Download to read offline




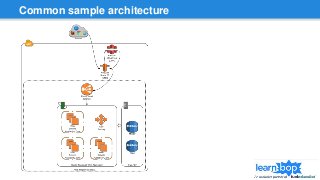




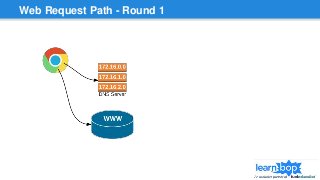
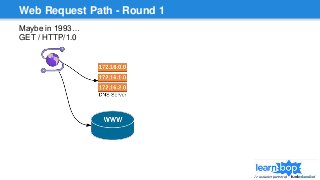
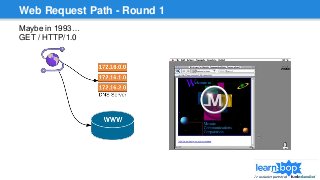
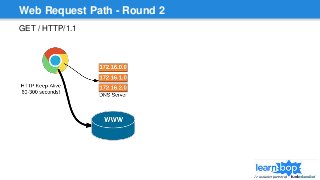


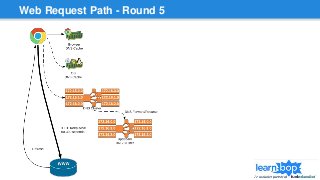
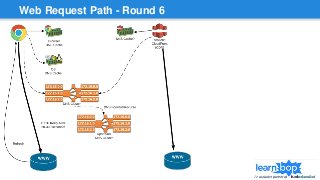












This document discusses blue/green deployments for LearnBop, an online tutoring platform. It describes setting up two environments with separate load balancers to allow deploying new code without disrupting existing users. The key steps are: 1) attaching the production load balancer to the new environment, 2) detaching it from the old environment, 3) attaching the staging load balancer to the old environment, and 4) detaching it from the new environment. This allows rolling back quickly by reversing the process. CNAME record swaps are avoided to prevent users remaining on the old version indefinitely.





































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)









