基礎理論の例題
2021/8/31
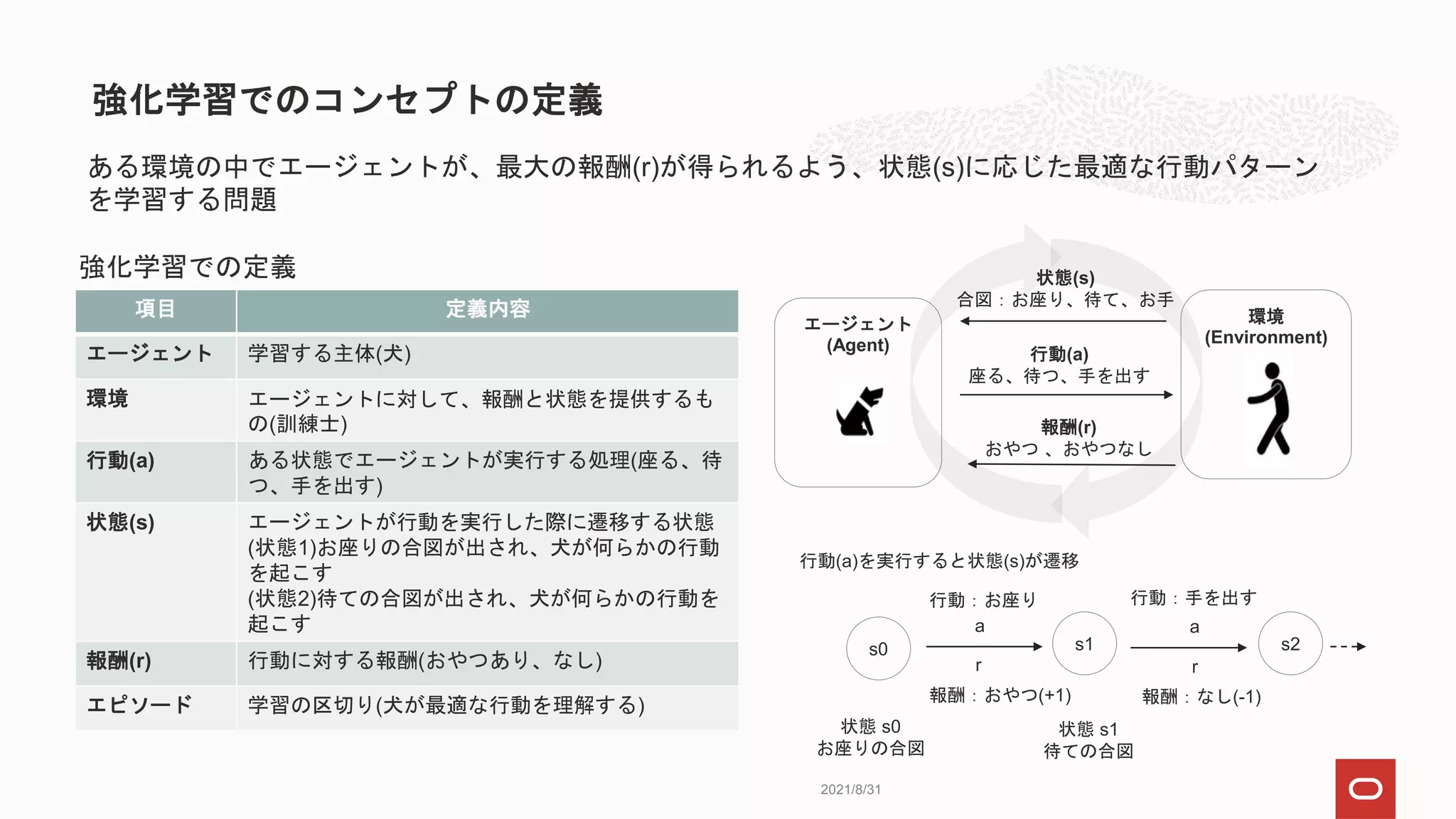
項目 定義内容
環境 縦横5x5マスのグリッド
エージェントロボット
行動(a) 上、下、左、右いずれかへの移動
状態(s) ロボットが座標(x, y)にいる状態
報酬(r) 上、右は +10、下、左は -10
エピソード ロボットがゴールに到達するまで
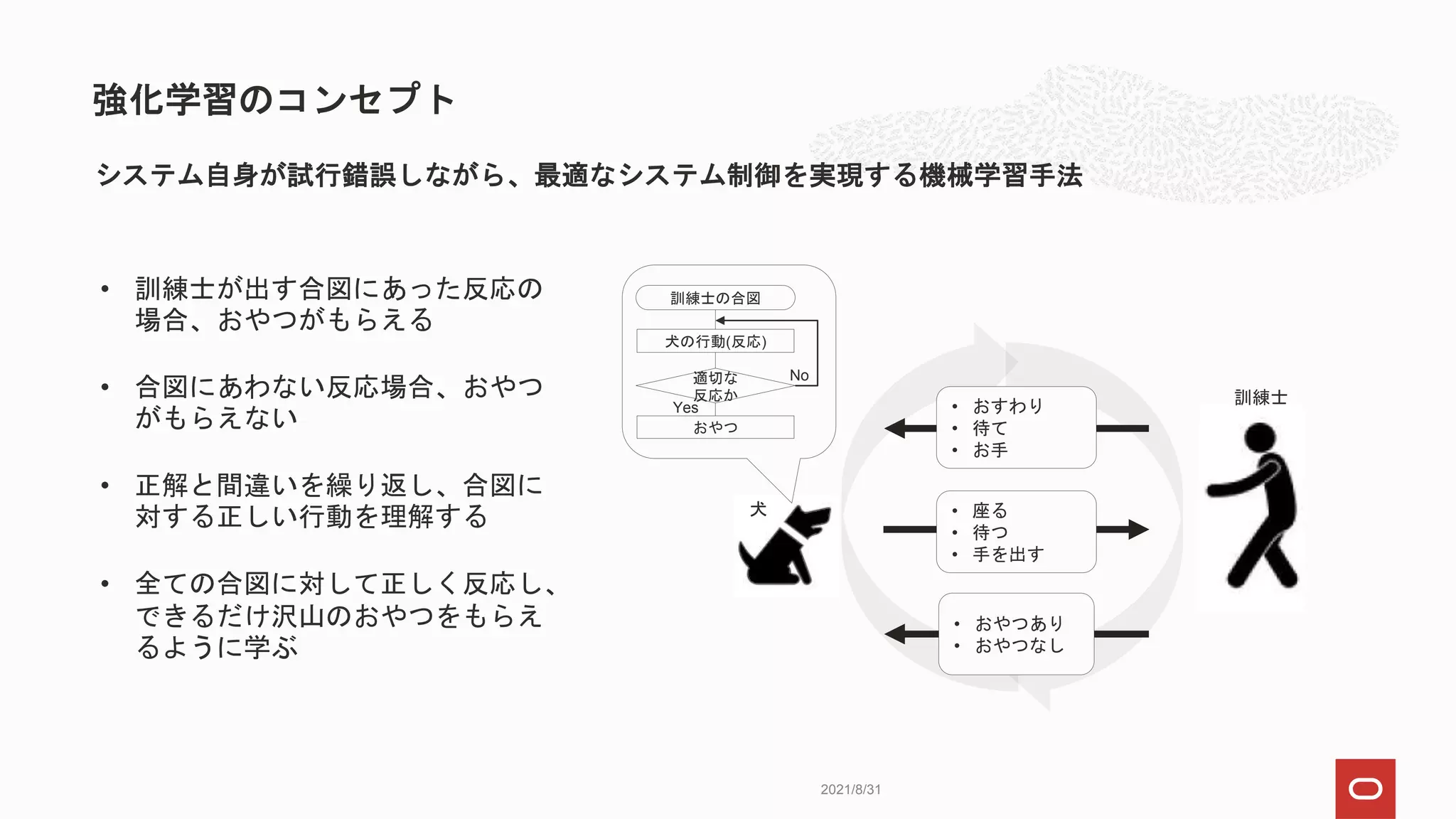
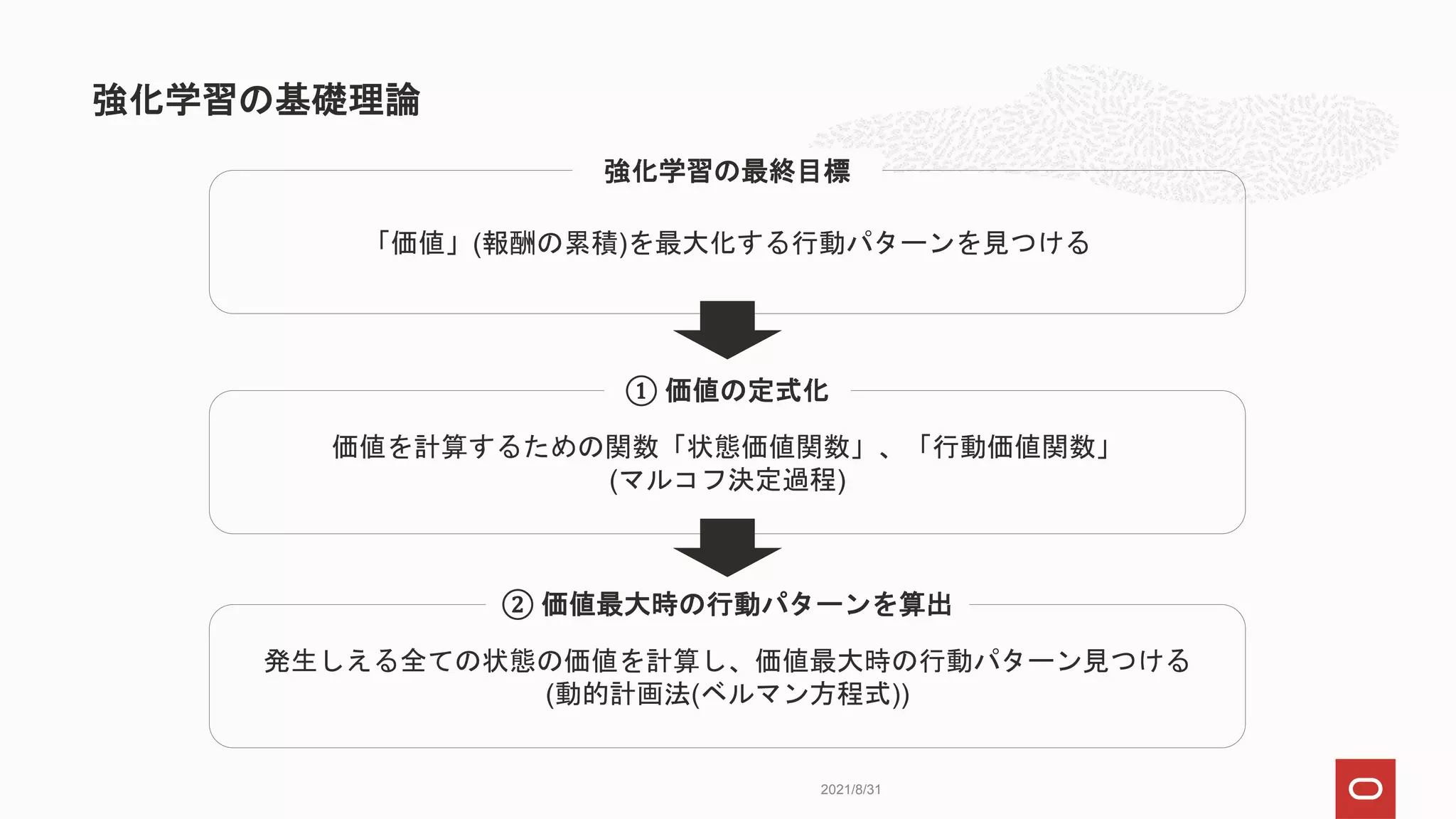
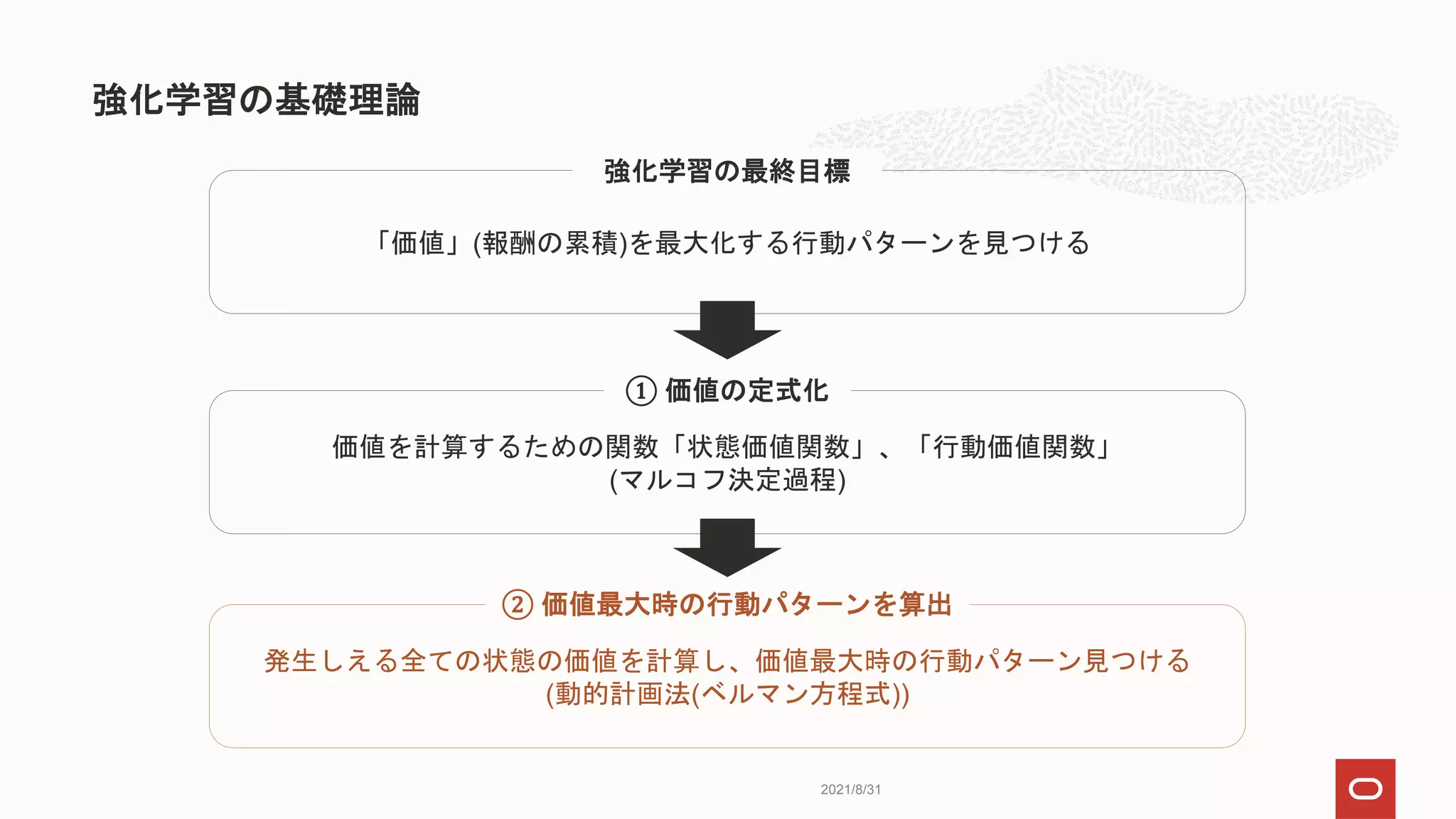
強化学習の定義に当てはめると…
縦横5x5マスのグリッドで、スタート地点からゴール地点に
効率よく移動できるようロボットを学習させる
問題
a
r
報酬 +10
S
(1,1)
S
(2,1)
S
(x,y)
a
r
報酬 +10
s
(5,5)
右に移動 上に移動
a
Goalに移動
報酬 +10
r
価値(報酬の累積総和)
状態遷移の例
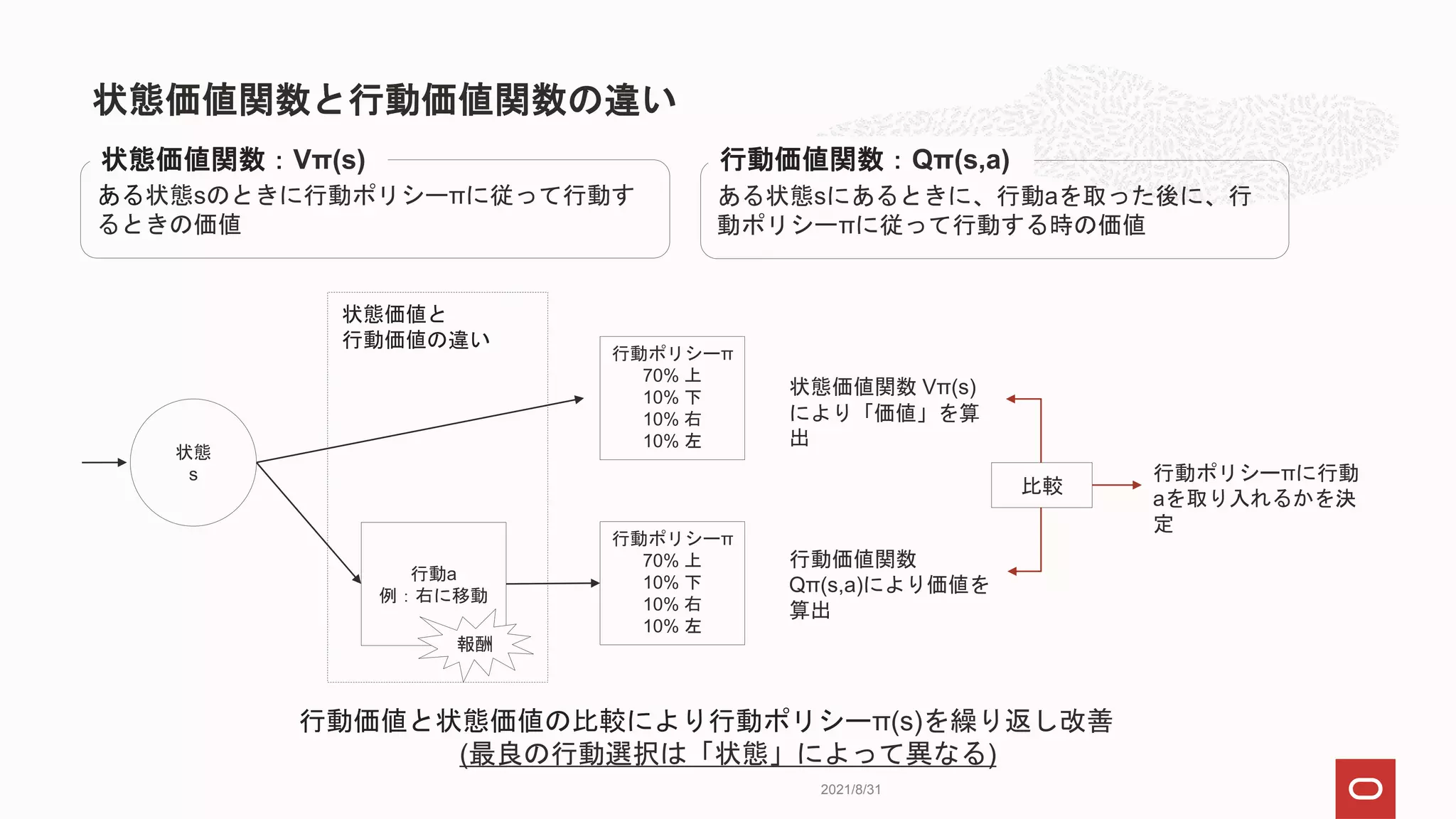
行動価値関数
2021/8/31
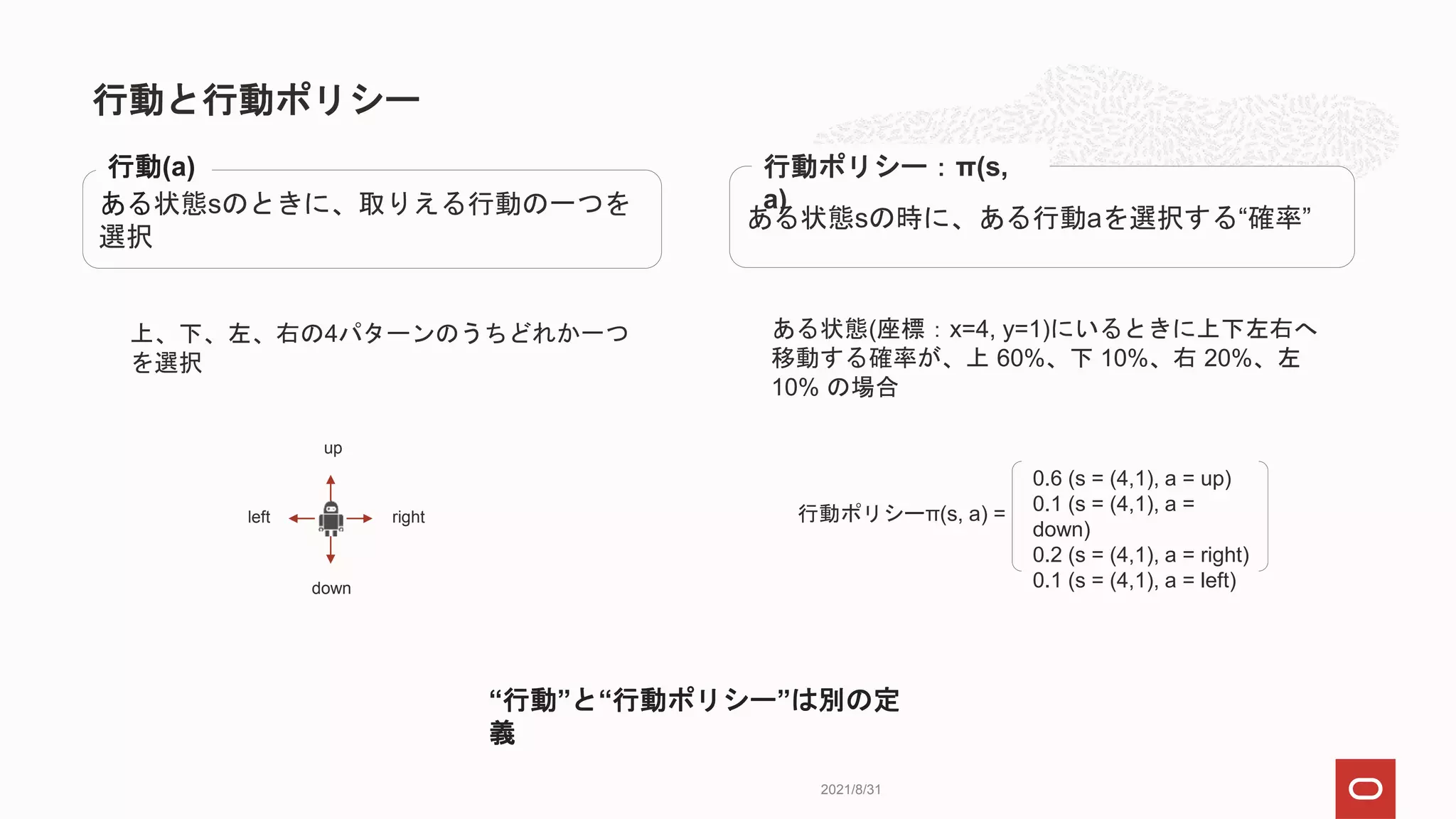
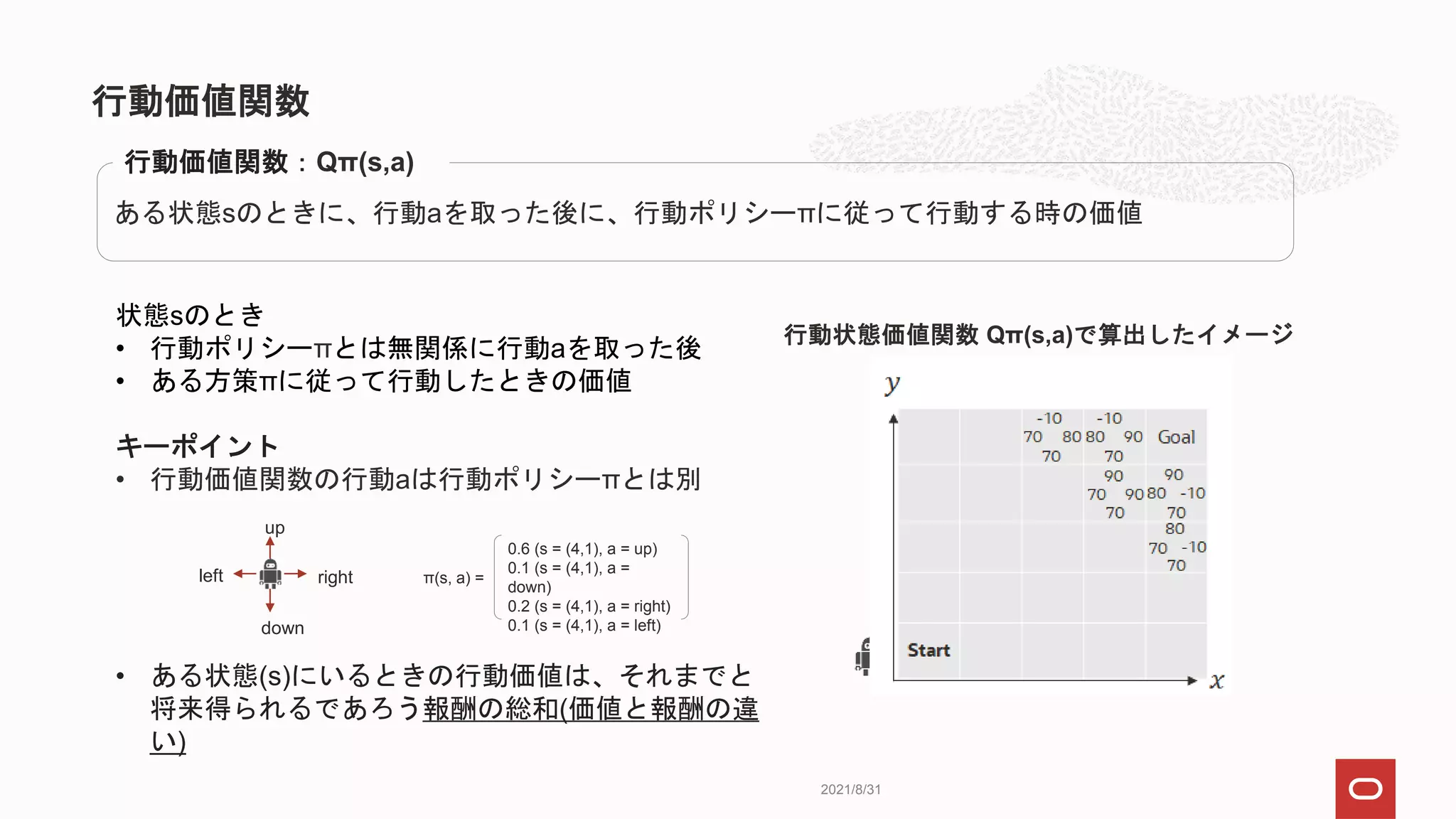
状態sのとき
• 行動ポリシーπとは無関係に行動aを取った後
• ある方策πに従って行動したときの価値
