모니터링(Monitoring)
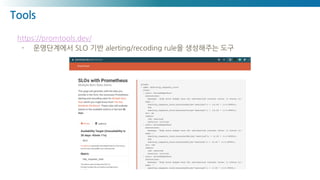
Google's Site ReliabilityEngineering (SRE) book
- 쿼리 카운트, 에러 카운트, 처리 시간, 서버의 활성 시간과 같은 시스템에 관련된 정량적 수치를 실시간으로
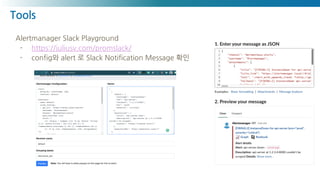
수집, 처리, 집계, 보여주는 모든 행위
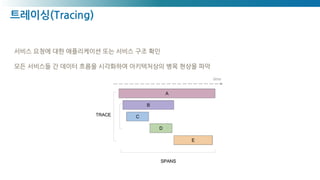
→ Signal, Telemetry, Trace 등을 수집하고 집계하는 행위 (Logging 포함)
→ 임계점을 넘어가는 상태에 대한 알림 및 조치
예) DB 디스크 사용량 임계점 초과시 알람 발생 및 통지 -> 스토리지 확장
6.
관측성, 관측가능성(Observability)
모니터링은 관측성의하위 집합
- 모니터링을 통해 상태를 확인하고, 특정 임계치에 대한 알람을 발생하기 위해 메트릭을 수집/집계
(Aggregation)
- 관측성은 예측 불가능한 모든 장애 가능성을 알 수 없다는 것을 전제로 함
예) 특정 user가 장바구니에서 페이먼트 옵션을 선택할때 10초가 걸림
모니터링 측면 - 디스크 사용량, I/O Queue, 시스템 상태 등
관측성 측면 - 지연시간, hops수, 메시지큐, DB, 서비스 대기 시간, 메시지 대기열 또는 데이터베이스에 관
련된 인프라 홉과 같은 요청 경로를 추적하고 특정 사용자 및 요청에 대해 데이터베이스 쿼리가 실행된 수
준까지 파악하는 것
7.
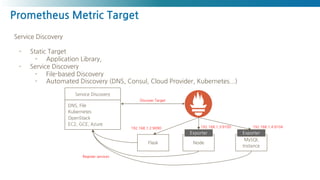
관측성 확보
- 관측성확보를 위해서는 세밀한(High Resolution) 데이터가 필요함
- 집계(Aggregation)보다 중요한건 수집된 데이터를 분석하는 능력
- 문제(장애) 발생시 필요한건 고해상도(high resolution) 메트릭(Metrics) 수집과 탐색 도구
8.
메트릭(Metrics)
응용 프로그램 및서비스의 성능과 품질을 측정하는 데 도움이 되는 정량 데이터
- Database 및 API의 Latency
- Request content length
- open file descriptor 수
- cache hit/miss 수
White-box vs Black-boxmonitoring
White-box monitoring
- 로그, JVM의 프로파일링과 같은 인터페이스 류, 또는 내부 통계정보를 보내주는
HTTP 핸들러를 포함한 시스템의 내부에 의해 노출된 측정 기준에 근거한 모니터링
- 내부 작동 상태 확인, 대시보드(시각화)를 통한 예측
Black-box monitoring
- 사용자로서 관찰하듯 보이는 현상을 외부에서 테스팅하는 것
- 호스트의 ICMP echo 응답 여부, 서비스 포트 오픈여부, HTTP 요청에 대해 정상적인 상태 코드(200)로 응
답하는지 등 외부에서 관찰되는 방식
- 시스템 또는 서비스에 문제가 생겼을때 관련 담당자에게 신속하게 알림
11.
메트릭 수집 방식의이해 (Push vs Pull)
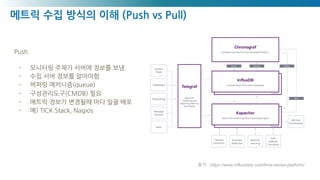
Push
- 모니터링 주체가 서버에 정보를 보냄
- 수집 서버 정보를 알아야함
- 버퍼링 메커니즘(queue)
- 구성관리도구(CMDB) 필요
- 메트릭 정보가 변경될때 마다 일괄 배포
- 예) TICK Stack, Nagios
출처 : https://www.influxdata.com/time-series-platform/
12.
