



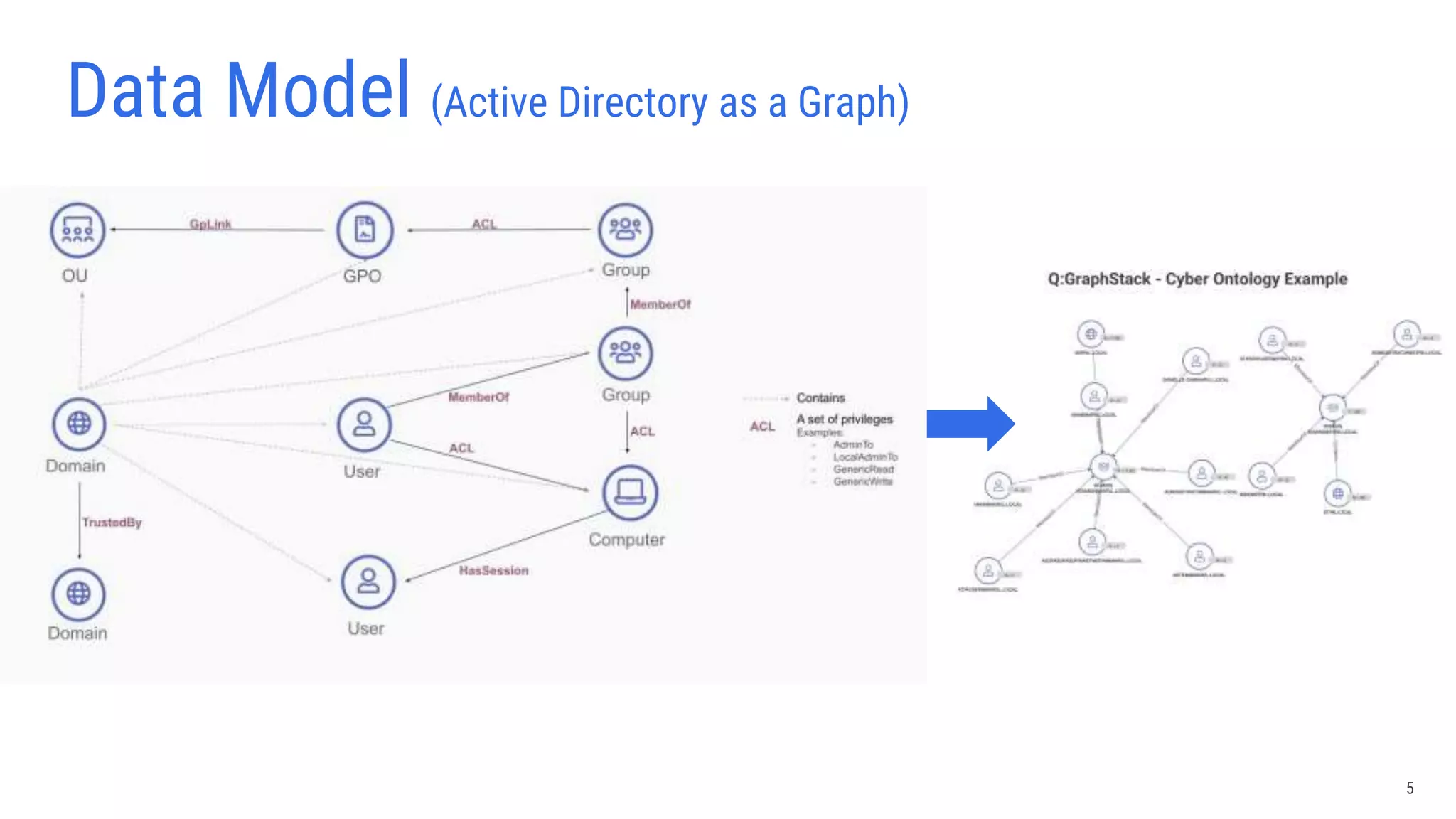

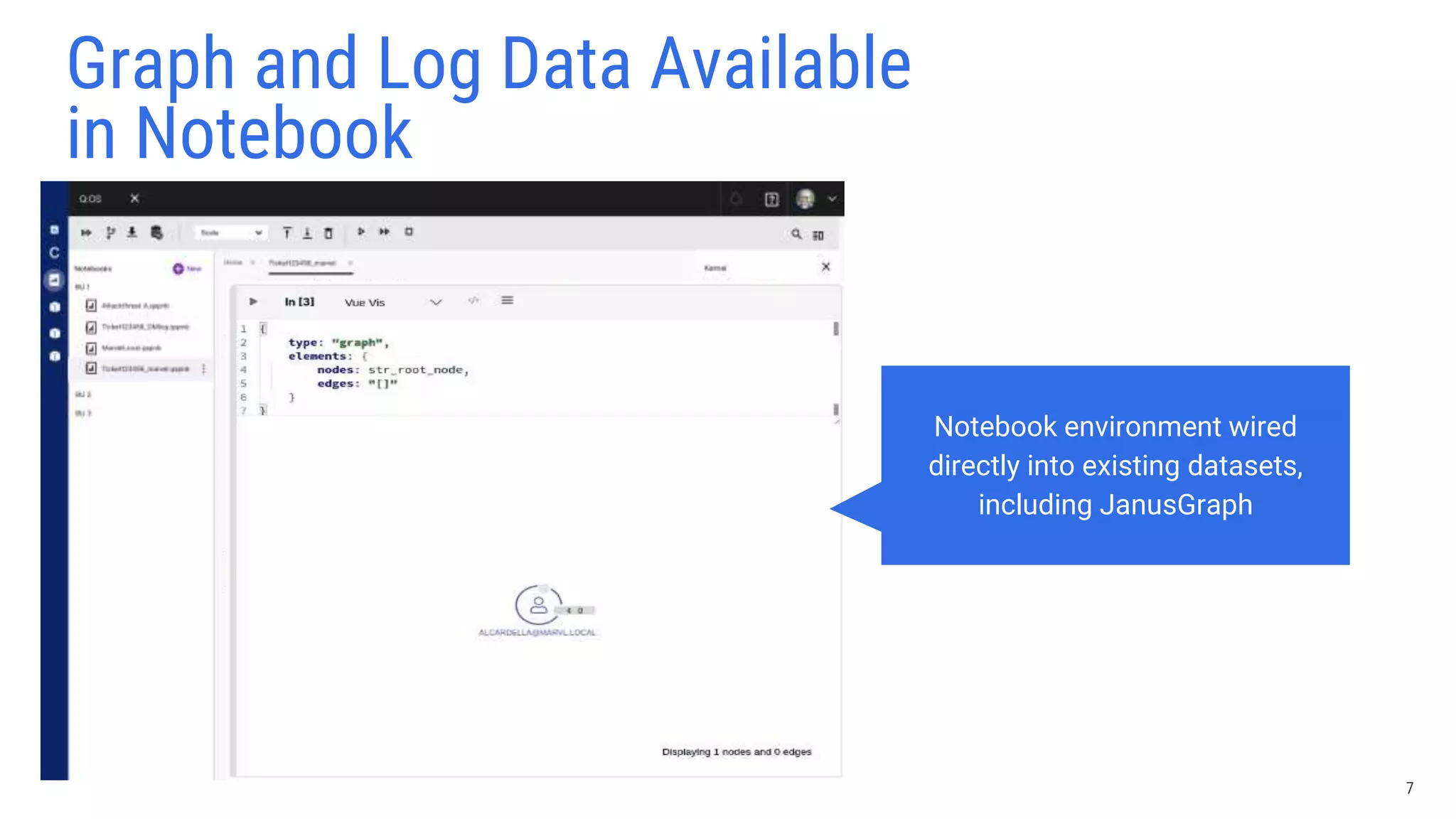

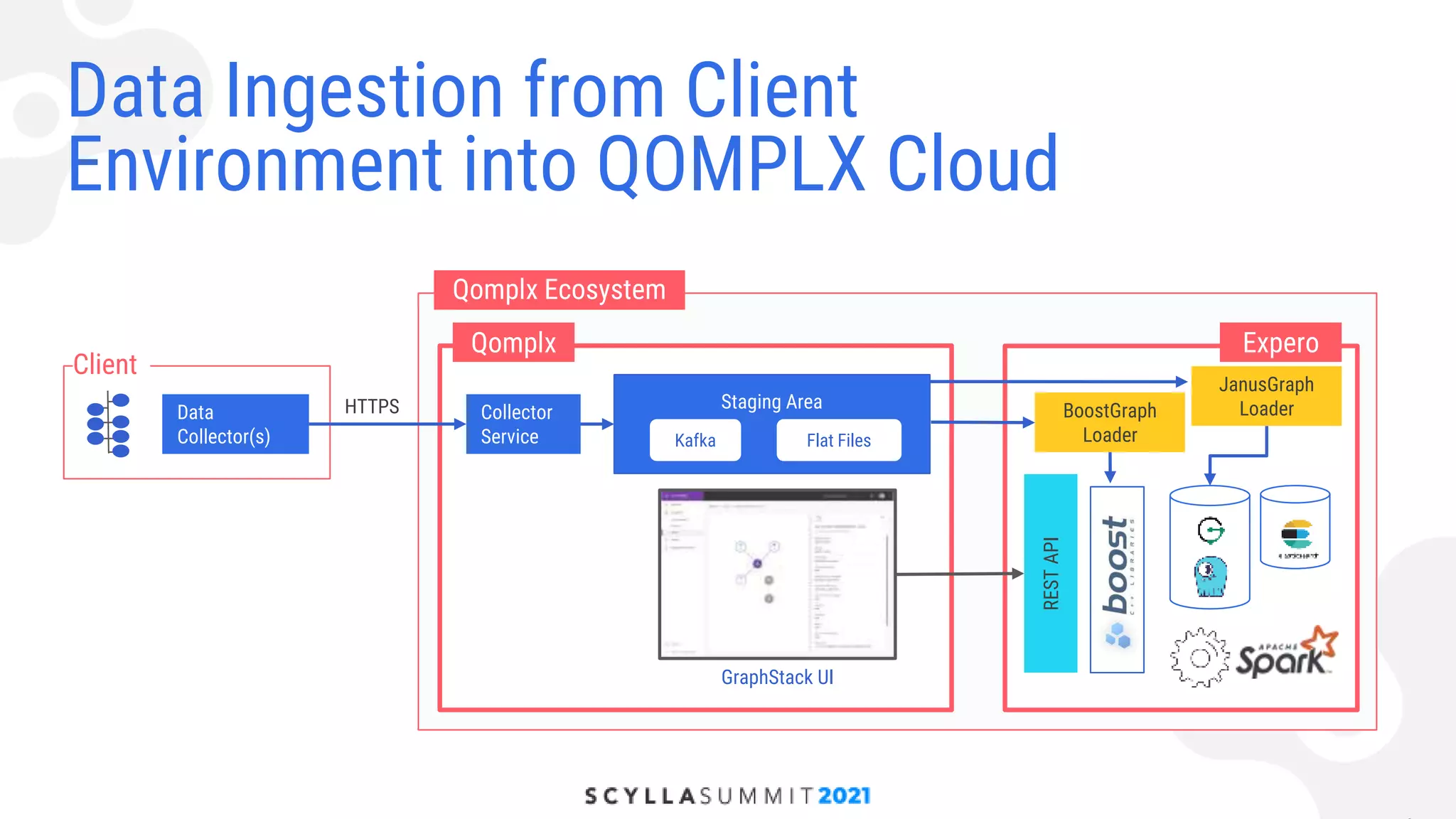




