Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Kosuke Kida
PDF, PPTX
56,858 views
まずやっとくPostgreSQLチューニング
2014年7月13日 第4回中国地方DB勉強会セッション資料
Read more
98
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 38
2
/ 38
Most read
3
/ 38
4
/ 38
5
/ 38
6
/ 38
7
/ 38
Most read
8
/ 38
9
/ 38
10
/ 38
Most read
11
/ 38
12
/ 38
13
/ 38
14
/ 38
15
/ 38
16
/ 38
17
/ 38
18
/ 38
19
/ 38
20
/ 38
21
/ 38
22
/ 38
23
/ 38
24
/ 38
25
/ 38
26
/ 38
27
/ 38
28
/ 38
29
/ 38
30
/ 38
31
/ 38
32
/ 38
33
/ 38
34
/ 38
35
/ 38
36
/ 38
37
/ 38
38
/ 38
More Related Content
PDF
アーキテクチャから理解するPostgreSQLのレプリケーション
by
Masahiko Sawada
PDF
PostgreSQLのリカバリ超入門(もしくはWAL、CHECKPOINT、オンラインバックアップの仕組み)
by
Hironobu Suzuki
PDF
統計情報のリセットによるautovacuumへの影響について(第39回PostgreSQLアンカンファレンス@オンライン 発表資料)
by
NTT DATA Technology & Innovation
PPTX
PostgreSQLモニタリングの基本とNTTデータが追加したモニタリング新機能(Open Source Conference 2021 Online F...
by
NTT DATA Technology & Innovation
PPTX
監査要件を有するシステムに対する PostgreSQL 導入の課題と可能性
by
Ohyama Masanori
PPTX
Kubernetesでの性能解析 ~なんとなく遅いからの脱却~(Kubernetes Meetup Tokyo #33 発表資料)
by
NTT DATA Technology & Innovation
PDF
NTT DATA と PostgreSQL が挑んだ総力戦
by
NTT DATA OSS Professional Services
PPTX
PostgreSQLの統計情報について(第26回PostgreSQLアンカンファレンス@オンライン 発表資料)
by
NTT DATA Technology & Innovation
アーキテクチャから理解するPostgreSQLのレプリケーション
by
Masahiko Sawada
PostgreSQLのリカバリ超入門(もしくはWAL、CHECKPOINT、オンラインバックアップの仕組み)
by
Hironobu Suzuki
統計情報のリセットによるautovacuumへの影響について(第39回PostgreSQLアンカンファレンス@オンライン 発表資料)
by
NTT DATA Technology & Innovation
PostgreSQLモニタリングの基本とNTTデータが追加したモニタリング新機能(Open Source Conference 2021 Online F...
by
NTT DATA Technology & Innovation
監査要件を有するシステムに対する PostgreSQL 導入の課題と可能性
by
Ohyama Masanori
Kubernetesでの性能解析 ~なんとなく遅いからの脱却~(Kubernetes Meetup Tokyo #33 発表資料)
by
NTT DATA Technology & Innovation
NTT DATA と PostgreSQL が挑んだ総力戦
by
NTT DATA OSS Professional Services
PostgreSQLの統計情報について(第26回PostgreSQLアンカンファレンス@オンライン 発表資料)
by
NTT DATA Technology & Innovation
What's hot
PPTX
PostgreSQLのfull_page_writesについて(第24回PostgreSQLアンカンファレンス@オンライン 発表資料)
by
NTT DATA Technology & Innovation
PDF
PGOを用いたPostgreSQL on Kubernetes入門(PostgreSQL Conference Japan 2022 発表資料)
by
NTT DATA Technology & Innovation
PDF
PostgreSQLの運用・監視にまつわるエトセトラ
by
NTT DATA OSS Professional Services
PPTX
オンライン物理バックアップの排他モードと非排他モードについて ~PostgreSQLバージョン15対応版~(第34回PostgreSQLアンカンファレンス...
by
NTT DATA Technology & Innovation
PDF
PostgreSQLレプリケーション10周年!徹底紹介!(PostgreSQL Conference Japan 2019講演資料)
by
NTT DATA Technology & Innovation
PDF
PostgreSQLレプリケーション徹底紹介
by
NTT DATA OSS Professional Services
PPTX
PostgreSQL開発コミュニティに参加しよう! ~2022年版~(Open Source Conference 2022 Online/Kyoto 発...
by
NTT DATA Technology & Innovation
PDF
PostgreSQLの関数属性を知ろう
by
kasaharatt
PDF
[Cloud OnAir] BigQuery の仕組みからベストプラクティスまでのご紹介 2018年9月6日 放送
by
Google Cloud Platform - Japan
PDF
At least onceってぶっちゃけ問題の先送りだったよね #kafkajp
by
Yahoo!デベロッパーネットワーク
PDF
DockerとPodmanの比較
by
Akihiro Suda
PDF
レプリケーション遅延の監視について(第40回PostgreSQLアンカンファレンス@オンライン 発表資料)
by
NTT DATA Technology & Innovation
PDF
PostgreSQL: XID周回問題に潜む別の問題
by
NTT DATA OSS Professional Services
PDF
pg_walinspectについて調べてみた!(第37回PostgreSQLアンカンファレンス@オンライン 発表資料)
by
NTT DATA Technology & Innovation
PPTX
VSCodeで作るPostgreSQL開発環境(第25回 PostgreSQLアンカンファレンス@オンライン 発表資料)
by
NTT DATA Technology & Innovation
PDF
YugabyteDBを使ってみよう(NewSQL/分散SQLデータベースよろず勉強会 #1 発表資料)
by
NTT DATA Technology & Innovation
PPTX
PostgreSQL 12は ここがスゴイ! ~性能改善やpluggable storage engineなどの新機能を徹底解説~ (NTTデータ テクノ...
by
NTT DATA Technology & Innovation
PDF
ゼロからはじめるKVM超入門
by
VirtualTech Japan Inc.
