Copyright (C) DeNACo.,Ltd. All Rights Reserved.
「画像」だけでなく「音」にもCNNが使える
5
W. Dai et al.
Very Deep Convolutional Neural Networks for Raw
Waveforms,
ICASSP 2017.
16kHzの音声だと
約2秒の音声
カーネルサイズ: 80
フィルタ数: 256
カーネルサイズ: 3
フィルタ数: 256
音声波形は1次元の時系列データ
Conv2dではなく
Conv1dを使う
6.
Copyright (C) DeNACo.,Ltd. All Rights Reserved.
音の表現 (2) メルスペクトログラム
メルスペクトログラム(mel spectrogram)
⁃ 波形に対してSTFT(短時間フーリエ変換)を適用
⁃ 人の聴覚知覚に合うように周波数軸をメルスケールに変換
⁃ 横軸が時間、縦軸が周波数の2次元データとして表せる
6
時間(単位: フレーム)
周波数(メルスケール)
Audio features for web-based ML
https://towardsdatascience.com/audio-features-for-web-based-ml-555776733bae
7.
Copyright (C) DeNACo.,Ltd. All Rights Reserved.
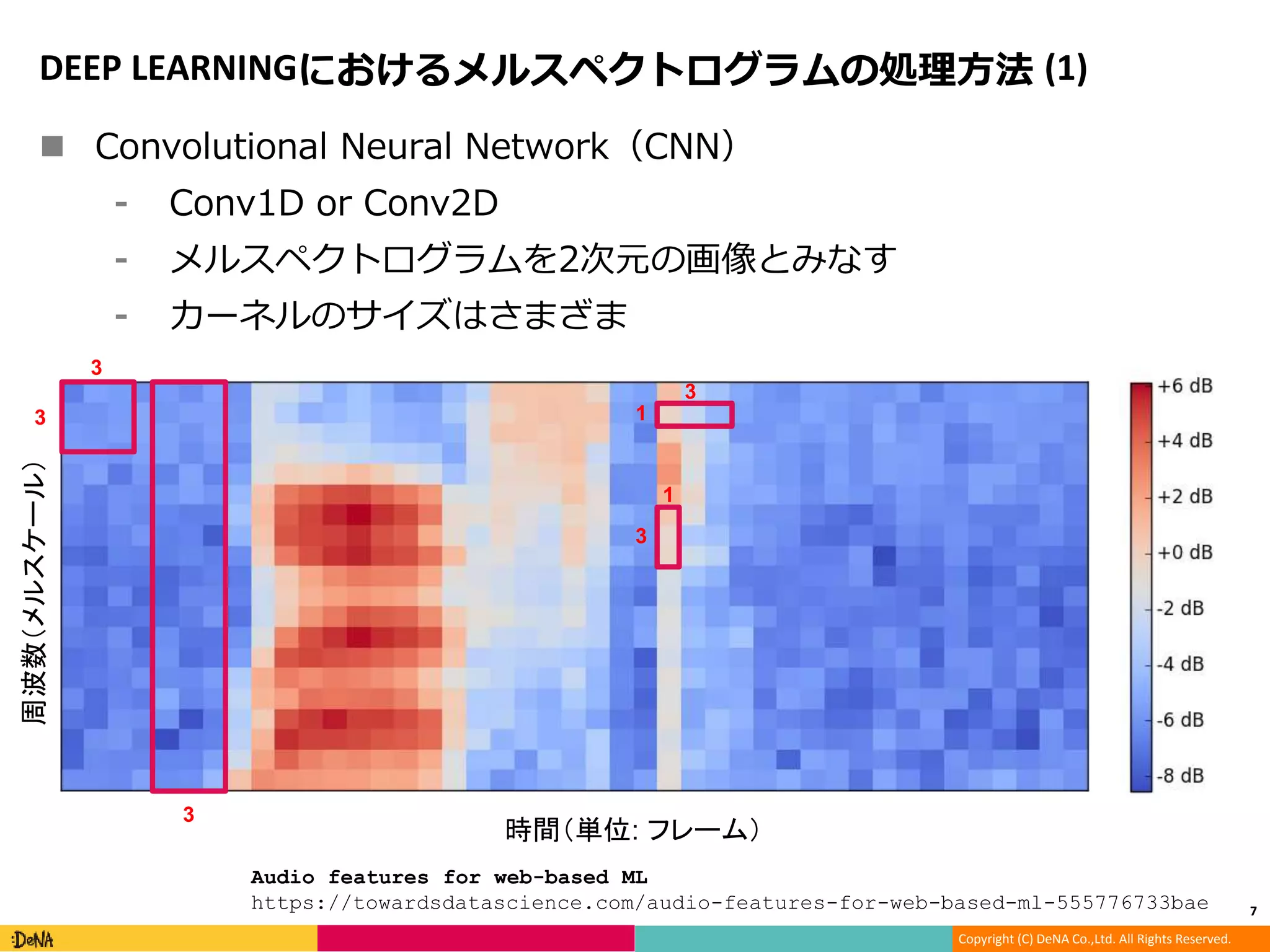
DEEP LEARNINGにおけるメルスペクトログラムの処理方法 (1)
7
Convolutional Neural Network(CNN)
⁃ Conv1D or Conv2D
⁃ メルスペクトログラムを2次元の画像とみなす
⁃ カーネルのサイズはさまざま
時間(単位: フレーム)
周波数(メルスケール)
3
3
3
3
1
3
1
Audio features for web-based ML
https://towardsdatascience.com/audio-features-for-web-based-ml-555776733bae
8.