메트릭 수집 방식의이해 (Push vs Pull)
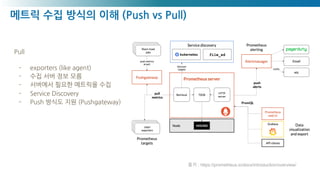
Pull
- exporters (like agent)
- 수집 서버 정보 모름
- 서버에서 필요한 메트릭을 수집
- Service Discovery
- Push 방식도 지원 (Pushgateway)
출처 : https://prometheus.io/docs/introduction/overview/
Origin Prometheus
Prometheus
- 영화: 프로메테우스
- 그리스 신화 티탄족(Titan) 신
- 선지자(先知者) - 먼저 생각하는 사람
- 능력 : 예지 능력
- 제우스의 불을 훔쳐 인간에게 전해줌
- 인간이 신의 지식을 얻어 각성
- 이로 인해 “판도라의 상자” 사건 발생
15.
Prometheus as asoftware
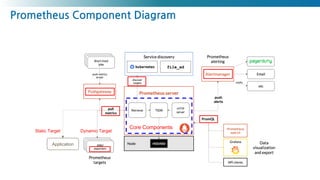
Prometheus : Metric Collector + Metric Database
- Open-source monitoring/alerting tool
- First Created by SoundCloud in 2012
- First Release of v1 in 2016
- CNCF 2nd Graduated Project in 2018
- Core Components
- Retrieval Worker (Pull/Scrape/Push)
- TSDB
- Simple Web Interface (React로 전환중)
- Service Discovery
- Alerting (email, slack, pageduty, opsgenie)
- Performance
Time Series
Database
• High write Performance
• Quick to process
• Easy Range Query
• Data Compaction
• Cost Efficient
Monitoring
Target
Discover & Pull Metric
16.
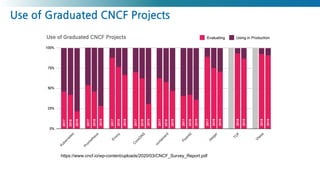
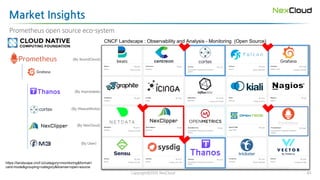
Use of GraduatedCNCF Projects
https://www.cncf.io/wp-content/uploads/2020/03/CNCF_Survey_Report.pdf
17.
Why Should Icare?
- 메트릭 수집을 위한 서버나 컨테이너 구성/설치 불필요
- 애플리케이션 에서 메트릭 푸시를 위해 CPU사용이 불필요
- 중앙 집중식 구성 및 관리 콘솔을 제공
- 서비스 장애 및 비가동 상황을 gracefully 처리 가능
- 수천,수만개의 메트릭을 직접 보지 않아도 되므로 트래픽 및 오버헤드 감소
- Pull 방식이 불가능 할 경우 Pushgateway로 Push 방식 수집 가능
Prometheus Metrics
Lables :multi-dimensional data (Key-Value)
메트릭 표
기 :
Metric name
(Prefix, Suffix)
Labels
(Multi Key-Value)
Timestamp
(Unix epoch,
Millisecond,
Optional)
Sample Value
(float64)
http_requests_total{method="post",code="200"} @1395066363000 3
Key Value
<metric name>{<label name>=<label value>, ...} <metric value>
20.
Prometheus Metrics Metadata
-상대적으로 사람이 쉽게 이해할만한 표현 형식 (metadata, metric)
- # HELP : 메트릭 이름, 간단한 설명
- # TYPE : 메트릭 데이터 타입 (summary, gauge, counter, histogram, untyped)
21.