PDF
PostgreSQLをKubernetes上で活用するためのOperator紹介!(Cloud Native Database Meetup #3 発表資料)
by
NTT DATA Technology & Innovation
PPTX
PostgreSQLのロール管理とその注意点(Open Source Conference 2022 Online/Osaka 発表資料)
by
NTT DATA Technology & Innovation
PostgreSQLのfull_page_writesについて(第24回PostgreSQLアンカンファレンス@オンライン 発表資料)
by
NTT DATA Technology & Innovation
PGOを用いたPostgreSQL on Kubernetes入門(PostgreSQL Conference Japan 2022 発表資料)
by
NTT DATA Technology & Innovation
PostgreSQLの運用・監視にまつわるエトセトラ
by
NTT DATA OSS Professional Services
オンライン物理バックアップの排他モードと非排他モードについて ~PostgreSQLバージョン15対応版~(第34回PostgreSQLアンカンファレンス...
by
NTT DATA Technology & Innovation
PostgreSQLレプリケーション10周年!徹底紹介!(PostgreSQL Conference Japan 2019講演資料)
by
NTT DATA Technology & Innovation
PostgreSQLレプリケーション徹底紹介
by
NTT DATA OSS Professional Services
PostgreSQL開発コミュニティに参加しよう! ~2022年版~(Open Source Conference 2022 Online/Kyoto 発...
by
NTT DATA Technology & Innovation
PostgreSQLの関数属性を知ろう
by
kasaharatt
[Cloud OnAir] BigQuery の仕組みからベストプラクティスまでのご紹介 2018年9月6日 放送
by
Google Cloud Platform - Japan
At least onceってぶっちゃけ問題の先送りだったよね #kafkajp
by
Yahoo!デベロッパーネットワーク
DockerとPodmanの比較
by
Akihiro Suda
レプリケーション遅延の監視について(第40回PostgreSQLアンカンファレンス@オンライン 発表資料)
by
NTT DATA Technology & Innovation
PostgreSQL: XID周回問題に潜む別の問題
by
NTT DATA OSS Professional Services
pg_walinspectについて調べてみた!(第37回PostgreSQLアンカンファレンス@オンライン 発表資料)
by
NTT DATA Technology & Innovation
VSCodeで作るPostgreSQL開発環境(第25回 PostgreSQLアンカンファレンス@オンライン 発表資料)
by
NTT DATA Technology & Innovation
YugabyteDBを使ってみよう(NewSQL/分散SQLデータベースよろず勉強会 #1 発表資料)
by
NTT DATA Technology & Innovation
PostgreSQL 12は ここがスゴイ! ~性能改善やpluggable storage engineなどの新機能を徹底解説~ (NTTデータ テクノ...
by
NTT DATA Technology & Innovation
ゼロからはじめるKVM超入門
by
VirtualTech Japan Inc.
PostgreSQLをKubernetes上で活用するためのOperator紹介!(Cloud Native Database Meetup #3 発表資料)
by
NTT DATA Technology & Innovation
PostgreSQLのロール管理とその注意点(Open Source Conference 2022 Online/Osaka 発表資料)
by
NTT DATA Technology & Innovation
Similar to まずやっとくPostgreSQLチューニング
PDF
2018年度 若手技術者向け講座 大量データの扱い・ストアド・メモリ管理
by
keki3
PPTX
SQLチューニング入門 入門編
by
Miki Shimogai
PPT
20090107 Postgre Sqlチューニング(Sql編)
by
Hiromu Shioya
PDF
TPC-DSから学ぶPostgreSQLの弱点と今後の展望
by
Kohei KaiGai
PDF
Oss x user_meeting_6_postgres
by
Kosuke Kida
PDF
OSC沖縄2014_JPUG資料
by
kasaharatt
PDF
PostgreSQL SQLチューニング入門 実践編(pgcon14j)
by
Satoshi Yamada
PPTX
Tuning on my_sql
by
Edward D. Kim
PPTX
PostgreSQLクエリ実行の基礎知識 ~Explainを読み解こう~
by
Miki Shimogai
PDF
[db tech showcase Tokyo 2015] B36:Hitachi Advanced Data Binder 実践SQLチューニング方法 ...
by
Insight Technology, Inc.
PDF
PostgreSQL13 新機能紹介
by
Satoshi Hirata
PDF
[db tech showcase Tokyo 2016] C32: 世界一速いPostgreSQLを目指せ!インメモリカラムナの実現 by 富士通株式会...
by
Insight Technology, Inc.
PDF
明日から使えるPostgre sql運用管理テクニック(監視編)
by
kasaharatt
PDF
[D33] そのデータベース 5年後大丈夫ですか by Hiromu Goto
by
Insight Technology, Inc.
PDF
各スペシャリストがお届け!データベース最新情報セミナー -PostgreSQL10-
by
Yoshinori Nakanishi
PDF
Introduction of Oracle Database Architecture
by
Ryota Watabe
PDF
CLUB DB2 第122回 DB2管理本の著者が教える 簡単運用管理入門
by
Akira Shimosako
PDF
ヤフー社内でやってるMySQLチューニングセミナー大公開
by
Yahoo!デベロッパーネットワーク
PDF
Chugokudb18_1
by
Kosuke Kida
PDF
DB2の使い方 管理ツール編
by
Akira Shimosako
2018年度 若手技術者向け講座 大量データの扱い・ストアド・メモリ管理
by
keki3
SQLチューニング入門 入門編
by
Miki Shimogai
20090107 Postgre Sqlチューニング(Sql編)
by
Hiromu Shioya
TPC-DSから学ぶPostgreSQLの弱点と今後の展望
by
Kohei KaiGai
Oss x user_meeting_6_postgres
by
Kosuke Kida
OSC沖縄2014_JPUG資料
by
kasaharatt
PostgreSQL SQLチューニング入門 実践編(pgcon14j)
by
Satoshi Yamada
Tuning on my_sql
by
Edward D. Kim
PostgreSQLクエリ実行の基礎知識 ~Explainを読み解こう~
by
Miki Shimogai
[db tech showcase Tokyo 2015] B36:Hitachi Advanced Data Binder 実践SQLチューニング方法 ...
by
Insight Technology, Inc.
PostgreSQL13 新機能紹介
by
Satoshi Hirata
[db tech showcase Tokyo 2016] C32: 世界一速いPostgreSQLを目指せ!インメモリカラムナの実現 by 富士通株式会...
by
Insight Technology, Inc.
明日から使えるPostgre sql運用管理テクニック(監視編)
by
kasaharatt
[D33] そのデータベース 5年後大丈夫ですか by Hiromu Goto
by
Insight Technology, Inc.
