Download to read offline








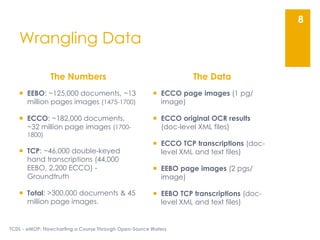
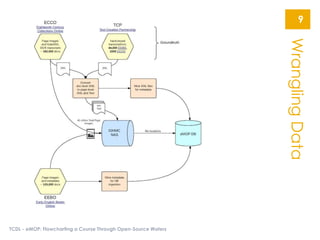
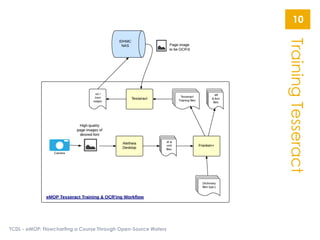
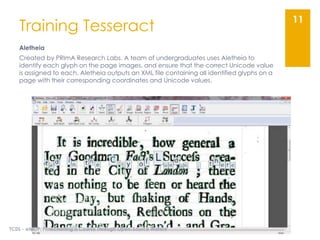

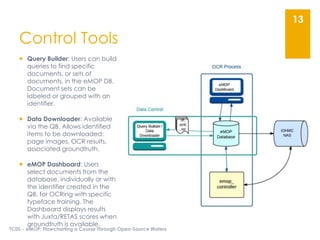

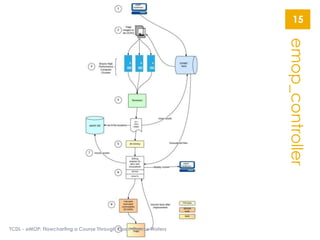

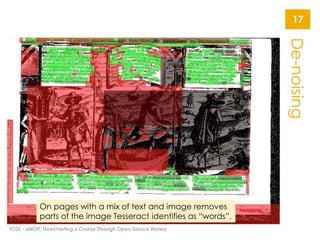
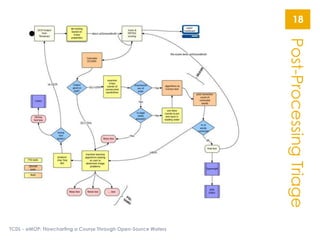
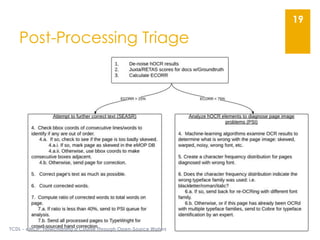
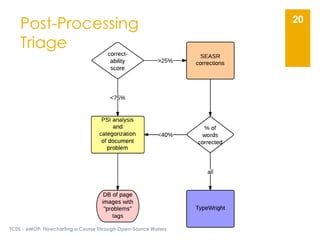

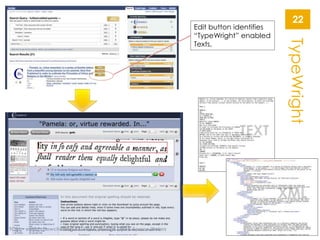



The document describes the Early Modern OCR Project (eMOP) which aims to Optical Character Recognition (OCR) over 300,000 documents and 45 million page images from the Early English Books Online (EEBO) and Eighteenth Century Collections Online (ECCO) collections. It outlines the challenges of OCRing early modern texts including inconsistent fonts, layouts, and quality issues. It then details eMOP's workflow which includes training Tesseract with manually labeled glyphs, de-noising and scoring OCR output, and making corrections through the TypeWright tool. The fully-searchable OCR and corrections will be made freely available through aggregators like 18thConnect to improve access and reuse of these texts




















