Copyright (C) DeNACo.,Ltd. All Rights Reserved.
DEEP LEARNINGにおけるメルスペクトログラムの処理方法 (2)
Recurrent Neural Network(RNN)
⁃ メルスペクトログラムを1次元ベクトルの時系列データとみなす
⁃ 文章を埋め込み単語ベクトルの系列とみなすのと似ている
⁃ 系列長が長くなりRNNで学習できない
8
周波数(メルスケール)
時間(単位: フレーム)
Audio features for web-based ML
https://towardsdatascience.com/audio-features-for-web-based-ml-555776733bae
9.
Copyright (C) DeNACo.,Ltd. All Rights Reserved.
Convolutional Recurrent Neural Network (CRNN) = CNN + RNN
9
K. Choi et al.
Convolutional Recurrent Neural Networks for Music Classification,
ICASSP 2017.
メルスペクトログラム
Conv2D
10.
Copyright (C) DeNACo.,Ltd. All Rights Reserved.
NIPS2017の「音」関連研究の概要 (1)
10
Speech Audio Music
認識
Speech Recognition
Speech Emotion Recognition
Gender/Age Recognition
Speaker Identification
Language Identification
Audio Classification
Environmental Sound Recognition
Scene Recognition
Music Tagging
Mood Recognition
Song Identification
生成
Speech Synthesis
Emotional Speech Synthesis
Singing Voice Synthesis
Voice Conversion
Environmental Sound Generation
Audio Style Transfer
Music Generation
Music Style Transfer
検出
Voice Activity Detection
Keyword Spotting
Singing Voice Detection
Audio Event Detection Melody Tracking
Beat Tracking
BGM detection
その他
Speech Enhancement
Sound Source Separation
Singing Voice Separation
Noise Reduction
Sound Representation Music Information Retrieval
Music Recommendation
Hit prediction
赤: 本会議
緑: ワークショップ
11.
Copyright (C) DeNACo.,Ltd. All Rights Reserved.
NIPS2017の「音」関連研究の概要 (1)
11
Speech Audio Music
認識
Speech Recognition
Speech Emotion Recognition
Gender/Age Recognition
Speaker Identification
Language Identification
Audio Classification
Environmental Sound Recognition
Scene Recognition
Music Tagging
Mood Recognition
Song Identification
生成
Speech Synthesis
Emotional Speech Synthesis
Singing Voice Synthesis
Voice Conversion
Environmental Sound Generation
Audio Style Transfer
Music Generation
Music Style Transfer
検出
Voice Activity Detection
Keyword Spotting
Singing Voice Detection
Audio Event Detection Melody Tracking
Beat Tracking
BGM detection
その他
Speech Enhancement
Sound Source Separation
Singing Voice Separation
Noise Reduction
Sound Representation Music Information Retrieval
Music Recommendation
Hit prediction
Analyzing Hidden Representations in End-to-
End Automatic Speech Recognition
End-to-end音声認識における内部表現の可視化
音声からテキストへのマッピングを直接学習
従来の「音素」という概念は隠れ層のどこかでモデ
ル化されているのだろうか?
低レイヤで音素がモデル化されていることを確認!
Deep Voice 2
End-to-end音声合成において話者の埋め込みベクトル
を用いることで1つのニューラルネットから複数話者
の音声を合成することに成功!
Uncovering Latent Style Factors for
Expressive Speech Synthesis
Tacotronに潜在変数を導入して韻律スタイルを制御で
きるように拡張。スタイルは教師なしで学習するた
め人による解釈は必要
赤: 本会議
緑: ワークショップ
12.
Copyright (C) DeNACo.,Ltd. All Rights Reserved.
NIPS2017の「音」関連研究の概要 (2)
12
Speech Audio Music
認識
Speech Recognition
Speech Emotion Recognition
Gender/Age Recognition
Speaker Identification
Language Identification
Audio Classification
Environmental Sound Recognition
Scene Recognition
Music Tagging
Mood Recognition
Song Identification
生成
Speech Synthesis
Emotional Speech Synthesis
Singing Voice Synthesis
Voice Conversion
Environmental Sound Generation
Audio Style Transfer
Music Generation
Music Style Transfer
検出
Voice Activity Detection
Keyword Spotting
Singing Voice Detection
Audio Event Detection Melody Tracking
Beat Tracking
BGM detection
その他
Speech Enhancement
Sound Source Separation
Singing Voice Separation
Noise Reduction
Sound Representation Music Information Retrieval
Music Recommendation
Hit prediction
Utilizing Domain Knowledge in End-to-End
Audio Processing
波形からメルスペクトログラムへ変換する高速な
CNNネットワークを提案
Raw Waveform based Audio Classification
Using Sample Level CNN Architecture
音声認識、楽曲分類、環境音分類の3つのタスクにお
いて波形入力のCNNアーキテクチャでSOTAに近い精
度が出た
Imaginary Soundcape
景色のシーン画像を入力するとそのシーンに適した
音声を再生するシステムを提案。
NELS: Never Ending Learner of Sounds
YouTubeから動画をクローリングして半教師あり学習
の枠組みで600以上の音声クラスにインデキシングす
るシステムを提案
赤: 本会議
緑: ワークショップ
13.