各スペシャリストがお届け!データベース最新情報セミナー -PostgreSQL10-
by
Yoshinori Nakanishi
Introduction of Oracle Database Architecture
by
Ryota Watabe
CLUB DB2 第122回 DB2管理本の著者が教える 簡単運用管理入門
by
Akira Shimosako
ヤフー社内でやってるMySQLチューニングセミナー大公開
by
Yahoo!デベロッパーネットワーク
Chugokudb18_1
by
Kosuke Kida
DB2の使い方 管理ツール編
by
Akira Shimosako
More from Kosuke Kida
PDF
PostgreSQLレプリケーション(pgcon17j_t4)
by
Kosuke Kida
PDF
Jjugccc2017spring-postgres-ccc_m1
by
Kosuke Kida
PDF
Jpug study-pq 20170121
by
Kosuke Kida
PDF
Oratopostgres-hiroshima
by
Kosuke Kida
PDF
Chugokudb18_2
by
Kosuke Kida
PDF
[OSC2016沖縄]商用DBからPostgreSQLへの移行入門
by
Kosuke Kida
PDF
商用DBからPostgreSQLへ まず知っておいて欲しいまとめ
by
Kosuke Kida
PDF
[9.5新機能]追加されたgroupbyの使い方
by
Kosuke Kida
PDF
ランナーから見た糖質
by
Kosuke Kida
PDF
[Postgre sql9.4新機能]レプリケーション・スロットの活用
by
Kosuke Kida
PostgreSQLレプリケーション(pgcon17j_t4)
by
Kosuke Kida
Jjugccc2017spring-postgres-ccc_m1
by
Kosuke Kida
Jpug study-pq 20170121
by
Kosuke Kida
Oratopostgres-hiroshima
by
Kosuke Kida
Chugokudb18_2
by
Kosuke Kida
[OSC2016沖縄]商用DBからPostgreSQLへの移行入門
by
Kosuke Kida
商用DBからPostgreSQLへ まず知っておいて欲しいまとめ
by
Kosuke Kida
[9.5新機能]追加されたgroupbyの使い方
by
Kosuke Kida
ランナーから見た糖質
by
Kosuke Kida
[Postgre sql9.4新機能]レプリケーション・スロットの活用
by
Kosuke Kida
まずやっとくPostgreSQLチューニング
1.
Copyright © 2014
K.K.Ashisuto All Rights Reserved. 1 まずやっとく PostgreSQLのチューニング 日本PostgeSQLユーザ会 喜田 紘介 2014/07/13第4回 中国地方DB勉強会
2.
Copyright © 2014
K.K.Ashisuto All Rights Reserved. 2 自己紹介 ● 名前 ● 喜田 紘介(きだ こうすけ) ● 所属 ● 日本PostgreSQLユーザ会 広報・企画担当 ● 株式会社アシスト データベース技術本部 ● 近況 ● 2014年度より、JPUGの理事になりました。 ● 仕事では、新規構築するシステムのDBをどうすべきか?というRDBMS選択支援や、 商用DBからOSSへの移行の前段階として、オブジェクトやSQL差異のレクチャーや、 データベースの診断・評価を行う 移行アセスメント支援 を主に担当しています。 ● この夏やりたいこと PG9.4の検証、マラソンとトライアスロンの練習、歌とギターの練習(初心者)
3.
Copyright © 2014
K.K.Ashisuto All Rights Reserved. 3 本日お話すること ● RDBMSの基本構造に沿いながら、マニュアルレベルでPostgreSQLの チューニングポイントを解説 ● PostgreSQLでの実行計画の見方、SQLチューニングの方法を解説 ● 最新バージョン9.4betaの話を少し SQL
4.
Copyright © 2014
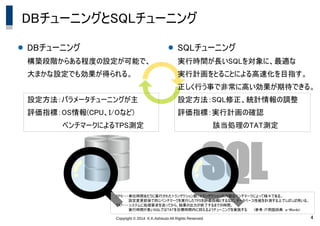
K.K.Ashisuto All Rights Reserved. 4 DBチューニングとSQLチューニング ● DBチューニング 構築段階からある程度の設定が可能で、 大まかな設定でも効果が得られる。 設定方法:パラメータチューニングが主 評価指標:OS情報(CPU、I/Oなど) ベンチマークによるTPS測定 SQL ● SQLチューニング 実行時間が長いSQLを対象に、最適な 実行計画をとることによる高速化を目指す。 正しく行う事で非常に高い効果が期待できる。 設定方法:SQL修正、統計情報の調整 評価指標:実行計画の確認 該当処理のTAT測定 TPS・・・単位時間あたりに実行されたトランザクション数。トランザクションの内容はベンチマークによって様々である。 設定変更前後で同じベンチマークを実行したTPSを評価指標とするなど、データベース性能を計測する上でしばしば用いる。 TAT・・・システムに処理要求を送ってから、結果の出力が終了するまでの時間。 実行時間が長いSQLではTATを目標時間内に抑えるようチューニングを実施する (参考:IT用語辞典 e-Words)
5.
Copyright © 2014
K.K.Ashisuto All Rights Reserved. 5 データベースの チューニングポイント
6.
Copyright © 2014
K.K.Ashisuto All Rights Reserved. 6 RDBMSのアーキテクチャ PostgreSQL ● データベースのアーキテクチャからチューニングポイントを考える ● メモリ - キャッシュヒット率 - WAL生成タイミング - ソート等の一時領域 ● ディスクI/O - チェックポイント間隔の調整 - オブジェクトのメンテナンス ● プロセス - VACUUM関連 - writerプロセス クライアントマシン Webサーバー など バックエンドプロセス データベース WALファイル 共有バッファ WALバッファ 共有メモリ writer wal writer 処理毎に行う動作 効率化する動作 SQL処理におけるPostgreSQLの動作 work_mem maintenance_work_mem
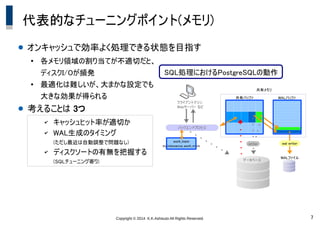
7.
Copyright © 2014
K.K.Ashisuto All Rights Reserved. 7 代表的なチューニングポイント(メモリ) ● オンキャッシュで効率よく処理できる状態を目指す ● 各メモリ領域の割り当てが不適切だと、 ディスクI/Oが頻発 ● 最適化は難しいが、大まかな設定でも 大きな効果が得られる ● 考えることは 3つ ✔ キャッシュヒット率が適切か ✔ WAL生成のタイミング (ただし最近は自動調整で問題なし) ✔ ディスクソートの有無を把握する (SQLチューニング寄り) クライアントマシン Webサーバー など バックエンドプロセス データベース WALファイル 共有バッファ WALバッファ 共有メモリ writer wal writer work_mem maintenance_work_mem SQL処理におけるPostgreSQLの動作
8.