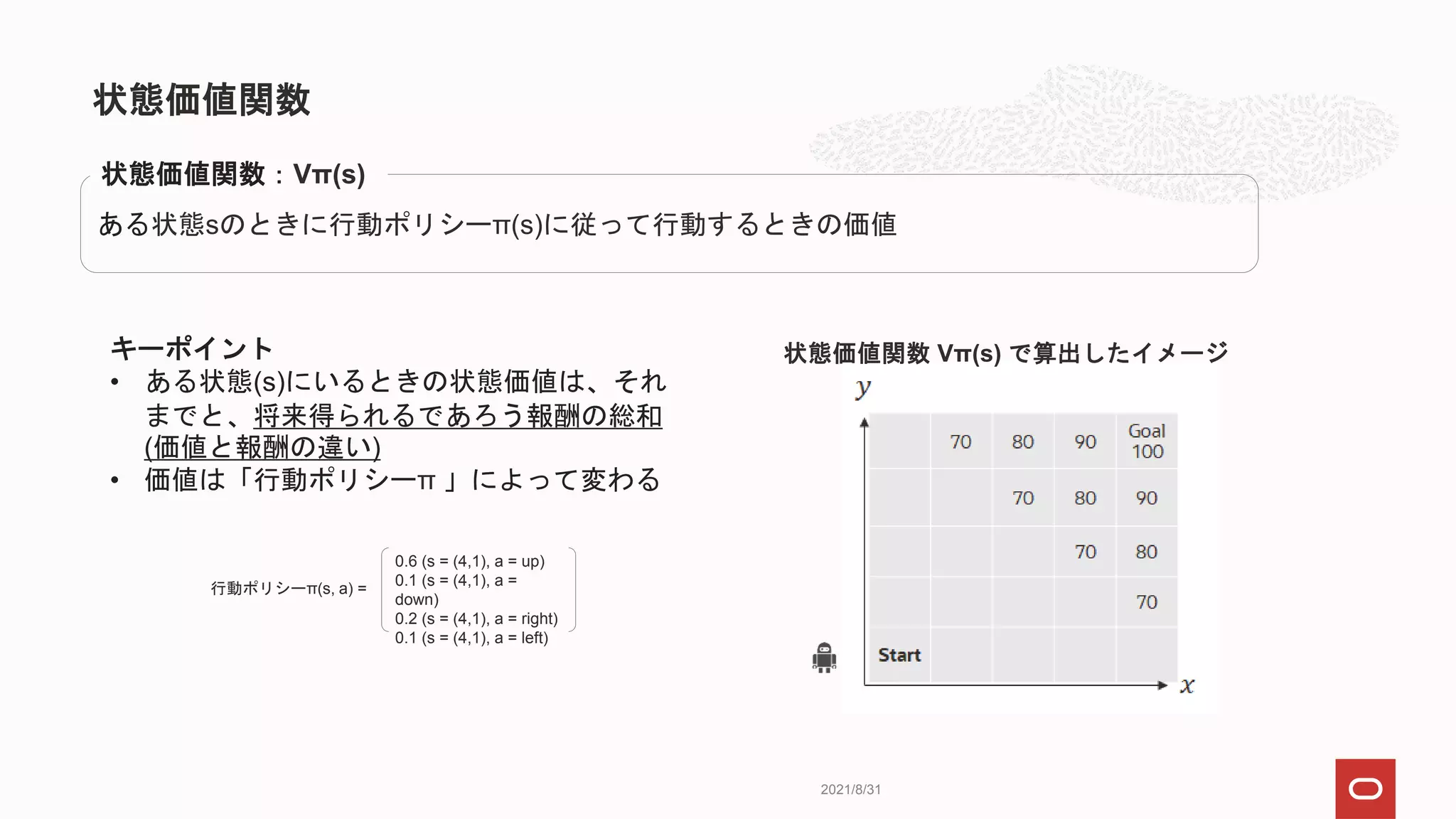
キーポイント
•行動価値関数の行動aは行動ポリシーπとは別
• ある状態(s)にいるときの行動価値は、それまでと
将来得られるであろう報酬の総和(価値と報酬の違
い)
ある状態sのときに、行動aを取った後に、行動ポリシーπに従って行動する時の価値
行動価値関数:Qπ(s,a)
行動状態価値関数 Qπ(s,a)で算出したイメージ
up
down
right
left π(s, a) =
0.6 (s = (4,1), a = up)
0.1 (s = (4,1), a =
down)
0.2 (s = (4,1), a = right)
0.1 (s = (4,1), a = left)
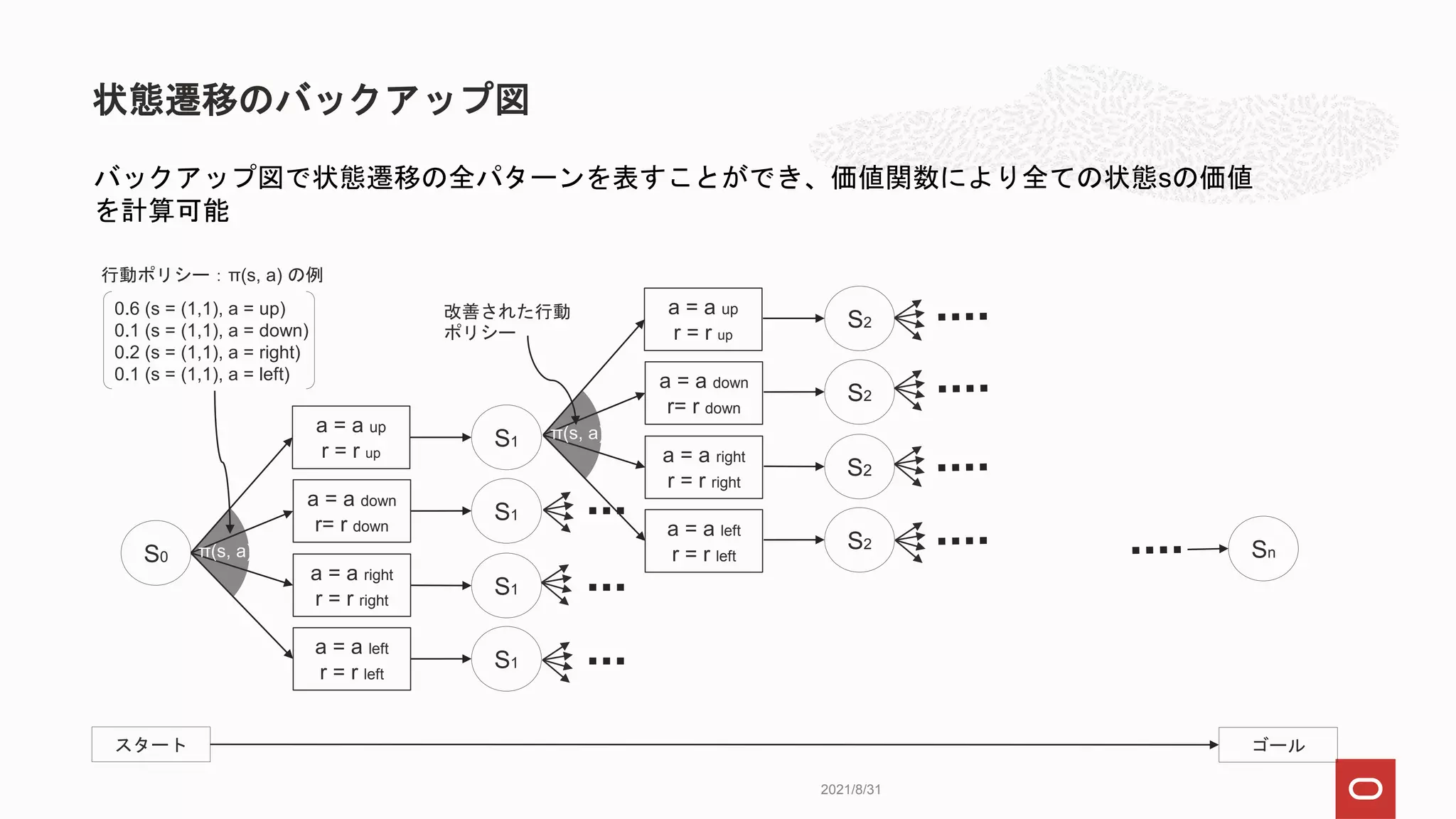
状態遷移のバックアップ図
2021/8/31
S1
S1
S1
S1
バックアップ図で状態遷移の全パターンを表すことができ、価値関数により全ての状態sの価値
を計算可能
行動ポリシー:π(s, a) の例
0.6(s = (1,1), a = up)
0.1 (s = (1,1), a = down)
0.2 (s = (1,1), a = right)
0.1 (s = (1,1), a = left)
S0
a = a up
r = r up
a = a down
r= r down
a = a right
r = r right
a = a left
