Download to read offline










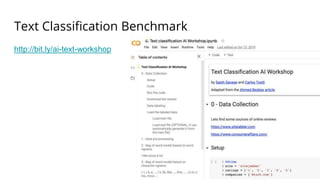

























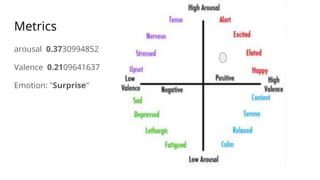
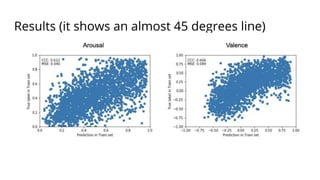

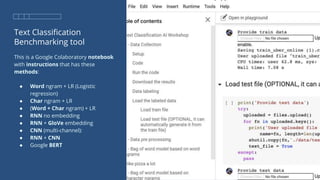
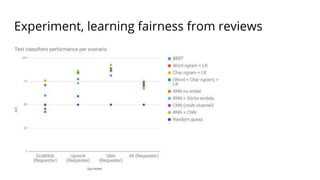


![Code
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier, export_graphviz
import pydotplus
iris = load_iris()
clf = DecisionTreeClassifier().fit(iris.data, iris.target)
dot_data = export_graphviz(clf, out_file=None, filled=True, rounded=True,
feature_names=iris.feature_names,
class_names=['Versicolor','Setosa','Virginica'])
graph = pydotplus.graph_from_dot_data(dot_data)](https://image.slidesharecdn.com/reproducibilityinartificialintelligence-200318161457/85/Reproducibility-in-artificial-intelligence-56-320.jpg)
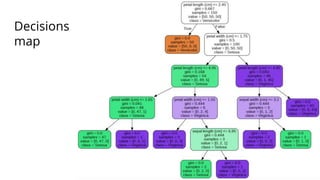
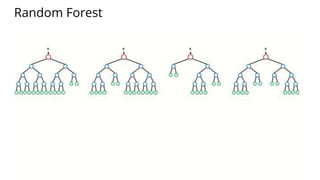

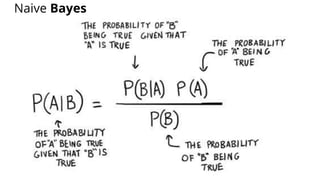

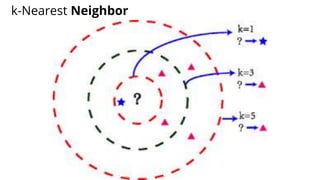

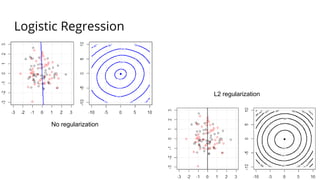
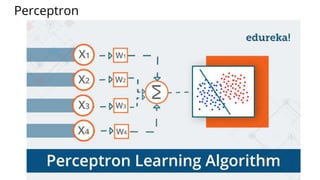

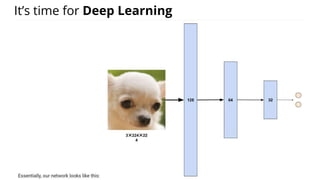


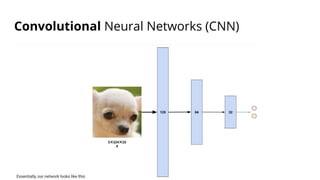





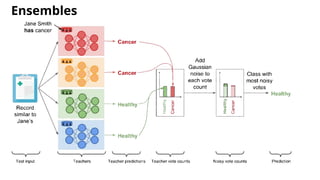
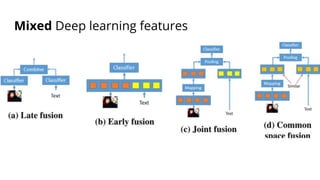
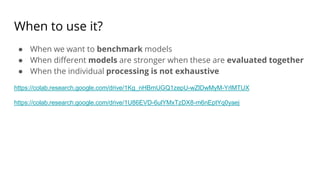


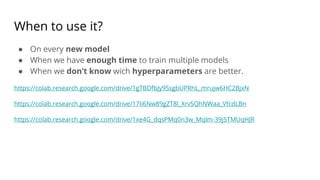
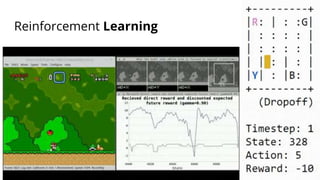