Copyright © 2014
K.K.Ashisuto All Rights Reserved. 8 代表的なチューニングポイント(ディスクI/O) ● 性能を引き出す上で一番の要となるポイント ● チェックポイントによる性能影響は 非常に大きい ● オブジェクトに対しての適切な メンテナンスも大事 ● チェックポイント間隔を適切にする ✔ WALとの関係を知っておくこと ✔ チェックポイント間隔を調整する ● オブジェクトのメンテナンス(本日は省略) ✔ テーブル(ページ)の余裕率を検討 ✔ テーブルの再作成 ✔ インデックスの再作成 クライアントマシン Webサーバー など バックエンドプロセス データベース WALファイル 共有バッファ WALバッファ 共有メモリ wal writer work_mem maintenance_work_mem writer tables SQL処理におけるPostgreSQLの動作
9.
Copyright © 2014
K.K.Ashisuto All Rights Reserved. 9 代表的なチューニングポイント(プロセス) ● 最適を求める場合、各プロセスの動作を細かく調整(製品固有のことが多い) ● PostgreSQL固有のVACUUM処理 ● writerの動作も調整可能 ● VACUUM処理の最適化 ✔ 自動VACUUMがきちんと動くこと ✔ VACUUM FULLは不要 ✔ VACUUM/ANALYZEの閾値 ● writerの動作(本日は省略) ✔ ダーティバッファの書き出しは常時 (ただし、ここまで調整することは稀) クライアントマシン Webサーバー など バックエンドプロセス データベース WALファイル 共有バッファ WALバッファ 共有メモリ wal writer work_mem maintenance_work_mem writer vacuum vacuum vacuum SQL処理におけるPostgreSQLの動作
10.
Copyright © 2014
K.K.Ashisuto All Rights Reserved. 10 設定方法と確認方法の基本 ● DBチューニングの基本はパラメータ設定 ● データベースクラスタ($PGDATA)配下のpostgresql.confを調整 ● 反映されるタイミングを知っておく ● パラメータ毎にDBの再起動/設定のリロード/即時など、反映されるタイミングが異なる ● SQLで確認可能 (公式のドキュメントでパラメータ一覧が存在しない) ● 現状を確認するには統計情報ビューを参照 ● pg_stats* や pg_statsio* を参照することで、現状が適切かどうかが判断できる ● 場合によっては、動作させてログを見ることも必要 /* pg_settingsビューを参照 */ postgres=# x postgres=# SELECT name,setting,unit,context FROM pg_settings; SELECT distinct context FROM pg_settings; internal ・・・変更不可(構築時設定確認用) postmaster ・・・サーバ起動時 sighup ・・・設定ファイルの再読み込み backend ・・・セッション確立時に決定 superuser ・・・スーパユーザ権限で動的変更可能 user ・・・一般ユーザで動的変更可能
11.
Copyright © 2014
K.K.Ashisuto All Rights Reserved. 11 DBチューニングの実践
12.
Copyright © 2014
K.K.Ashisuto All Rights Reserved. 12 キャッシュヒット率を高く保つ ● アクセスデータ範囲を shared_buffers に収める ● postgresql.conf の shared_buffers は物理メモリの25%-40%程度とする ● OSのファイルキャッシュも使うため、厳密な調整でなくても良い ● 物理メモリが数十GBを超える場合や、Windowsの場合などに注意が必要 ● キャッシュヒット率の確認 ● SQLで累計のキャッシュヒット率を確認する ● キャッシュヒット率を高めるための工夫 ● 事前に表全体(またはWHERE句で絞って)SELECTし、ウォームアップ ● 索引やパーティションで必要な範囲のみにアクセスする /* データベース単位でキャッシュヒット率を確認 */ postgres=# SELECT datname,ROUND(blks_hit*100/(blks_hit+blks_read), 2) AS cache_hit_ratio FROM pg_stat_database WHERE blks_read > 0; datname | cache_hit_ratio -----------+----------------- template1 | 99.00 postgres | 99.00 /* テーブル単位でキャッシュヒット率を確認 */ postgres=# SELECT relname, ROUND(heap_blks_hit*100/(heap_blks_hit+heap_blks_read), 2) AS cache_hit_ratio FROM pg_statio_user_tables WHERE heap_blks_read > 0 ORDER BY cache_hit_ratio; relname | cache_hit_ratio ------------+----------------- emp | 99.00 dept | 99.00
13.
Copyright © 2014
K.K.Ashisuto All Rights Reserved. 13 WAL生成のタイミングを知る ● WAL生成のタイミングを知り、wal_buffersパラメータを調整 ● postgresql.conf の wal_buffers は最近のバージョンでは自動調整される ● 旧バージョンでは、デフォルトのWALファイルサイズの16MB以上にしてみる(推奨32MB) ● WALがファイルに書かれるタイミングは以下 – トランザクションがコミットされたとき – WALバッファが一杯になったとき ★これを減らしつつ効率的なのは、 wal_buffers > WALセグメント(ファイル)サイズ – wal_writer_delay パラメータに指定された時間経過(デフォルト200ms) ● 1トランザクションでの更新が多い場合、コミット以外のタイミングでの書き込み発生に注意 ● 同時接続数が多い場合も、コミット前にwal_buffersを超える可能性が高い ● 明確な確認方法は特に用意されていない ● WAL生成量はファイル作成時刻などからある程度推測可能 ● しかし、WALがいつ書かれたかは確認する手段がない ➢ Postgres Plusは待機イベントの確認が可能で、WAL生成が起因する場合は調整を検討
14.
Copyright © 2014
K.K.Ashisuto All Rights Reserved. 14 ディスクソートの発生を避ける ● メモリ上でソートが行えるようwork_memパラメータを調整 ● work_memはセッションごとに確保される領域であるため、SETコマンドで処理に応じて 調整するのが望ましい ● 適切なwork_memが割り当てられていると、実行計画の決定時により良いプランを選択 ● ソート処理の詳細を確認 ● trace_sortパラメータを有効にし、ログ出力から詳細を確認 ● EXPLAIN ANALYZEコマンドで確認 postgres=# SET work_mem TO '256MB'; postgres=# SELECT ・・・・・・・ ORDER BY ・・・・・・・; /* バッチ処理などで大量のソートが発生 する場合SETコマンドでパラメータの変更を 行う */ LOG: internal sort ended, 330 KB used: CPU 0.00s/0.09u sec elapsed 0.15 sec STATEMENT: SELECT l.logno,e.empname,l.status FROM log_master l,emp e WHERE e.empno=l.empno; LOG: external sort ended, 269 disk blocks used: CPU 0.03s/0.20u sec elapsed 0.30 sec STATEMENT: SELECT l.logno,e.empname,l.status FROM log_master l,emp e WHERE e.empno=l.empno; ←メモリ上でソートができている ←ディスクソートが発生している -> Sort (cost=15016.32..15266.32 rows=100000 width=11) (actual time=128.817.. (・・・略・・・) Sort Key: l.empno Sort Method: external sort Disk: 2152kB -> Sort (cost=163.66..168.66 rows=2000 width=50) (actual time=1.600..10.439 rows=99951 loops=1) Sort Key: e.empno Sort Method: quicksort Memory: 330kB ←ディスクソートが発生している ←メモリ上でソートができている
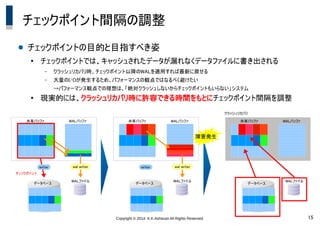
15.