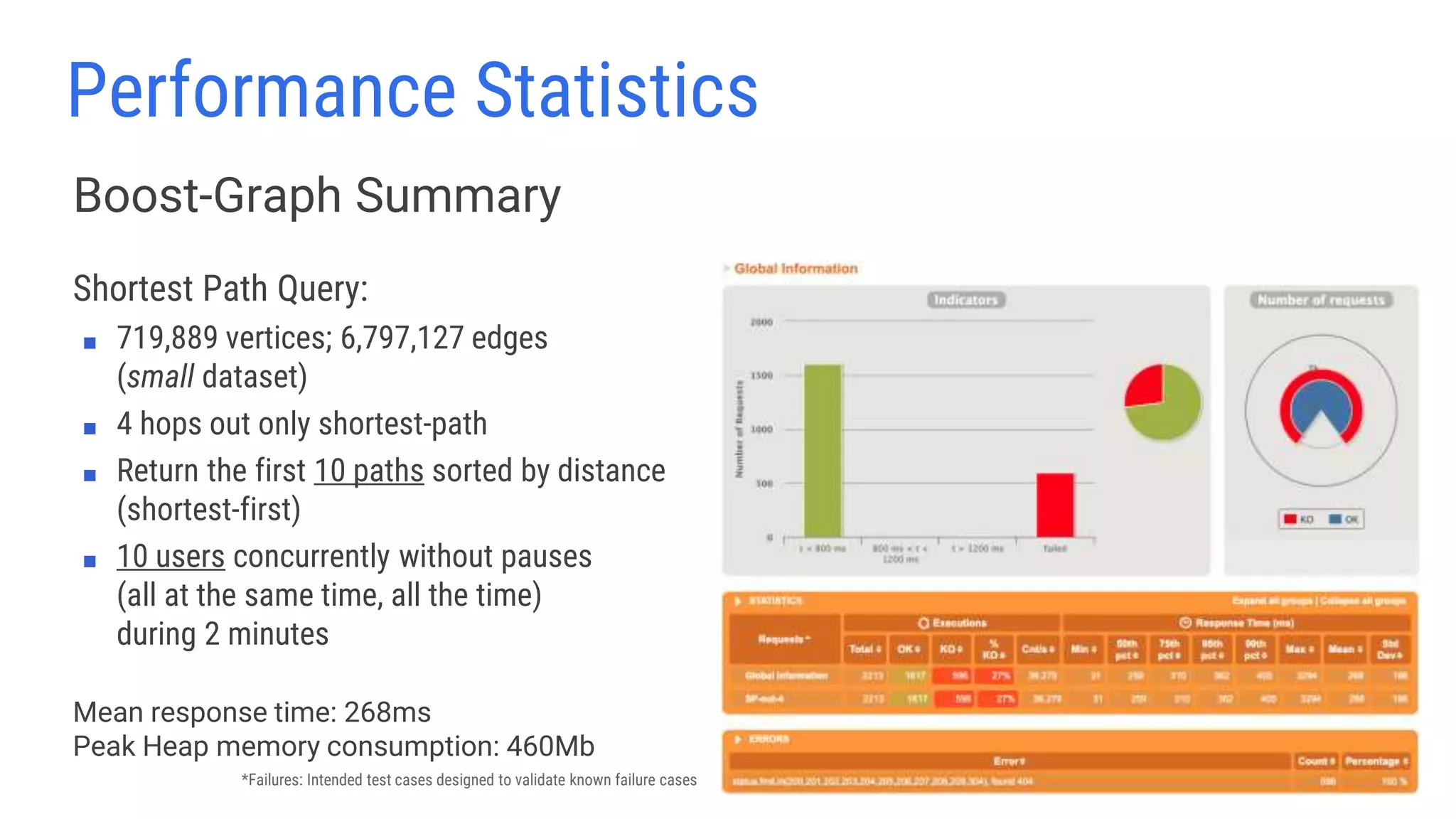


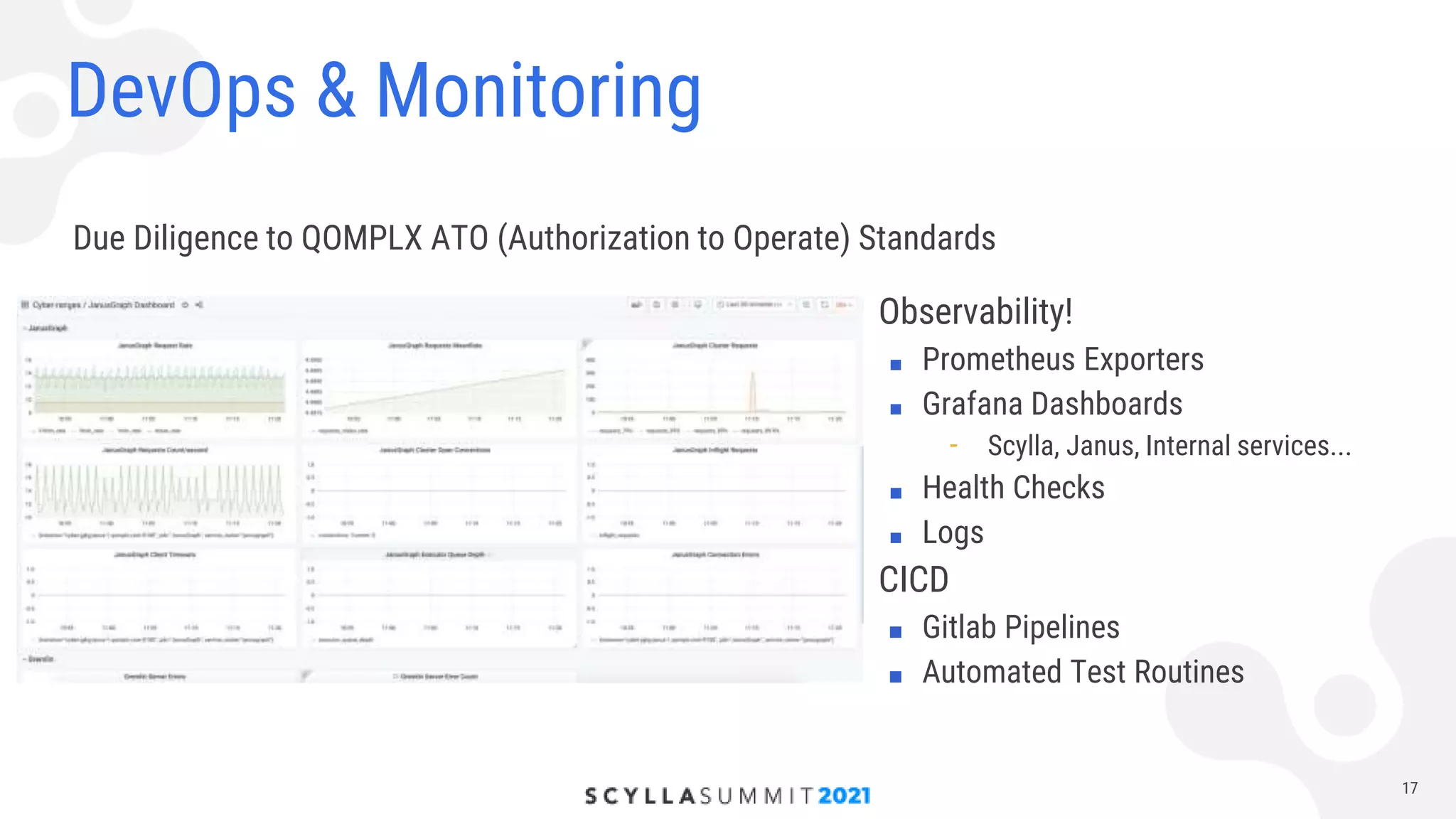


The document discusses lessons learned from using Scylla with JanusGraph for cybersecurity applications by QOMPLX, Inc. It highlights the importance of real-time data analytics and the challenges faced with batch versus streaming data processes. The findings emphasize dynamic graph creation and the need for effective monitoring and observability in operational environments.






































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)
