r = r left
π(s, a)
a = a up
r = r up
a = a down
r= r down
a = a right
r = r right
a = a left
r = r left
π(s, a)
S2
S2
S2
S2
Sn
スタート ゴール
改善された行動
ポリシー
16.
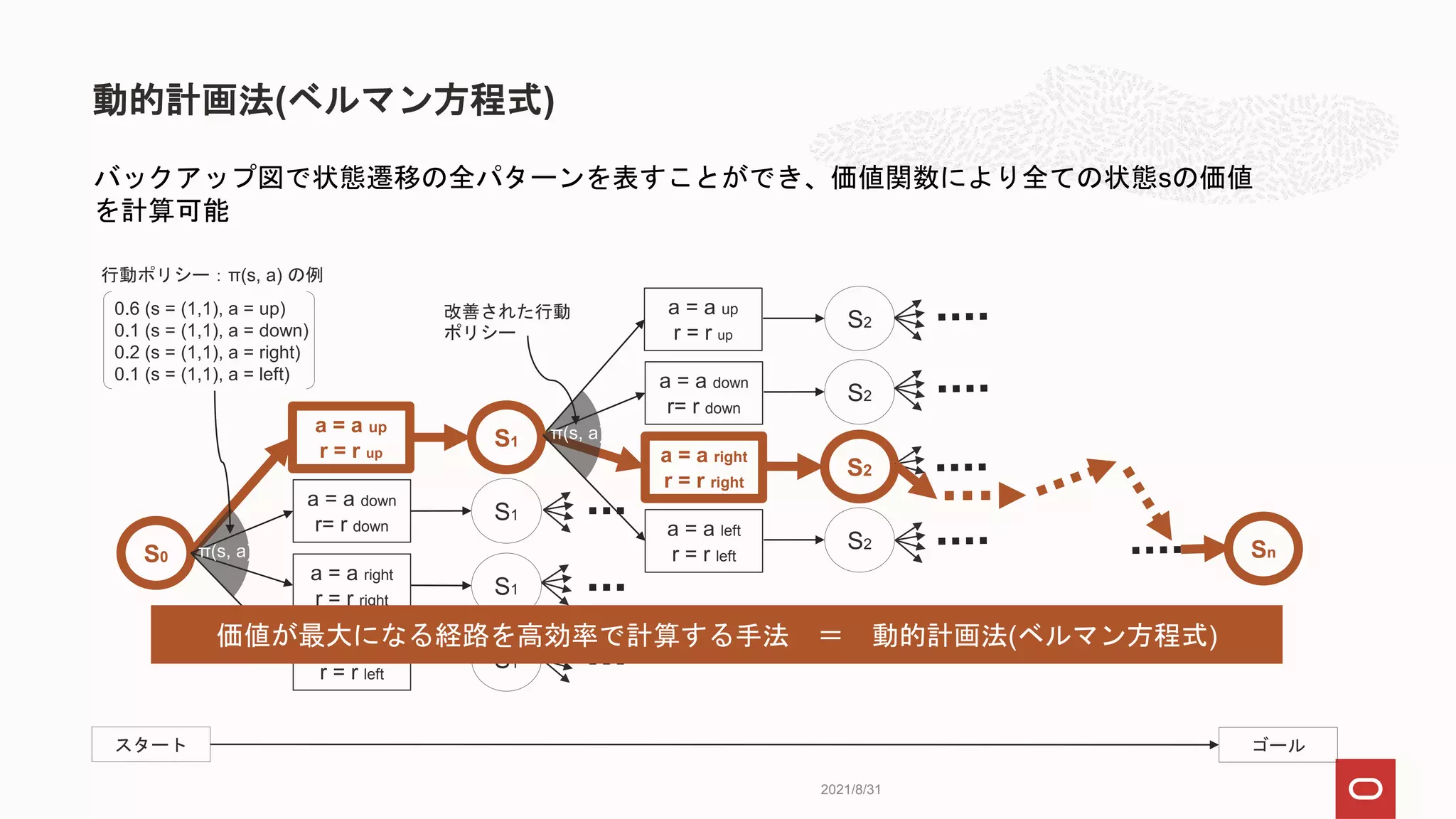
動的計画法(ベルマン方程式)
2021/8/31
S1
S1
S1
S1
バックアップ図で状態遷移の全パターンを表すことができ、価値関数により全ての状態sの価値
を計算可能
行動ポリシー:π(s, a) の例
0.6(s = (1,1), a = up)
0.1 (s = (1,1), a = down)
0.2 (s = (1,1), a = right)
0.1 (s = (1,1), a = left)
S0
a = a up
r = r up
a = a down
r= r down
a = a right
r = r right
a = a left
r = r left
π(s, a)
a = a up
r = r up
a = a down
r= r down
a = a right
r = r right
a = a left
r = r left
π(s, a)
S2
S2
S2
S2
Sn
スタート ゴール
価値が最大になる経路を高効率で計算する手法 = 動的計画法(ベルマン方程式)
改善された行動