Copyright © 2014
K.K.Ashisuto All Rights Reserved. 15 チェックポイント間隔の調整 ● チェックポイントの目的と目指すべき姿 ● チェックポイントでは、キャッシュされたデータが漏れなくデータファイルに書き出される – クラッシュリカバリ時、チェックポイント以降のWALを適用すれば最新に戻せる – 大量のI/Oが発生するため、パフォーマンスの観点ではなるべく避けたい →パフォーマンス観点での理想は、「絶対クラッシュしないからチェックポイントもいらない」システム ● 現実的には、クラッシュリカバリ時に許容できる時間をもとにチェックポイント間隔を調整 データベース WALファイル 共有バッファ WALバッファ writer wal writer チェックポイント データベース WALファイル 共有バッファ WALバッファ writer wal writer データベース WALファイル 共有バッファ WALバッファ 障害発生 クラッシュリカバリ
16.
Copyright © 2014
K.K.Ashisuto All Rights Reserved. 16 チェックポイント間隔の調整 ● チェックポイント間隔をパラメータで指定 ● checkpoint_segmentsを16個以上としてみる – checkpoint_segmentsは、「WALファイルが何個溜まったらチェックポイントするか」 WALファイル1つで16MB × 16個 = 256MB毎にチェックポイント ● checkpoint_timeoutを30分以上としてみる – checkpoint_timeoutは、「checkpoint_segmentsの閾値に達しなくてもチェックポイントする時間」 更新が少ない時間帯でも、30分に一回はチェックポイントしておく ● チェックポイントが行われるタイミングは以下 – checkpoint_segments パラメータで指定した数のWALファイルが生成されたとき – checkpoint_timeout パラメータで指定した時間が経過したとき – CHECKPOINTコマンドで明示的に実行 – データベースの正常停止 ● その他のチェックポイント関連パラメータ ● checkpoint_complation_targetで、チェックポイントを完了するまでの目標時間を設定 checkpoint_timeoutに対する割合で指定する 0.9程度に設定し、ゆっくりチェックポイントを実施させると、I/O量の安定化が期待できる
17.
Copyright © 2014
K.K.Ashisuto All Rights Reserved. 17 チェックポイント間隔の調整 ● 実際のチェックポイント頻度を調査する ● SQLでチェックポイントの回数を確認 ● ログにチェックポイント情報を出力する – log_checkpoint・・・・・・・・サーバログにチェックポイントの処理の詳細を記録 – checkpoint_warning・・・・指定時間より短い間隔でチェックポイント処理が事項された場合にログに警告を出力 postgres=# x postgres=# SELECT * FROM pg_stat_bgwriter; -[ RECORD 1 ]------+-------- checkpoints_timed | 4120 checkpoints_req | 0 buffers_checkpoint | 229843 buffers_clean | 57368 maxwritten_clean | 0 buffers_backend | 2334322 buffers_alloc | 1145231 timeoutでチェックポイントした回数 更新量の閾を超えチェックポイントした回数 /* checkpoint_reqの値が大きい場合、更新が 多く、チェックポイントが多発していること が考えられる */
18.
Copyright © 2014
K.K.Ashisuto All Rights Reserved. 18 VACUUM処理 ● VACUUMに対する考え方 ● 自動VACUUM推し ● VACUUMが適切に行われることで得られるメリット – 更新時に同一ページ内に空きがあることでHOTが効く – 加えて、HOTによる領域回収ができるため、次回VACUUM負荷が軽減される – テーブルファイルの肥大化を防ぎ、検索時のI/O量を適正にする ● (悪名高い)VACUUM FULL – 平常運用時に使う必要はない – ローカルディスクに余裕があるなら、テーブル再作成のメンテナンスとして – ANALYZEを別途実施しなければならない ● 注意点 ● 自動VACUUMによる性能影響は目安として10%~程度ある ● VACUUMの効果を得るには、必要なテーブルが正しくVACUUMされていること →特に、同一インスタンスで複数DBが稼働している場合 ● pg_stat_all_tablesのn_tup_hot_upd(HOTによる更新行数、多いほど良い)や、 n_dead_tup(VACUUM対象の行数、ずっと多いのはダメ)はチェックすること
19.
Copyright © 2014
K.K.Ashisuto All Rights Reserved. 19 pg_statsinfoを使ってみよう SQL
20.
Copyright © 2014
K.K.Ashisuto All Rights Reserved. 20 log.txt log.csv pg_statsinfoとは ● pg_statsinfo で、前述の確認項目を含むほぼすべての統計情報を収集 ● スナップショット型で取得し、リポジトリに格納 – Oracle の Statspack / AWR のような感覚で利用可能 – 平常時の処理傾向の把握と、性能劣化の予兆認識に活用できる ● 1つのリポジトリに対して、複数DBインスタンスを登録可能 ● pg_stats_reporter との組み合わせでブラウザでの参照も可能 ● pg_statsinfoコマンドで各種操作を行う – statsinfodの起動/停止、スナップショットの一覧表示、簡易レポート生成など 監視対象DBクラスタ 兼 リポジトリDB loggerpg_statsinfod 監視対象DBの 実行時統計、ログ、 OS情報の収集 OS情報 深刻度によるフィルタリング およびアラート出力 リポジトリDBに スナップショットを格納 pg_stats_reporter httpdと連動して レポート生成、表示
21.