Prometheus Core Metrics
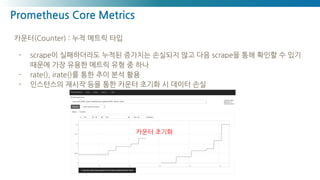
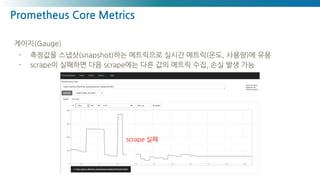
카운터(Counter): 누적 메트릭 타입
- scrape이 실패하더라도 누적된 증가치는 손실되지 않고 다음 scrape을 통해 확인할 수 있기
때문에 가장 유용한 메트릭 유형 중 하나
- rate(), irate()를 통한 추이 분석 활용
- 인스턴스의 재시작 등을 통한 카운터 초기화 시 데이터 손실
카운터 초기화
Expression Language DataTypes
데이터를 표시하기 위한 네가지 타입
- 인스턴트 벡터(Instant vector) : RE2 syntax, 연산자(operator), 레이블 매처(matcher)
- 레인지 벡터(Range vector) : 초(s), 분(m), 시간(h), 일(d), 주(w), 연(y) 단위로 사용
- 스칼라(Scalar)
차원없이 숫자(floating point value)로 구성된 값
- 문자열(String)
현재 미사용
http_requests_total{environment=~"staging|testing|development",method!="GET"}
http_requests_total{code="200"}[1m]
28.
Expression Language DataTypes
Core #0
Node Exporter
Core #1
Core #2
Core #3
Core #4
Core #5
Core #6
Core #7
Worker Node
node_cpu_seconds_total{cpu="0",mode="system"} 206496.96
node_cpu_seconds_total{cpu="1",mode="system"} 47096.98
node_cpu_seconds_total{cpu="2",mode="system"} 192391.71
node_cpu_seconds_total{cpu="3",mode="system"} 28804.35
node_cpu_seconds_total{cpu="4",mode="system"} 175341.59
node_cpu_seconds_total{cpu="5",mode="system"} 20919.87
node_cpu_seconds_total{cpu="6",mode="system"} 160830.69
node_cpu_seconds_total{cpu="7",mode="system"} 16465.97
206496.96
47096.98
192391.71
28804.35
175341.59
20919.87
160830.69
16465.97
t = now
인스턴트 벡터(Instant vector) 레인지 벡터(Range vector)
Core #0
CPU
Value
Core #5
CPU
Value
207136.96
207144.72
207159.13
207163.03
207164.97
207166.81
207173.37
207176.32
21085.56
21093.08
21093.57
21093.93
21094.35
21094.93
21095.35
21095.72
16635.97
16645.18
16645.89
16647.81
16648.32
16649.81
16650.23
16651.23
t = 2minutes
(15s 간격으로 총 8번 Scrape)
Core #7
CPU
Value
node_cpu_seconds_total{cpu="0",mode="system"}[2m] 207136.96 @1602831797.054
207144.72 @1602831812.054
207159.13 @1602831827.054
207163.03 @1602831842.054
207164.97 @1602831857.054
207166.81 @1602831872.054
207173.37 @1602831887.054
207176.32 @1602831902.054
Core #0
CPU
Value
Core #5
CPU
Value
Core #7
CPU
Value
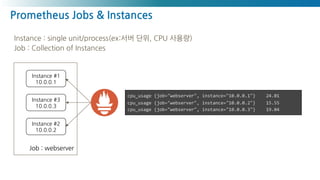
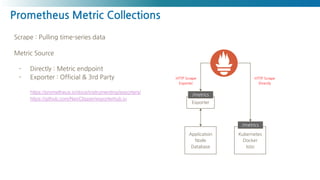
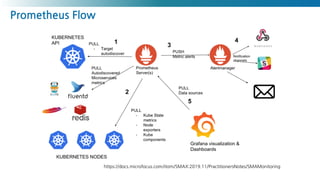
Prometheus Metric Collections
https://medium.com/nexclipper-io/prometheus-exporter-exporterhub-f29d63e0ae49
fromprometheus_client import start_http_server, Summary
import random
import time
# Create a metric to track time spent and requests made.
REQUEST_TIME = Summary('request_processing_seconds', 'Time spent processing request')
# Decorate function with metric.
@REQUEST_TIME.time()
def process_request(t):
"""A dummy function that takes some time."""
time.sleep(t)
if __name__ == '__main__':
# Start up the server to expose the metrics.
start_http_server(8000)
# Generate some requests.
while True:
process_request(random.random())
Client Library
- Go, Java(Scala), Python, Ruby (Official)
- 3rd Party Library (https://prometheus.io/docs/instrumenting/clientlibs/)
31.