Copyright (C) DeNACo.,Ltd. All Rights Reserved.
NIPS2017の「音」関連研究の概要 (3)
13
Speech Audio Music
認識
Speech Recognition
Speech Emotion Recognition
Gender/Age Recognition
Speaker Identification
Language Identification
Audio Classification
Environmental Sound Recognition
Scene Recognition
Music Tagging
Mood Recognition
Song Identification
生成
Speech Synthesis
Emotional Speech Synthesis
Singing Voice Synthesis
Voice Conversion
Environmental Sound Generation
Audio Style Transfer
Music Generation
Music Style Transfer
検出
Voice Activity Detection
Keyword Spotting
Singing Voice Detection
Audio Event Detection Melody Tracking
Beat Tracking
BGM detection
その他
Speech Enhancement
Sound Source Separation
Singing Voice Separation
Noise Reduction
Sound Representation Music Information Retrieval
Music Recommendation
Hit prediction
End-to-end learning for music audio tagging
at scale
Pandoraの120万曲の大規模データを使って楽曲タギ
ングの実験。入力が波形とメルスペクトログラムの
どちらがよいかを比較実験
Neural Translation of Music Style
楽譜を入力として音楽ジャンルのスタイル(ダイナ
ミクス)を出力するGenreNetを提案
赤: 本会議
緑: ワークショップ
14.
Copyright (C) DeNACo.,Ltd. All Rights Reserved.
SPEECH & SOUND @ NIPS2017
本会議
⁃ Deep Voice 2: Multi-Speaker Neural Text-to-Speech
WORKSHOP - Machine Learning for Creativity and Design
⁃ Imaginary soundscape: cross-modal approach to generate
pseudo sound environments
14
SPEECH
AUDIO
15.
Copyright (C) DeNACo.,Ltd. All Rights Reserved.
Deep Voice 2: Multi-Speaker Neural Text-to-Speech
S. O. Arik, G. Diamos, A. Gibiansky, J. Miller, K. Peng, W. Ping, J. Raiman and Y. Zhou
Baidu Silicon Valley Artificial Intelligence Lab
15
16.
Copyright (C) DeNACo.,Ltd. All Rights Reserved.
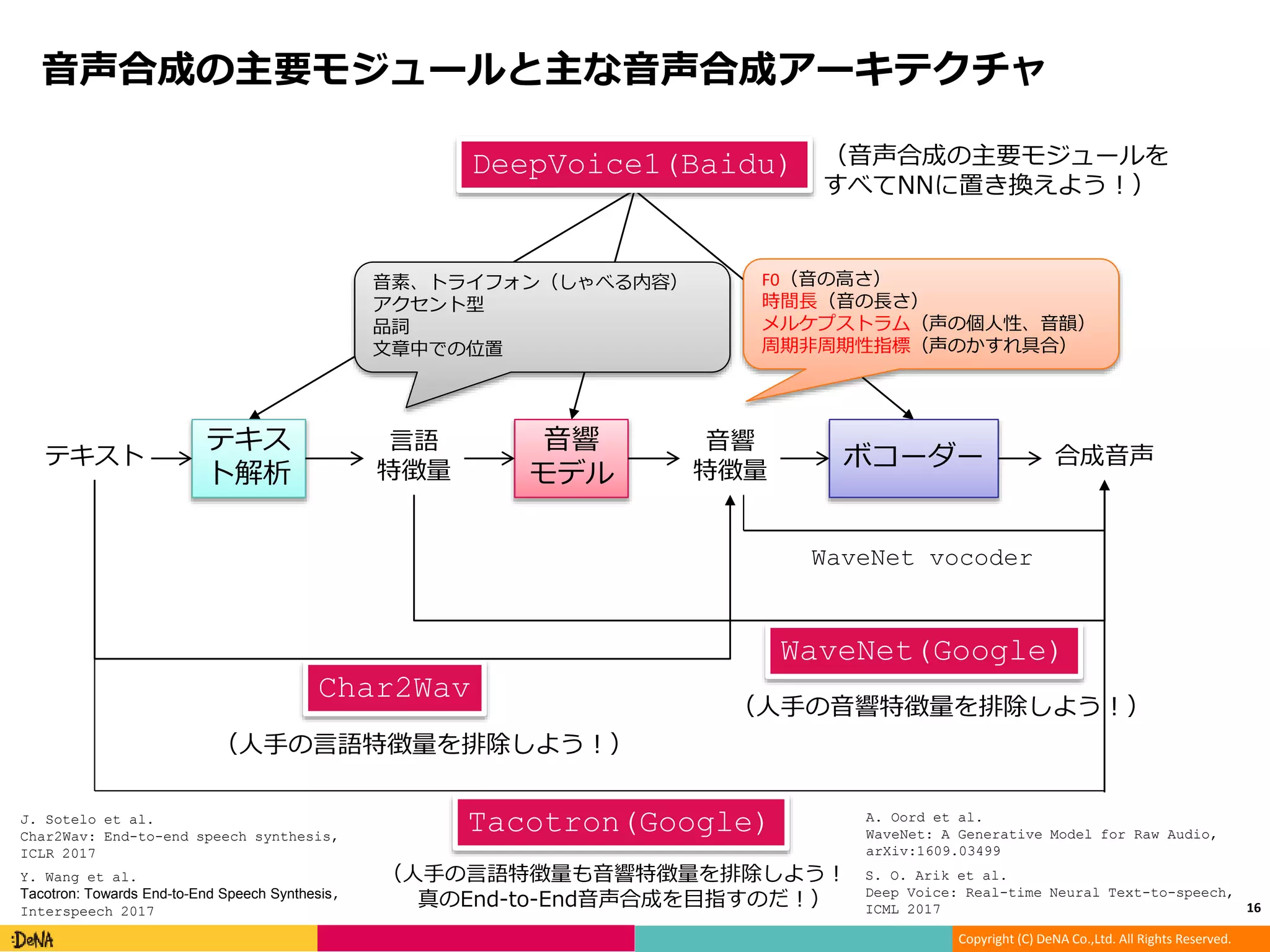
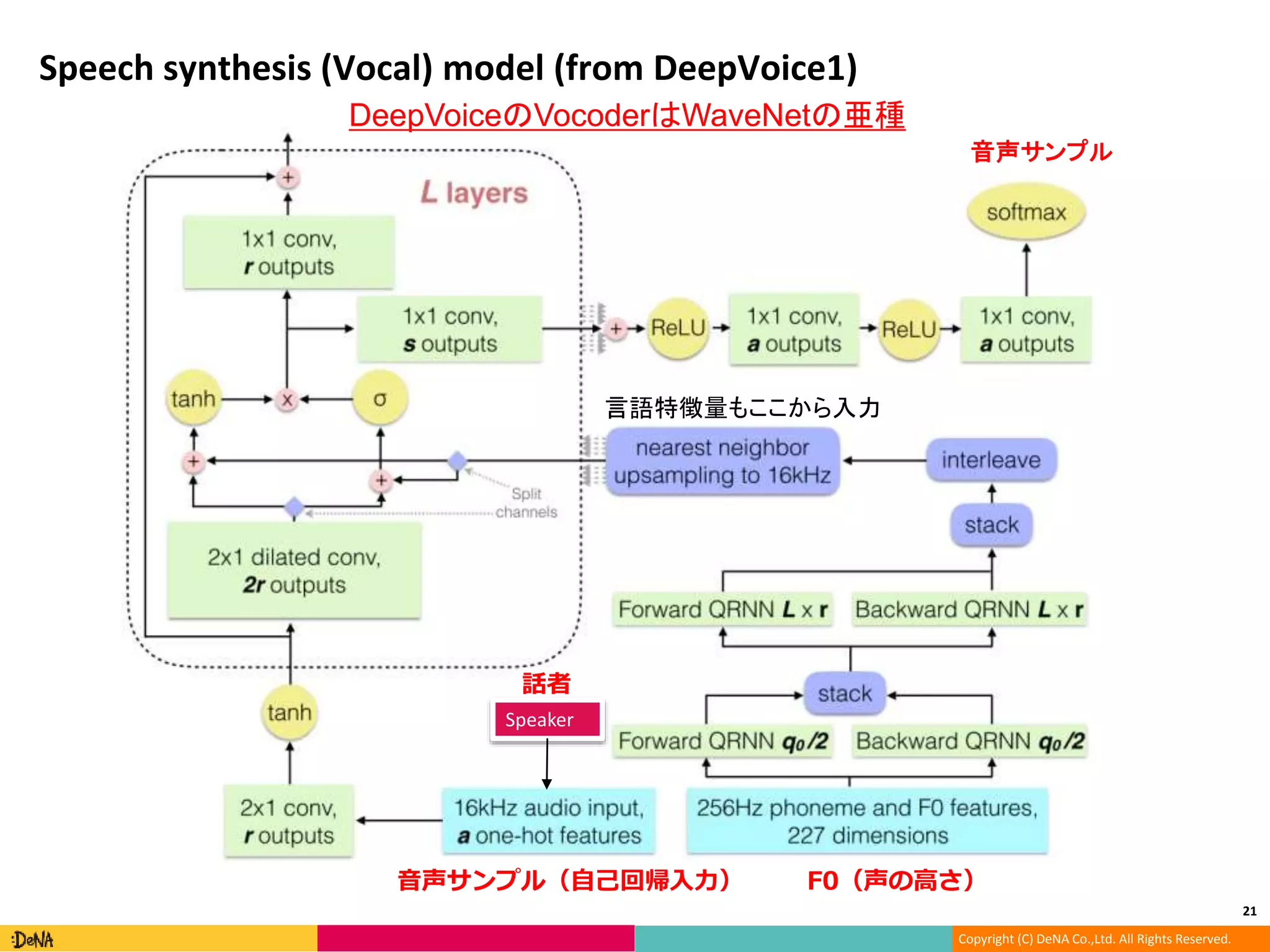
DeepVoice1(Baidu) (音声合成の主要モジュールを
すべてNNに置き換えよう!)