Copyright © 2014
K.K.Ashisuto All Rights Reserved. 21 pg_statsinfoを使ってみる ● インストール ● PostgreSQLのconfigure時に--with-libxmlを追加しておくこと(rpmならOK) ● pg_statsinfoの設定はpostgresql.confに追記する shared_preload_libraries = 'pg_stat_statements,pg_statsinfo' pg_statsinfo.snapshot_interval = 3600 # スナップショットの取得間隔 pg_statsinfo.enable_maintenance = 'on' # 自動メンテナンス設定 pg_statsinfo.maintenance_time = '00:02:00' # 自動メンテナンス実行時刻設定 pg_statsinfo.repository_keepday = 7 # スナップショットの保持期間設定 log_filename = 'postgresql-%Y-%m-%d_%H%M%S.log' # ログファイル名を指定する log_min_messages = 'log' # ログへ出力するメッセージレベル。 pg_statsinfo.syslog_min_messages = 'error' # syslogに出力するログレベルを指定する。 pg_statsinfo.textlog_line_prefix = '%t %p %c-%l %x %q(%u, %d, %r, %a) ' # pg_statsinfoがテキストログに出力する際、各行の先頭に追加される書式を指定る。 # log_line_prefixと同じ形式で指定する。 pg_statsinfo.syslog_line_prefix = '%t %p %c-%l %x %q(%u, %d, %r, %a) ' # pg_statsinfoがsyslog経由でログを出力する際、各行の先頭に追加される書式を指定する。 pg_statsinfo.stat_statements_max = 30 $ cd <postgresのcontrib配下>/ $ tar zxvf pg_statsinfo-2.5.0.tar.gz $ cd pg_statsinfo-2.5.0 $ make USE_PGXS=1 $ su # make USE_PGXS=1 install
22.
Copyright © 2014
K.K.Ashisuto All Rights Reserved. 22 簡易レポート ● pg_statsinfoで、上述のDBチューニングの確認ポイントが全て確認可能 ● 簡易レポートの生成 レポート項目 内容 Summary 環境(ホスト名、バージョン)、スナップショットID(開始と終了)など DatabaseStatistics データベース単位の統計情報(キャッシュヒット率、トランザクション数など) InstanceActivity WAL出力量やセッション数 OSResourceUsage CPU(user/system/idle/iowait)の遷移および負荷状況(Load average) DiskUsage デバイス毎のI/O遷移 LongTransactions ロングトランザクション Lock Conflict 一定時間ロック状態が継続したSQL NotableTables 注意すべきテーブル(更新が多い/アクセスが多い/断片化) CheckpointActivity 原因別のチェックポイント回数や処理時間 AutovacuumActivity 自動VACUUMの発生状況 QueryActivity SQLや関数の情報(所要時間/実行回数など) $ pg_statsinfo -r All -U postgres -d pgdb1 /* -Uや-dでリポジトリDBを指定 */ /* -rでレポートの対象とするスナップショットを指定 */
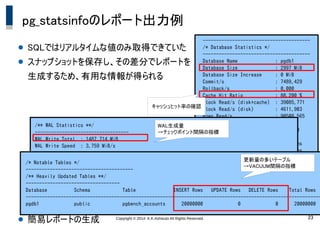
23.
Copyright © 2014
K.K.Ashisuto All Rights Reserved. 23 pg_statsinfoのレポート出力例 ---------------------------------------- /* Database Statistics */ ---------------------------------------- Database Name : pgdb1 Database Size : 2997 MiB Database Size Increase : 0 MiB Commit/s : 7489.429 Rollback/s : 0.000 Cache Hit Ratio : 88.200 % Block Read/s (disk+cache) : 39085.771 Block Read/s (disk) : 4611.903 Rows Read/s : 90508.565 Temporary Files : 2 Temporary Bytes : 763 MiB Deadlocks : 0 Block Read Time : 0.000 ms Block Write Time : 0.000 ms /** WAL Statistics **/ ----------------------------------- WAL Write Total : 1487.714 MiB WAL Write Speed : 3.759 MiB/s ----------------------------------- DateTime Location Segment File Write Size Write Size/s ------------------------------------------------------------------------------------------------ 2014-07-08 21:33 1/6257DC90 000000010000000100000062 1.541 MiB 0.082 MiB 2014-07-08 21:33 1/626575F8 000000010000000100000062 0.850 MiB 0.731 MiB : /* Notable Tables */ ---------------------------------------- /** Heavily Updated Tables **/ ----------------------------------- Database Schema Table INSERT Rows UPDATE Rows DELETE Rows Total Rows -------------------------------------------------------------------------------------------------------------- pgdb1 public pgbench_accounts 20000000 0 0 20000000 キャッシュヒット率の確認 WAL生成量 →チェックポイント間隔の指標 更新量の多いテーブル →VACUUM間隔の指標 ● SQLではリアルタイムな値のみ取得できていた ● スナップショットを保存し、その差分でレポートを 生成するため、有用な情報が得られる ● 簡易レポートの生成
24.
Copyright © 2014
K.K.Ashisuto All Rights Reserved. 24 SQLチューニングの基本 SQL
25.
Copyright © 2014
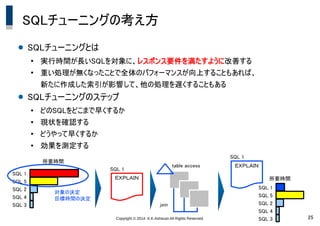
K.K.Ashisuto All Rights Reserved. 25 SQLチューニングの考え方 ● SQLチューニングとは ● 実行時間が長いSQLを対象に、レスポンス要件を満たすように改善する ● 重い処理が無くなったことで全体のパフォーマンスが向上することもあれば、 新たに作成した索引が影響して、他の処理を遅くすることもある ● SQLチューニングのステップ ● どのSQLをどこまで早くするか ● 現状を確認する ● どうやって早くするか ● 効果を測定する 所要時間 SQL 1 SQL 5 SQL 2 SQL 4 SQL 3 対象の決定 目標時間の決定 SQL 1 EXPLAIN table access join SQL 1 EXPLAIN 所要時間 SQL 1 SQL 5 SQL 2 SQL 4 SQL 3
26.
Copyright © 2014
K.K.Ashisuto All Rights Reserved. 26 チューニング対象を決定 ● 統計情報から実行時間の長いSQLを確認する ● pg_stat_activity ● pg_stat_statements(contribツール) ⇒ pg_statsinfoと連携してレポート可能 ● エラーログへの出力から実行時間の長いSQLを確認する ● postgresql.conf の log_min_duration_statementパラメータ – パラメータで指定した時間以上を要するSQLをサーバログに出力 ● auto_explain(contribツール) – 実行に一定時間を要したSQL文と実行計画をサーバログに出力 ● キャッシュヒット率やアクセスブロック数を基準にすることもある ● 1行を対象にした検索なのに、大量のブロックにアクセスしている場合など ● pg_stat_all_tables/pg_statio_all_tables 所要時間 SQL 1 SQL 5 SQL 2 SQL 4 SQL 3 対象の決定 目標時間の決定
27.