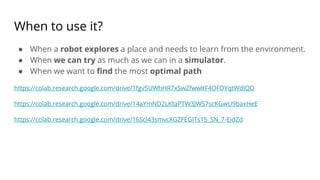

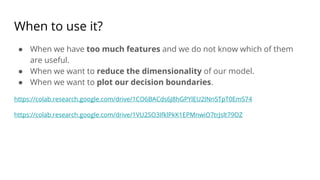

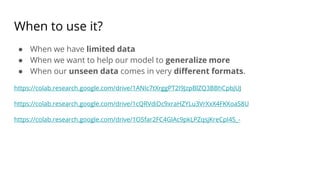
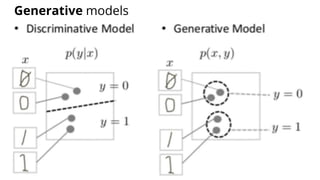
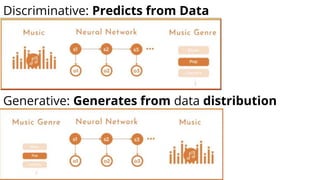


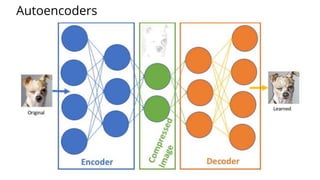
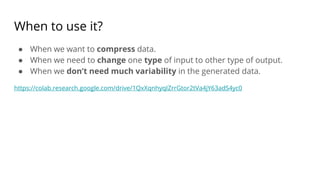
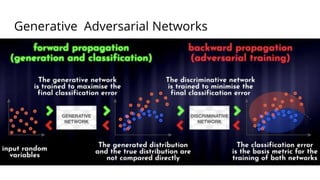
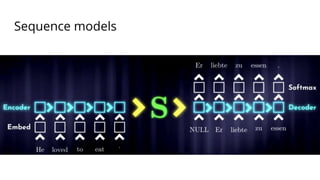

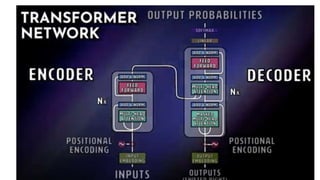





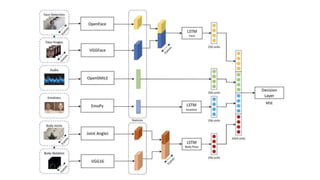
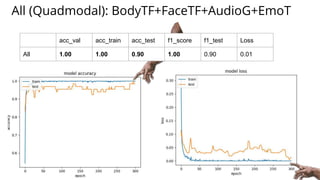
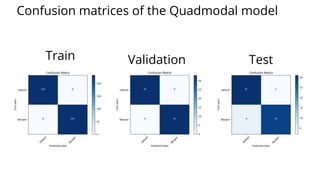
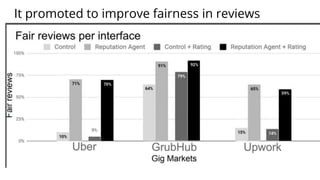
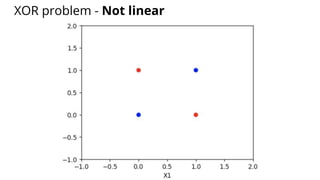
The document discusses various methods for improving reproducibility in artificial intelligence research. It begins by introducing some AI projects the author has worked on. It then discusses causes of non-reproducibility such as lack of data/code access. The document looks at potential solutions like reproducibility frameworks, benchmarking, and standalone methods. It focuses on the author's MultiAffect framework, which standardizes data processing, feature extraction, training, evaluation and reporting. It aims to make research reproducible and accessible. The framework is demonstrated on affect recognition and action recognition tasks, showing it can achieve results comparable to other works.

































![[台灣人工智慧學校] 主題演講 - 張智威總經理 (President of HTC DeepQ)](https://cdn.slidesharecdn.com/ss_thumbnails/aischoolhsinzhukeynoteedwardchang-180725074840-thumbnail.jpg?width=640&height=640&fit=bounds)








![ASEP midsem review_ asep project[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/asepmidsemreviewasep1-250430103532-0aa8da3f-thumbnail.jpg?width=640&height=640&fit=bounds)












































