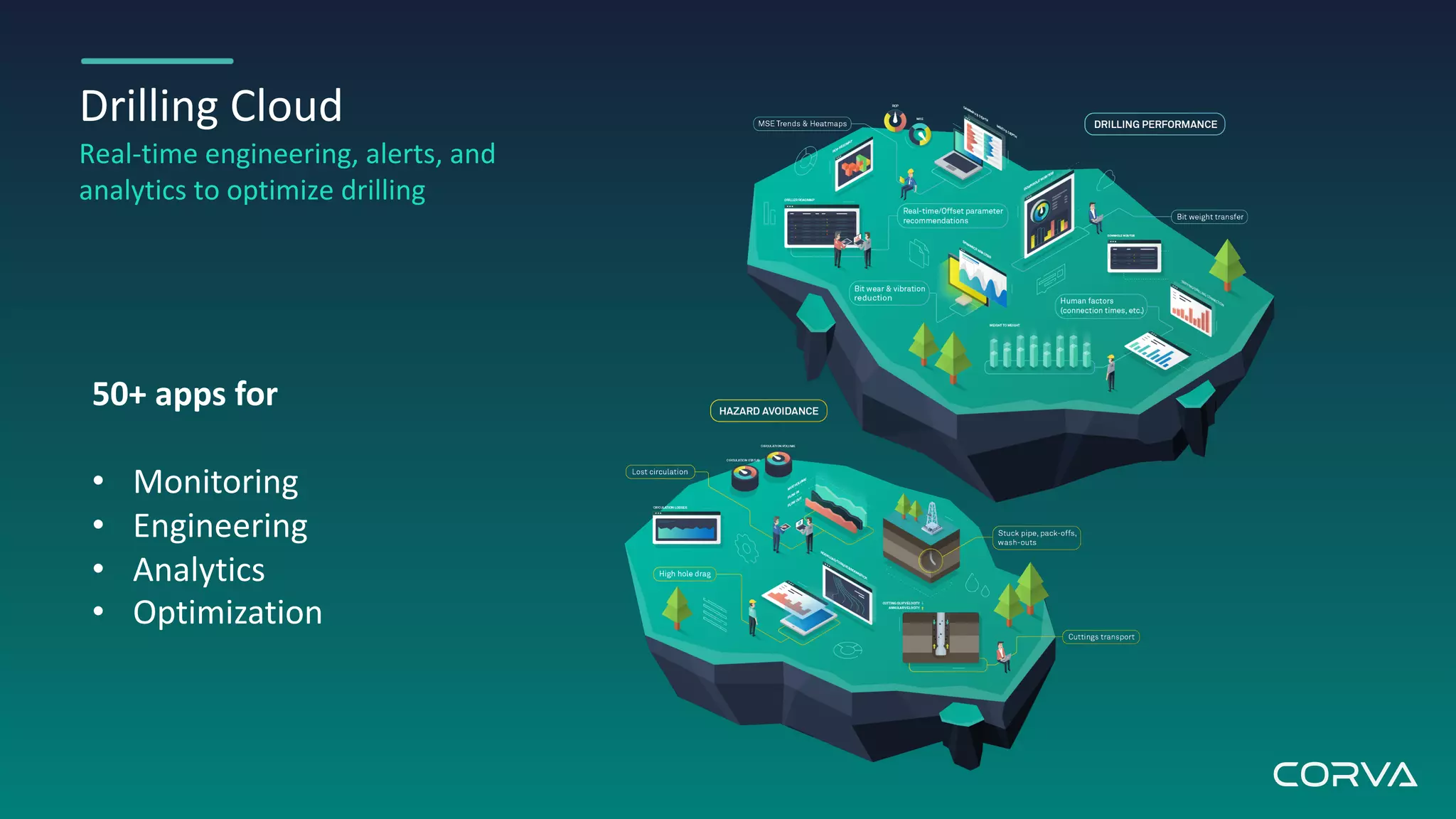





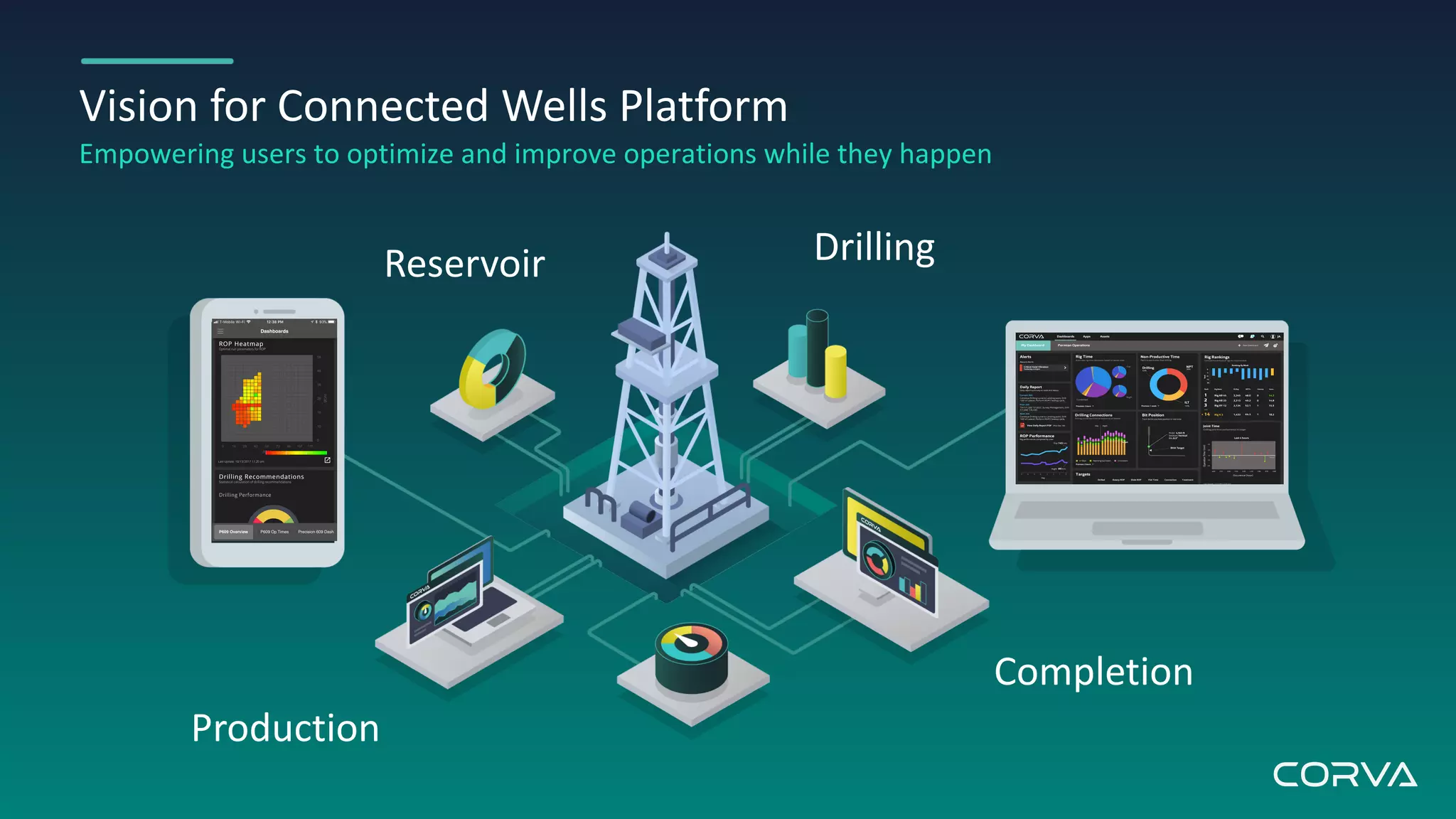



Corva's IoT streaming analytics platform addresses challenges in the oil and gas industry by providing real-time data processing and insights to optimize drilling operations. Utilizing MongoDB for flexible schema and scalability, Corva enables rapid data growth and customization to enhance decision-making with powerful engineering apps. Their future plans include a connected wells platform to empower users and streamline workflows through automation.
































![MongoDB .local San Francisco 2020: Powering the new age data demands [Infosys]](https://cdn.slidesharecdn.com/ss_thumbnails/315pminfosysfinalsfoversionvocalpart1-200120221508-thumbnail.jpg?width=640&height=640&fit=bounds)















![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)


