音声合成の主要モジュールと主な音声合成アーキテクチャ
16
テキス
ト解析
テキスト
言語
特徴量
合成音声
音響
モデル
ボコーダー
音響
特徴量
F0(音の高さ)
時間長(音の長さ)
メルケプストラム(声の個人性、音韻)
周期非周期性指標(声のかすれ具合)
音素、トライフォン(しゃべる内容)
アクセント型
品詞
文章中での位置
Char2Wav
(人手の言語特徴量を排除しよう!)
WaveNet(Google)
(人手の音響特徴量を排除しよう!)
WaveNet vocoder
Tacotron(Google)
(人手の言語特徴量も音響特徴量を排除しよう!
真のEnd-to-End音声合成を目指すのだ!)
J. Sotelo et al.
Char2Wav: End-to-end speech synthesis,
ICLR 2017
Y. Wang et al.
Tacotron: Towards End-to-End Speech Synthesis,
Interspeech 2017
A. Oord et al.
WaveNet: A Generative Model for Raw Audio,
arXiv:1609.03499
S. O. Arik et al.
Deep Voice: Real-time Neural Text-to-speech,
ICML 2017
17.
Copyright (C) DeNACo.,Ltd. All Rights Reserved.
複数話者モデルへの拡張
⁃ 学習した話者の埋め込みベクトルを入力とすることで一つの
(ニューラルネットワーク)モデルから複数話者の音声を合成でき
るようにした!
比較手法として Tacotron(Google)を拡張した!
⁃ ボコーダーにWaveNetを導入
⁃ 話者の埋め込みベクトルで複数話者の音声を合成可能に
Deep Voice2 の貢献
17
18.
Copyright (C) DeNACo.,Ltd. All Rights Reserved.
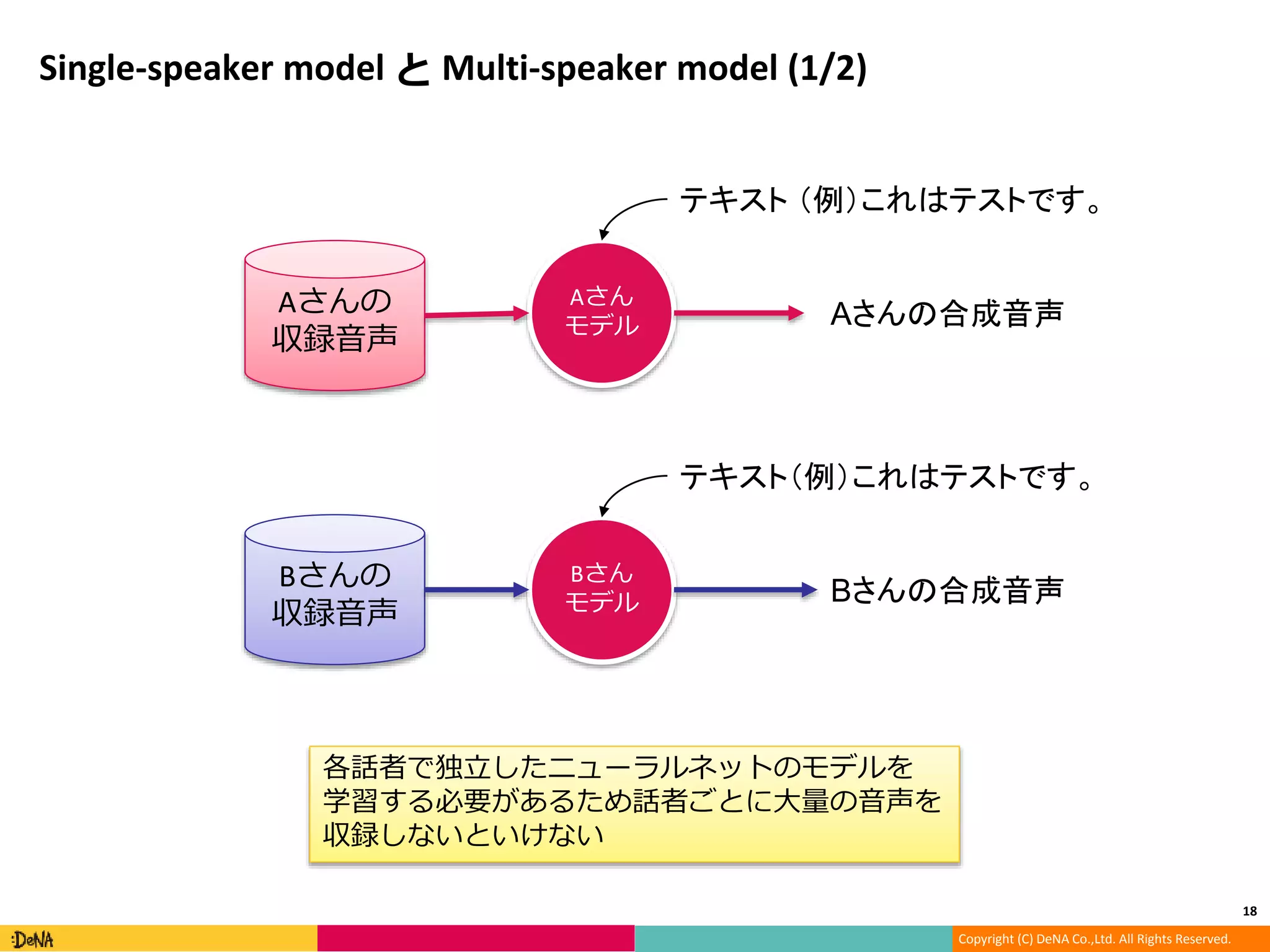
Single-speaker model と Multi-speaker model (1/2)
18
Aさんの
収録音声
Bさんの
収録音声
Aさん
モデル
Bさん
モデル
Aさんの合成音声
Bさんの合成音声
各話者で独立したニューラルネットのモデルを
学習する必要があるため話者ごとに大量の音声を
収録しないといけない
テキスト (例)これはテストです。
テキスト(例)これはテストです。