Copyright © 2014
K.K.Ashisuto All Rights Reserved. 27 実行計画の確認 ● EXPLAIN または EXPLAIN ANALYZE でSQLの実行計画を取得 ● 計画ツリーの階層が深いものがから順に実行されている – 通常、各テーブルへのアクセスから始まる ● EXPLAIN ANALYZEの場合、実際にSQLが実行される – 所要時間、取得した行数、ループ回数が記録される – SQLが実行されてしまうため、更新処理の場合は必ずBEGINでトランザクションを開始してから実施する EXPLAIN EXPLAIN postgres=# EXPLAIN SELECT b.logno,e.empname,b.log_text FROM log_master m,log_body b,emp e WHERE b.logno=m.logno AND e.empno=m.empno AND m.status = 'WI'; QUERY PLAN ------------------------------------------------------------------------------------------ Hash Join (cost=79.00..1754.21 rows=10000 width=66) Hash Cond: (m.empno = e.empno) -> Merge Join (cost=0.00..1525.21 rows=10000 width=24) Merge Cond: (m.logno = b.logno) -> Index Scan using log_master_pkey on log_master m (cost=0.00..6907.33 rows=31373 width=8) Filter: (status = 'WI'::bpchar) -> Index Scan using log_body_pkey on log_body b (cost=0.00..707.27 rows=10000 width=20) -> Hash (cost=54.00..54.00 rows=2000 width=50) -> Seq Scan on emp e (cost=0.00..54.00 rows=2000 width=50) 計画ツリー 計画タイプ(プラン) コストの推定値 推定行数や列幅
28.
Copyright © 2014
K.K.Ashisuto All Rights Reserved. 28 PostgreSQLの計画タイプ ● 計画タイプを確認し、意図した方法が選択されているかを調査 ● 必要なIndexが作成されているか ● 意図したプランが選択されるSQLを書いているか 計画タイプ 内容 Seq Scan 全表スキャン:表内の大量の行にアクセスする場合に有効 Index Scan 索引スキャン:表内のごく一部の行にのみアクセスする場合に有効 Index Only Scan 索引のリーフブロックのみにアクセスするスキャン(表へのアクセスをスキップ) Bitmap Index Scan ビットマップ使用した索引スキャン Bitmap Heap Scan ビットマップスキャンで表にアクセス Function Scan ファンクションの実行結果に対するスキャン Nested Loop ネステッドループ結合:片方の表のうち、ごく少数の結果を条件として他方の表からデータを取得 Merge Join マージ結合:両方の表の行数が多い場合、ソートし、上から順に値を比較して該当行を抽出 Hash Join ハッシュ結合:表の行数に差があり、かつ小さい表の重複が少ない場合に有効 table access join
29.
Copyright © 2014
K.K.Ashisuto All Rights Reserved. 29 対策:索引が使われないパターン ● 演算/関数処理 ● データ型の暗黙変換 ● NOT条件 など、SQLの書き方で索引が 使われないパターンを紹介
30.
Copyright © 2014
K.K.Ashisuto All Rights Reserved. 30 対策:索引を活用してソートを省略 ● ソート ● 集計 など、索引があることで表への アクセスをスキップして処理を 行えるパターンを紹介
31.
Copyright © 2014
K.K.Ashisuto All Rights Reserved. 31 対策:結合 ● PostgreSQLは結合のプランが複数あり、複雑な結合にも強い ● それでも意図した結合にならない場合、enable_*join パラメータでプランの候補を検討 ● デフォルトでは、FORM句に8個のテーブル、JOINも8テーブルまでプランを評価 例えば テーブルA,B,Cにアクセスするクエリで、A,Bへのアクセスは、事前に定義したビューを使っている。 ・A,Bを結合したビューとしてデータをとってきたあと、Cと突き合わせて結果を得るか ・ビューの元はテーブルA,Bなので、ABCを柔軟に組み合わせ効率の良いプランを探すか というプランナの戦略を指定(本例はテーブル3個だが、デフォルトでは8個を超えた時点でプランナがあまり考えなくなる) postgres=# SET enable_hashjoin TO off; postgres=# SELECT ・・・・・・・ FROM A JOIN B ON ・・・・・・・; /* 意図した結合方式を使わせたい場合、セッ ション内でSETコマンドでパラメータの変更を 行う */ postgres=# SET from_collapse_limit TO 16; postgres=# SET join_collapse_limit TO 16; postgres=# SELECT ・・・・・・・ FROM A JOIN B ON ・・・・・・・; /* プラン生成に時間がかかるが、効率的な結 合を行うようになり、実行時間が劇的に改善 される可能性がある */
32.
Copyright © 2014
K.K.Ashisuto All Rights Reserved. 32 高速化を期待されるが注意が必要なもの ● Materiarized View ● PostgreSQL9.3でマテリアライズド・ビューが使用可能となった ● 実体をもったビューで、結合や集計結果を保存しておくことで高速にアクセスできる ● ただし、現在は以下の制約があり、今後の機能向上に期待 – リフレッシュ時に元のテーブルに対して非常に強いロックを取得 – 自動リフレッシュや差分(高速)リフレッシュがなく、手動の完全リフレッシュのみ ● Index Only Scan ● PostgreSQL9.2でIndex Only Scanが使用可能となった ● インデックスで必要なデータが得られる場合、テーブルへのアクセスをスキップする機能 ● ただし、対象のテーブルがVACUUM直後(VACUUM後に更新されていない)ことが 選択される条件であり、使用する場合は注意が必要
33.
Copyright © 2014
K.K.Ashisuto All Rights Reserved. 33 PostgreSQL9.4betaの話
34.
Copyright © 2014
K.K.Ashisuto All Rights Reserved. 34 性能関連でのPostgreSQL 9.4への期待 ● 性能に関連するいくつかの変更が明らかになっている ● 新しいデータ型 JSONB型 ● GINインデックスの軽量・高速化 →この2つが本バージョンの目玉として取り上げられている ● WALロックの改善 ● hugepageへの対応 →マイナーな変更だが、PostgreSQLの適用領域を拡大する要因かも ● 運用担当者はチェックしておくべき変更点 ● pg_prewarm ● システムパラメータの動的かつ永続的な変更が可能に 参考文献 「Incoming PostgreSQL 9.4 次バージョンの新機能をご紹介」 2014年6月19日 db tech showcase 大阪 2014
35.
