Download as PDF, PPTX











![import org.apache.commons.math3.stat.regression.OLSMultipleLinearRegression
// Load the instruments and factors
val factorReturns: Array[Array[Double]] = ...
val instrumentReturns: RDD[Array[Double]] = ...
// Fit a model to each instrument
val models: Array[Array[Double]] =
instrumentReturns.map { instrument =>
val regression = new OLSMultipleLinearRegression()
regression.newSampleData(instrument, factorReturns)
regression.estimateRegressionParameters()
}.collect()](https://image.slidesharecdn.com/slidesharerisktalk-150911155504-lva1-app6891/85/Estimating-Financial-Risk-with-Apache-Spark-15-320.jpg)


![import org.apache.commons.math3.stat.correlation.Covariance
// Compute means
val factorMeans: Array[Double] = transpose(factorReturns)
.map(factor => factor.sum / factor.size)
// Compute covariances
val factorCovs: Array[Array[Double]] = new Covariance(factorReturns)
.getCovarianceMatrix().getData()](https://image.slidesharecdn.com/slidesharerisktalk-150911155504-lva1-app6891/85/Estimating-Financial-Risk-with-Apache-Spark-21-320.jpg)


![def trialReturn(factorDist: MultivariateNormalDistribution, models: Seq[Array[Double]]): Double = {
val trialFactorReturns = factorDist.sample()
var totalReturn = 0.0
for (model <- models) {
// Add the returns from the instrument to the total trial return
for (i <- until trialFactorsReturns.length) {
totalReturn += trialFactorReturns(i) * model(i)
}
}
totalReturn
}](https://image.slidesharecdn.com/slidesharerisktalk-150911155504-lva1-app6891/85/Estimating-Financial-Risk-with-Apache-Spark-24-320.jpg)
![// Broadcast the factor return -> instrument return models
val bModels = sc.broadcast(models)
// Generate a seed for each task
val seeds = (baseSeed until baseSeed + parallelism)
val seedRdd = sc.parallelize(seeds, parallelism)
// Create an RDD of trials
val trialReturns: RDD[Double] = seedRdd.flatMap { seed =>
trialReturns(seed, trialsPerTask, bModels.value, factorMeans, factorCovs)
}](https://image.slidesharecdn.com/slidesharerisktalk-150911155504-lva1-app6891/85/Estimating-Financial-Risk-with-Apache-Spark-25-320.jpg)

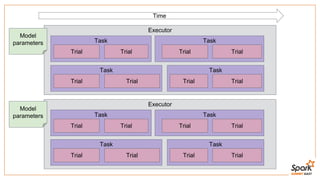

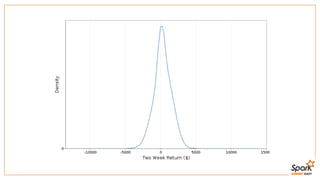
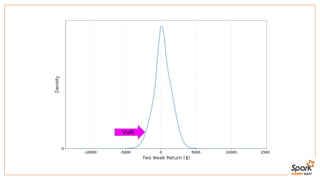








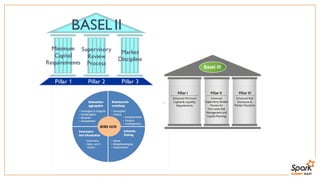
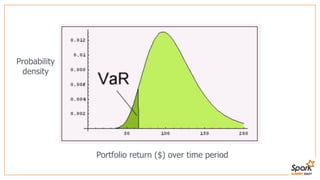
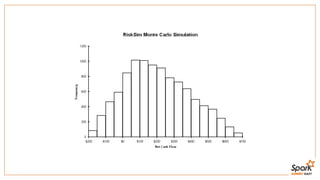
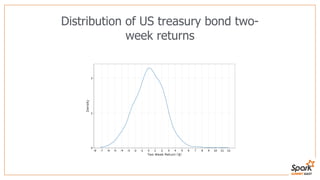
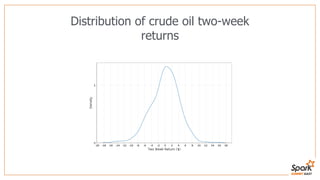
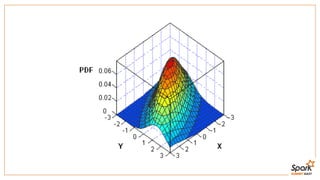
This document discusses estimating financial risk using Apache Spark. It introduces the value-at-risk (VaR) metric, which estimates the maximum potential loss of a portfolio over a given time period and probability. It describes approaches for VaR estimation including variance-covariance, historical simulation, and Monte Carlo simulation. It then explains how to predict instrument returns from market risk factors using linear regression models in Spark. The document outlines sampling factor returns from a multivariate normal distribution and running simulations across a Spark cluster to estimate VaR and expected shortfall. It argues that Spark enables easier, more powerful financial risk analysis by allowing joint processing, simulation matrices to be saved in memory, and calling GPUs for matrix operations.



![Anais Dotis-Georgiou & Faith Chikwekwe [InfluxData] | Top 10 Hurdles for Flux...](https://cdn.slidesharecdn.com/ss_thumbnails/anaisdotis-georgioufaithchikwekweinfluxdatatop10hurdlesforfluxbeginnersinfluxdaysvirtualexperiencena-201106155710-thumbnail.jpg?width=640&height=640&fit=bounds)
![Scott Anderson [InfluxData] | InfluxDB Tasks – Beyond Downsampling | InfluxDa...](https://cdn.slidesharecdn.com/ss_thumbnails/influxdaysnov20201-201105232414-thumbnail.jpg?width=640&height=640&fit=bounds)

















































![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)












