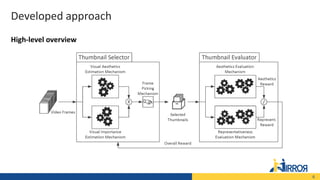
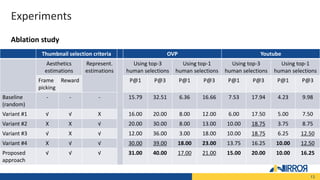
The document presents a novel approach combining adversarial and reinforcement learning for selecting video thumbnails, aimed at efficiently identifying representative and aesthetically pleasing frames from vast video content. It outlines the developed methodology, experimental evaluations on benchmark datasets, and illustrates improved performance compared to existing techniques. Key highlights include the integration of aesthetic quality assessments and representativeness measures in the thumbnail selection process.