Download to read offline






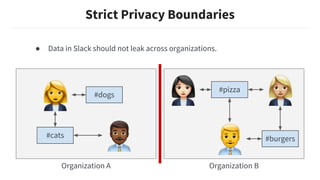

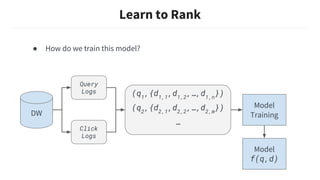



![Attribute Parameterization
“MLConf”
Query Document
Attributes
user_id:U123
terms:[“MLConf”]
user_id:U456
channel_id:C789
terms:[“Hey”,…]](https://image.slidesharecdn.com/renaudbourassa-buildingmachinelearningmodelswithstrictprivacyboundaries-190329044636/85/Renaud-bourassa-building-machine-learning-models-with-strict-privacy-boundaries-20-320.jpg)
![One Hot Encoding
Attribute Parameterization
user_id:U123
terms:[“MLConf”]
user_id:U456
channel_id:C789
terms:[“Hey”,…]
Model f(q,d)](https://image.slidesharecdn.com/renaudbourassa-buildingmachinelearningmodelswithstrictprivacyboundaries-190329044636/85/Renaud-bourassa-building-machine-learning-models-with-strict-privacy-boundaries-21-320.jpg)
![Attribute Parameterization
user_id:U123
terms:[“MLConf”]
user_id:U456
channel_id:C789
terms:[“Hey”,…]
Model f(q,d)
g(dterms
)
Parameterization
Examples:
● num_terms(dterms
)
● num_emojis(dterms
)](https://image.slidesharecdn.com/renaudbourassa-buildingmachinelearningmodelswithstrictprivacyboundaries-190329044636/85/Renaud-bourassa-building-machine-learning-models-with-strict-privacy-boundaries-22-320.jpg)
![Attribute Parameterization
user_id:U123
terms:[“MLConf”]
user_id:U456
channel_id:C789
terms:[“Hey”,…]
Model f(q,d)
ctr(dchannel_id
)
Parameterization
Definition:
ctr(dx
) = clicks(dx
) / impressions(dx
)](https://image.slidesharecdn.com/renaudbourassa-buildingmachinelearningmodelswithstrictprivacyboundaries-190329044636/85/Renaud-bourassa-building-machine-learning-models-with-strict-privacy-boundaries-23-320.jpg)
![Definition:
ctr(qx
,dy
) = clicks(qx
AND dy
) / impressions(qx
AND dy
)
Attribute Parameterization
user_id:U123
terms:[“MLConf”]
user_id:U456
channel_id:C789
terms:[“Hey”,…]
Model f(q,d)ctr(quser_id
,dchannel_id
)
Parameterization
Examples:
● ctr(quser_id
,duser_id
)
● ctr(quser_id
,dreactor_id
)
● ctr(qteam_id
,dterm
)](https://image.slidesharecdn.com/renaudbourassa-buildingmachinelearningmodelswithstrictprivacyboundaries-190329044636/85/Renaud-bourassa-building-machine-learning-models-with-strict-privacy-boundaries-24-320.jpg)
![Attribute Parameterization
user_id:U123
terms:[“MLConf”]
user_id:U456
channel_id:C789
terms:[“Hey”,…]
Model f(q,d)ctr(qterms
,dterms
)
Could leak private
data between
organizations!](https://image.slidesharecdn.com/renaudbourassa-buildingmachinelearningmodelswithstrictprivacyboundaries-190329044636/85/Renaud-bourassa-building-machine-learning-models-with-strict-privacy-boundaries-25-320.jpg)
![Attribute Parameterization
user_id:U123
terms:[“MLConf”]
user_id:U456
channel_id:C789
terms:[“Hey”,…]
Model f(q,d)
Safe!
ctr(quser_id
,qterms
,dterms
)](https://image.slidesharecdn.com/renaudbourassa-buildingmachinelearningmodelswithstrictprivacyboundaries-190329044636/85/Renaud-bourassa-building-machine-learning-models-with-strict-privacy-boundaries-26-320.jpg)
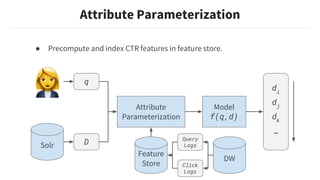



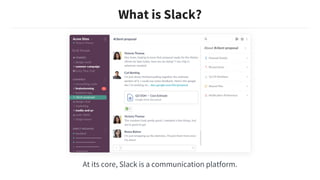
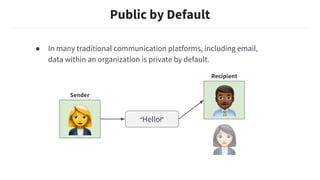
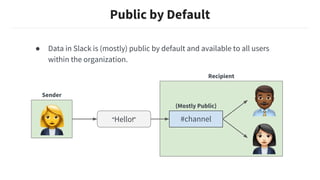
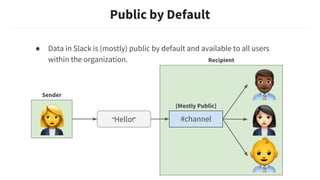
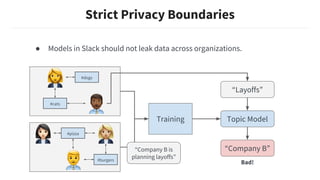
This document discusses building machine learning models at Slack while respecting strict privacy boundaries between organizations. It describes how Slack data is public by default within organizations but private across organizations. It proposes using attribute parameterization, a technique that factors out private user and organization information into aggregated statistics before training global models. This allows building a single model for all organizations while preventing data from leaking between them. The technique transforms attributes like user IDs, terms, and channels into aggregated metrics like term frequencies and click-through rates to learn from interactions in a privacy-preserving way.



































































