
Download to read offline









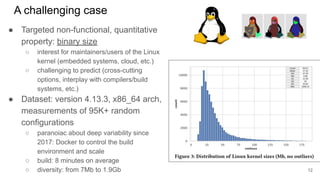



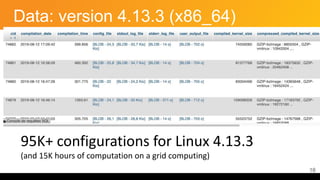
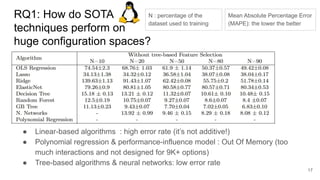


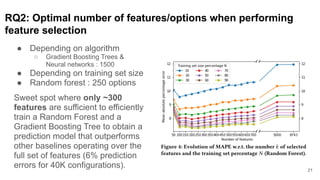





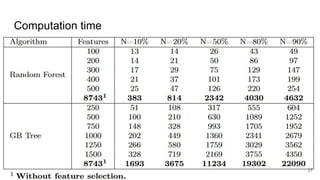

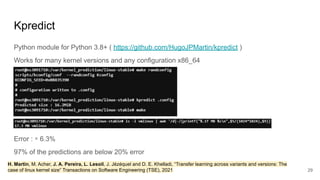




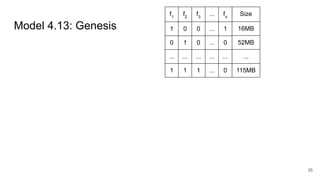

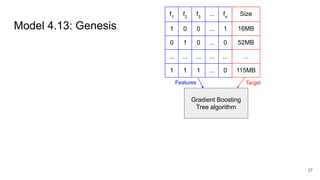
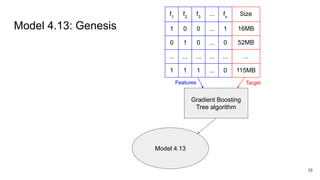
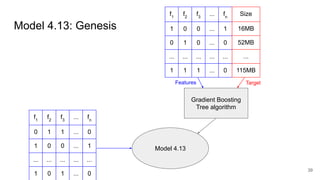
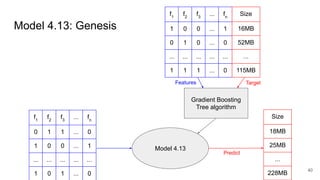
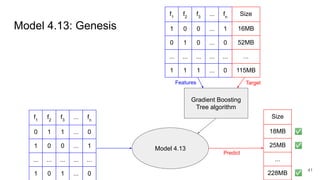

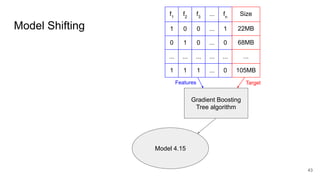
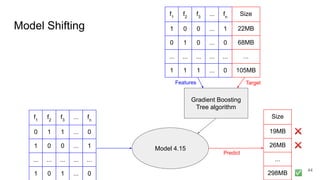
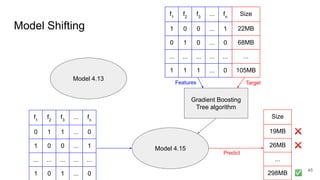
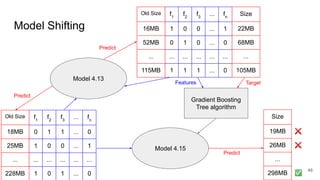
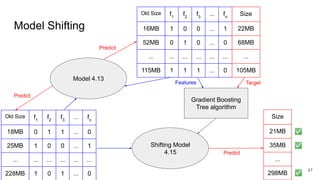
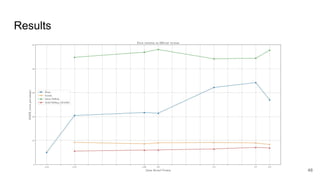
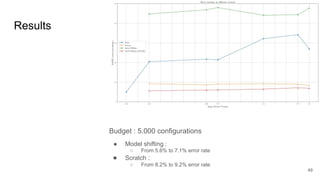
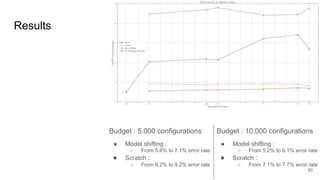
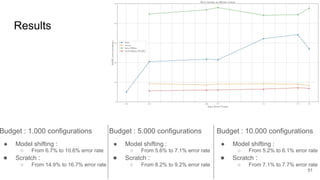





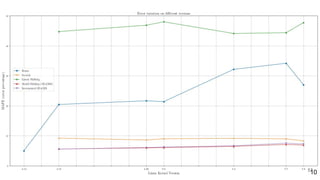


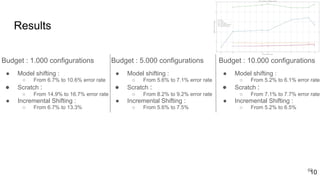
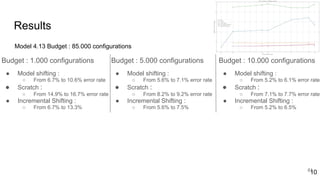
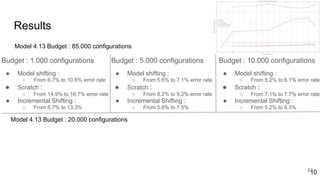
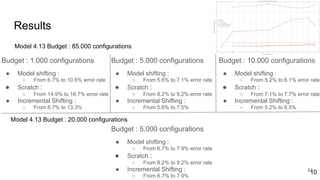
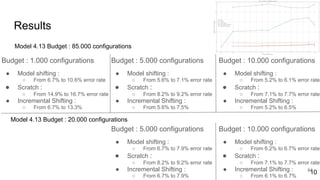
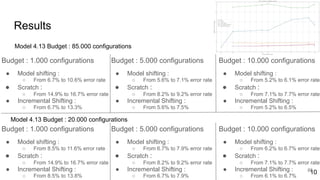

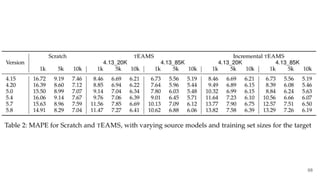
This document discusses feature subset selection for predicting properties of Linux kernel configurations, highlighting that out of over 9,000 options, only about 300 are essential for effective prediction. It presents findings that traditional state-of-the-art methods struggle with high-dimensional spaces, while tree-based algorithms yield low error rates and improved training times when using a reduced feature set. Furthermore, the results align with domain knowledge, revealing that many influential kernel options are poorly documented.















