ポリシー














![[DL輪読会]Inverse Constrained Reinforcement Learning](https://cdn.slidesharecdn.com/ss_thumbnails/20210709icrl-210709021811-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Deep Reinforcement Learning that Matters](https://cdn.slidesharecdn.com/ss_thumbnails/deeprlthatmatters-171212050658-thumbnail.jpg?width=640&height=640&fit=bounds)











![[Oracle Code Night] Reinforcement Learning Demo Code](https://cdn.slidesharecdn.com/ss_thumbnails/20210831orajam7crypto-210921030945-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Code night 20200531]machine learning for begginer generation of virtual rea...](https://cdn.slidesharecdn.com/ss_thumbnails/codenight20200531machinelearningforbegginergenerationofvirtualrealitybynext-generationaigan-210604024223-thumbnail.jpg?width=640&height=640&fit=bounds)
![20210226[oracle code night] 機械学習入門:ディープラーニングの基礎から転移学習まで](https://cdn.slidesharecdn.com/ss_thumbnails/20210226oraclecodenightmlforbeginer-210226132432-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Code night] natural language proccessing and machine learning](https://cdn.slidesharecdn.com/ss_thumbnails/codenightnatuallanguageproccessingandmachinelearning-201202045342-thumbnail.jpg?width=640&height=640&fit=bounds)