19.
Copyright (C) DeNACo.,Ltd. All Rights Reserved.
Single-speaker model と Multi-speaker model (2/2)
19
Aさんの
収録音声
Bさんの
収録音声
複数
話者
モデル
Aさんの合成音声
Bさんの合成音声
複数話者の音声を使うことでモデルパラメータを
共有できるため各話者の音声は少量でもOK
テキスト + Aさんの埋め込みベクトル
テキスト + Bさんの埋め込みベクトル
話者の埋め込みベクトルを入力することで
1つのモデルで異なる話者の音声を合成できる
(モデルとともに訓練される!)
Copyright (C) DeNACo.,Ltd. All Rights Reserved.
実験結果
24
MOS (Mean Opinion Score)
合成音声の品質の主観評価(1-5点)
話者の分類精度
Inception Score っぽい指標
原音で学習した話者分類モデル(CNN)で
合成音声の話者を正しく分類できるか?
108話者
各話者400発話
477話者
各話者30分
25.
Copyright (C) DeNACo.,Ltd. All Rights Reserved.
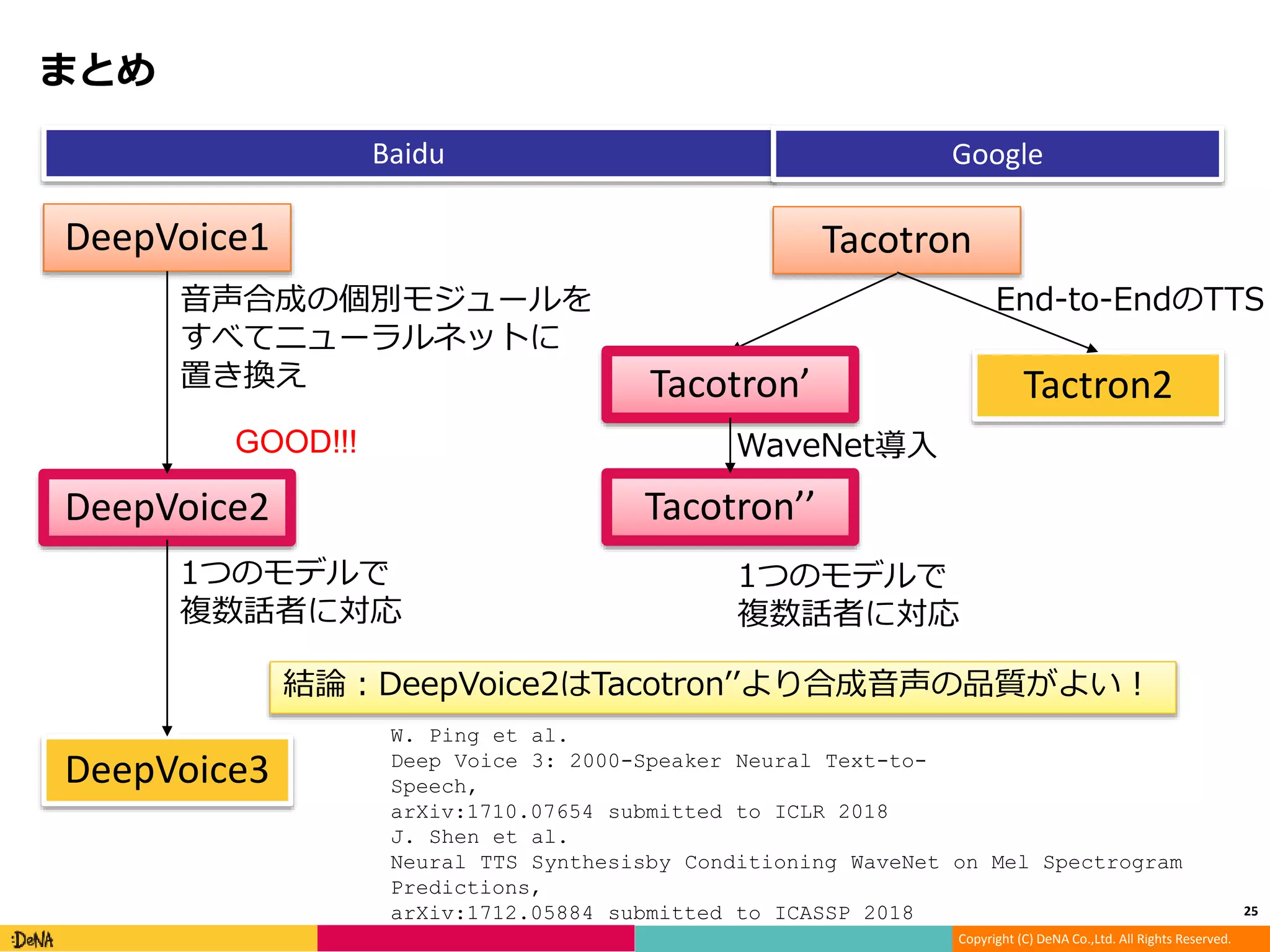
まとめ
25
DeepVoice1
DeepVoice2
Tacotron
DeepVoice3
Baidu Google
音声合成の個別モジュールを
すべてニューラルネットに
置き換え
1つのモデルで
複数話者に対応
Tacotron’
WaveNet導入
Tacotron’’
1つのモデルで
複数話者に対応
結論:DeepVoice2はTacotron’’より合成音声の品質がよい!
GOOD!!!
End-to-EndのTTS
Tactron2
W. Ping et al.
Deep Voice 3: 2000-Speaker Neural Text-to-
Speech,
arXiv:1710.07654 submitted to ICLR 2018
J. Shen et al.
Neural TTS Synthesisby Conditioning WaveNet on Mel Spectrogram
Predictions,
arXiv:1712.05884 submitted to ICASSP 2018
26.
Copyright (C) DeNACo.,Ltd. All Rights Reserved.