Copyright © 2014
K.K.Ashisuto All Rights Reserved. 35 JSONB型とGINインデックス ● JSONデータを解析、整形したバイナリとして格納するJSONB型 ● 従来のJSON型と比べて高速、軽量 ● GINインデックスに対応 ● GIN(汎用転置)インデックスのサイズ削減、性能向上 ● 配列、ハッシュ(hstore)、全文検索テキストなど、複数要素を持つ データ型に対して「ある要素を持つもの」を検索するときに使われる ● 互いに進化することで、NoSQL製品に負けない非リレーションにも対応 参考文献 「Incoming PostgreSQL 9.4 次バージョンの新機能をご紹介」 2014年6月19日 db tech showcase 大阪 2014
36.
Copyright © 2014
K.K.Ashisuto All Rights Reserved. 36 hugepage対応とWALロックの軽減 ● 大規模メモリを扱うRDBMSでは、メモリ管理のオーバヘッドが懸念される ● 特に、shared_buffersが8GBを超え、同時接続数が非常に多く、軽量な処理を多数 実行するような場合に、CPUが高騰してしまう ● Linuxの従来のページを扱う場合、RDBMS側で非常に多くのページ数を管理しなければ ならないためCPU負荷が高くなることが原因 ● PostgreSQL 9.4 から、Linuxのhugepageをサポートする ● RDBMSでは障害に備えて全ての変更を変更履歴として書き出す ● 避けては通れない処理であり、これがしばしばボトルネックとなる ● PostgreSQL 9.4 では、更新に対するWAL生成量が減る(更新フィールドのみをWAL出力) ● PostgreSQL 9.4 では、WAL出力をパラレルで実行 ● これらの組み合わせにより、高性能なサーバスペックを活かし、 より広い用途でPostgreSQLを活用できる可能性が考えられる 参考文献 「Incoming PostgreSQL 9.4 次バージョンの新機能をご紹介」 2014年6月19日 db tech showcase 大阪 2014 (宗近 龍一郎氏の講演資料より) 「PostgreSQL - 進化に挑戦し続けるロードマップ ~v9.4 v9.5の概要を明らかに」2014年7月17日 EDB Summit (Bruce Momjian氏の講演資料より)
37.
Copyright © 2014
K.K.Ashisuto All Rights Reserved. 37 運用の変更 ● pg_prewarm ● 指定したテーブルやインデックスのデータをshared_buffersやOSバッファに載せる ● contribツールとして9.4で追加される ● EXPLAIN ANALYZE出力が改善 ● プラン作成時間と実行時間が別々に表示されるように変更される ● ALTER SYSTEMコマンド ● postgresql.confとは別にpostgresql.conf.autoを作成し、パラメータの変更を永続的に 反映させることができる 参考文献 「Incoming PostgreSQL 9.4 次バージョンの新機能をご紹介」 2014年6月19日 db tech showcase 大阪 2014
38.
Copyright © 2014
K.K.Ashisuto All Rights Reserved. 38 本日のまとめ ● DBチューニング ● 構築時から考えておくべきポイントを整理 ● パラメータチューニングと、現状の確認 ● SQLチューニング ● 実行計画の確認方法を解説 ● 各プランの特徴を整理 ● pg_statsinfoの紹介 ● チューニングに役立つ情報が確認可能 ● PostgreSQL 9.4 betaの話 ● 性能関連を簡単に紹介 パラメータ名 推奨設定 反映タイミング shared_buffers 物理メモリの25% サーバ再起動 wal_buffers 自動任せ サーバ再起動 work_mem 処理ごと 即時 checkpoint_segments 16以上 再読み込み checkpoint_timeout 30分 再読み込み checkpoint_complation _target 0.9 再読み込み 性能関連パラメータ一覧 SQLチューニングの流れ ステップ PostgreSQLでの方法 問題となるSQLを特定 統計情報、ログ出力 実行計画の取得 EXPLAIN ANALYZE 対処の実施 SQL修正、索引の調整 効果の測定 TAT測定、実行計画取得 ➢ハンズオンに続く
Download














![Copyright © 2014 K.K.Ashisuto All Rights Reserved. 17
チェックポイント間隔の調整
● 実際のチェックポイント頻度を調査する
●
SQLでチェックポイントの回数を確認
●
ログにチェックポイント情報を出力する
– log_checkpoint・・・・・・・・サーバログにチェックポイントの処理の詳細を記録
– checkpoint_warning・・・・指定時間より短い間隔でチェックポイント処理が事項された場合にログに警告を出力
postgres=# x
postgres=# SELECT * FROM pg_stat_bgwriter;
-[ RECORD 1 ]------+--------
checkpoints_timed | 4120
checkpoints_req | 0
buffers_checkpoint | 229843
buffers_clean | 57368
maxwritten_clean | 0
buffers_backend | 2334322
buffers_alloc | 1145231
timeoutでチェックポイントした回数
更新量の閾を超えチェックポイントした回数
/* checkpoint_reqの値が大きい場合、更新が
多く、チェックポイントが多発していること
が考えられる */](https://image.slidesharecdn.com/postgresqlslideshare-140720150932-phpapp02/85/PostgreSQL-17-320.jpg)



































![[Cloud OnAir] BigQuery の仕組みからベストプラクティスまでのご紹介 2018年9月6日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/dddddd-180906091548-thumbnail.jpg?width=640&height=640&fit=bounds)




















![[db tech showcase Tokyo 2015] B36:Hitachi Advanced Data Binder 実践SQLチューニング方法 ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015b36hadbhitachi-150619110029-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)

![[db tech showcase Tokyo 2016] C32: 世界一速いPostgreSQLを目指せ!インメモリカラムナの実現 by 富士通株式会...](https://cdn.slidesharecdn.com/ss_thumbnails/decdzrorcuek1megqnk7-signature-4c0dd3fcb9eb3d17930cacb079ea1fd12d54c70d5a7ef5cbe3514e2f97cef80f-poli-160902010202-thumbnail.jpg?width=640&height=640&fit=bounds)

![[D33] そのデータベース 5年後大丈夫ですか by Hiromu Goto](https://cdn.slidesharecdn.com/ss_thumbnails/d33hp-140623211550-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)











![[OSC2016沖縄]商用DBからPostgreSQLへの移行入門](https://cdn.slidesharecdn.com/ss_thumbnails/osc2016okinawadbmigrationtopostgres-160704053748-thumbnail.jpg?width=640&height=640&fit=bounds)

![[9.5新機能]追加されたgroupbyの使い方](https://cdn.slidesharecdn.com/ss_thumbnails/9-151214013505-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Postgre sql9.4新機能]レプリケーション・スロットの活用](https://cdn.slidesharecdn.com/ss_thumbnails/postgresql9-140909012453-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)