![[Oracle big data jam session #1] Apache Spark ことはじめ](https://cdn.slidesharecdn.com/ss_thumbnails/oraclebigdatajamsession1apachesparkquickstart-191127094941-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Vladimir Jelic - The AI-Driven Security Shift From Reactive D...](https://cdn.slidesharecdn.com/ss_thumbnails/6g5gj25mtjwayniqem1t-6-251209104645-7a5a5fc6-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DSC Europe 25] Miodrag Pesovic & Vladislav Radonjic - Federated Data Archite...](https://cdn.slidesharecdn.com/ss_thumbnails/gsbe3y5it5uhndi4e08e-1-251212103249-f1008e0c-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Kaja Kandare - LLM as a judge.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/arxyccaxsdsd1ba99wjw-7-251212104007-2b4e3f64-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Branko Urosevic -Rethinking Financial Talent: Integrating Cod...](https://cdn.slidesharecdn.com/ss_thumbnails/8jjrus8ttko6qj64f58f-3-251212103250-642c6374-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Jovan Bogicevic - Legacy to AI-Driven Defense: Transforming D...](https://cdn.slidesharecdn.com/ss_thumbnails/rsarluadt563hntyfc8q-3-251211083849-3e7bc4c0-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Behzad Hosseini - AI Agents in the Wild: Deploying Models tha...](https://cdn.slidesharecdn.com/ss_thumbnails/3qtejajvsjqrzwfept2c-10-251212103250-7f2b1068-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Nikolay Burlutskiy - Best Practices for Building Enterprise M...](https://cdn.slidesharecdn.com/ss_thumbnails/uirvaiuvq8y1w8hzd9tx-7-251212103249-2619edb4-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Branko Dzakula - From Defense to Attack: How AI Redefines Cyb...](https://cdn.slidesharecdn.com/ss_thumbnails/80bdzdxpr3ky2g0qvyk9-8-251211083048-ce5fc1ee-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Marko Krstic - Understanding the AI Threat Landscape - Risks,...](https://cdn.slidesharecdn.com/ss_thumbnails/tiyim1ins5jvbrvzpzla-2-251209104645-c69d3553-thumbnail.jpg?width=640&height=640&fit=bounds)