Imaginary soundscape: cross-modal approach to generate
pseudo sound environments
Y. Kajihara, S. Dozono and N. Tokui
Qosmo inc. & The Univ. of Tokyo
26
create with AI
http://createwith.ai/
27.
Copyright (C) DeNACo.,Ltd. All Rights Reserved.
Imaginary Soundscape の貢献
シーンの画像を入力するとそのシーンの(疑似)環境音
(Soundscape)を再生するシステムを作った!
Google Street Viewの街中探検で音まで聞こえてくる!
シーン画像と環境音のマルチモーダル技術
27
http://imaginarysoundscape.qosmo.jp/
Copyright (C) DeNACo.,Ltd. All Rights Reserved.
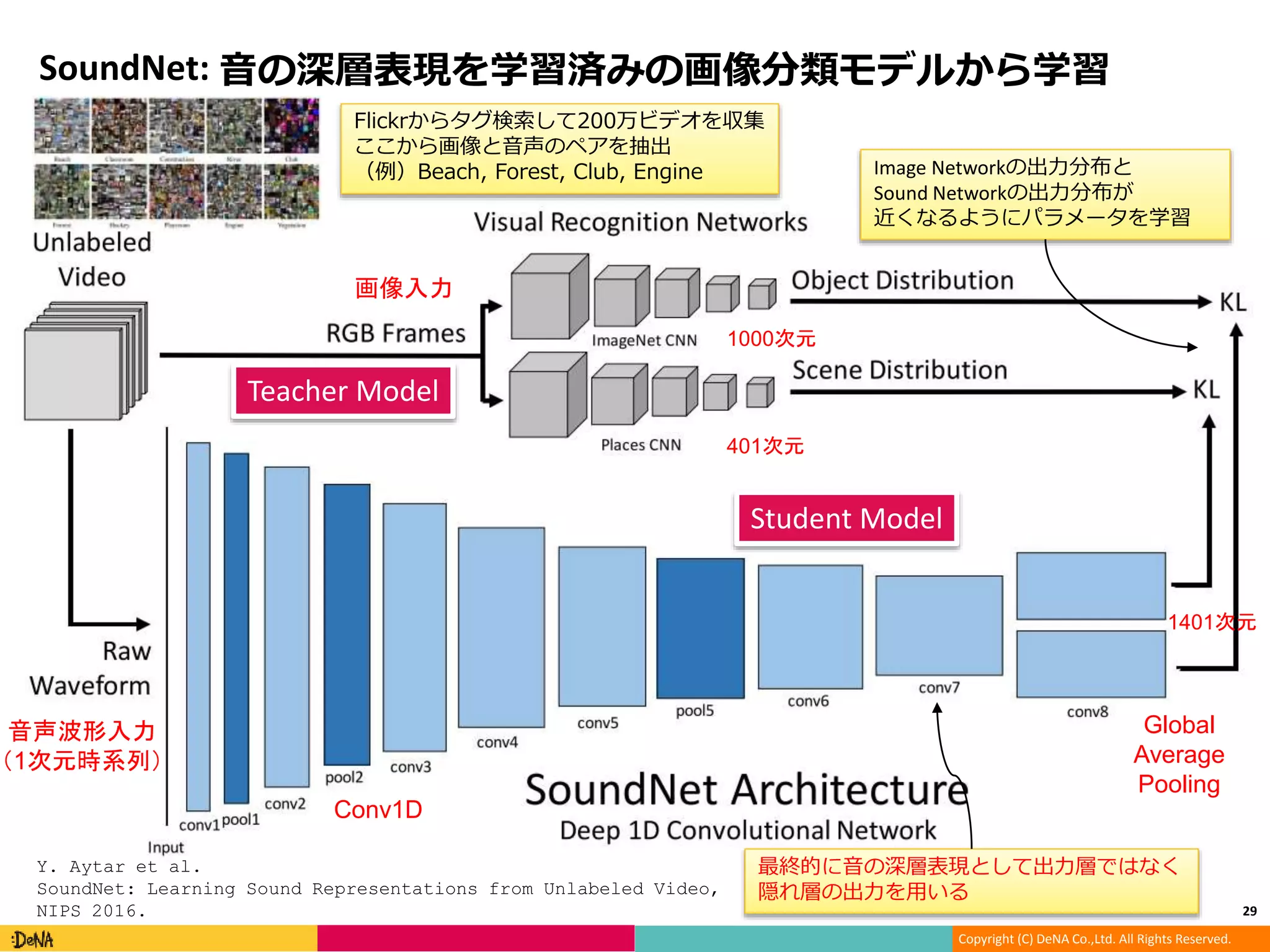
SoundNet: 音の深層表現を学習済みの画像分類モデルから学習
29
音声波形入力
(1次元時系列)
Conv1D
Global
Average
Pooling
1000次元
401次元
1401次元
最終的に音の深層表現として出力層ではなく
隠れ層の出力を用いる
Teacher Model
Student Model
Flickrからタグ検索して200万ビデオを収集
ここから画像と音声のペアを抽出
(例)Beach, Forest, Club, Engine
画像入力
Y. Aytar et al.
SoundNet: Learning Sound Representations from Unlabeled Video,
NIPS 2016.
Image Networkの出力分布と
Sound Networkの出力分布が
近くなるようにパラメータを学習
30.
Copyright (C) DeNACo.,Ltd. All Rights Reserved.
SoundNet の実験結果
30
SoundNetで抽出した音声特徴量を
用いて50カテゴリの環境音認識タスクを
評価したらSOTAの精度を達成できた!
31.
Copyright (C) DeNACo.,Ltd. All Rights Reserved.
まとめ
31
ImageNetではなく
Places365のデータセット(シーンに特化)で学習した
SqueezeNetモデル(Webで軽量に動かせる)を使用
Places http://places2.csail.mit.edu/
freesound.orgからCreative Commons
で公開されている環境音を15000
ほど収集して検索対象に
任意のシーン画像入力
画像の特徴量にもっとも近い
音声特徴量を検索して音声を再生!
画像から環境音を生成する技術まででてきた!
Y. Zhou et al.
Visual to Sound: Generating Natural Sound
for Videos in the Wild,
arXiv:1712.01393
http://bvision11.cs.unc.edu/bigpen/yipin/visual2sound_webpage/visual2sound.html
Copyright (C) DeNACo.,Ltd. All Rights Reserved.
マルチモーダル: 言語 x 画像 x 音声 x 制御
33
TEXTSPEECHAUDIO
MUSIC
IMAGE CONTROL
Speech Recognition
Text-to-Speech
Synthesis
Image
Captioning
(Show and Tell)
Text-to-Image
Synthesis
Imaginary
Soundscape
Talking Head
Visual QA
VIDEO
Visual-to-
sound
TAG
Music Tagging
Image
TaggingSoundNet NL Guided
RL
See and
Listen
See, Hear, and Read































































![[DL輪読会] Efficient Neural Audio Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/b3cd4ef3-190418074139-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会] Efficient Neural Audio Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/b3cd4ef3-190418074324-thumbnail.jpg?width=640&height=640&fit=bounds)