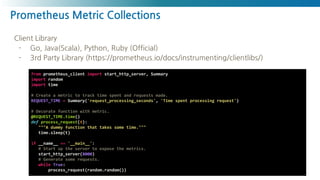
Prometheus Metric Collections
Exporter
-https://prometheus.io/docs/instrumenting/exporters/
- 코드를 직접 수정할수 없는 패키징 소프트웨어 메트릭이 노출시킬때 사용
- 네트워크, 스토리지, 데이터베이스 솔루션 또는 시스템 계측 시
https://github.com/NexClipper/exporterhub.io
32.
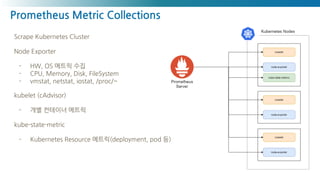
Prometheus Metric Collections
ScrapeKubernetes Cluster
Node Exporter
- HW, OS 메트릭 수집
- CPU, Memory, Disk, FileSystem
- vmstat, netstat, iostat, /proc/~
kubelet (cAdvisor)
- 개별 컨테이너 메트릭
kube-state-metric
- Kubernetes Resource 메트릭(deployment, pod 등)
33.
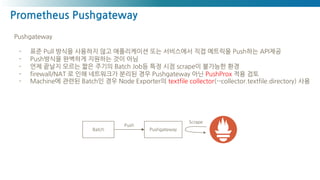
Prometheus Pushgateway
Pushgateway
- 표준Pull 방식을 사용하지 않고 애플리케이션 또는 서비스에서 직접 메트릭을 Push하는 API제공
- Push방식을 완벽하게 지원하는 것이 아님
- 언제 끝날지 모르는 짧은 주기의 Batch Job등 특정 시점 scrape이 불가능한 환경
- firewall/NAT 로 인해 네트워크가 분리된 경우 Pushgateway 아닌 PushProx 적용 검토
- Machine에 관련된 Batch인 경우 Node Exporter의 textfile collector(--collector.textfile.directory) 사용
Batch Pushgateway
Scrape
Push
Prometheus - Tech.Constraints
- 원시 로그 / 이벤트 수집 불가 : Loki, Elastic Stack
- 요청 추적(Request Tracing) 불가 : OpenMetrics, OpenCensus, OpenTelemetry
- 이상 감지(Anomaly Detection) 불가
- 장기 보관 및 고가용성 (Long-term Storage, HA) 어려움 : M3, Cortex, Thanos, VictoriaMetrics
- 스케일링(horizontal scaling)
- 사용자 인증 관리
41.
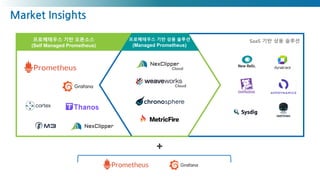
Prometheus - Mgmt.Constraints
초기 사용 방법 습득이 어렵고,
구성 및 설정 작업등이 많고 복잡함
(그라파나 사용, 멀티클러스터)
기업 환경에 필요한 기능 부족
(보안,접근제어, 통합뷰, 장기 데이타 저
장등)
Self managed가 어려울 경우
고가의 상용 모니터링 전환 필요
“We started with DataDog as our monitoring tool,.... However, when
we started to grow, the per host pricing model became too
expensive, and we decided to....Prometheus looked like it could be
the ultimate solution to our needs. but After realizing this solution
will not scale easily...decentralized the Prometheus servers..” from
Perimeterx engineering blog
"사용 방법을 습득하는 과정이 다소 어렵습니다. 모니터링 대상을 선정
하고, 알림 메시지 수신처를 설정하는 등 설정해야 하는 값도 상당히 많
습니다” By 라인 엔지니어링 블로그
“While Northern Trust likes the flexibility and granularity of
Prometheus, Strader admits to its fairly steep learning curve" and
high upfront costs to educate the team ... But we figured it was
significantly cheaper than commercial solutions..” by Behemoth
Northern Trust
“Prometheus’ scalability and durability is limited by single nodes. The
M3 platform aims to provide a turnkey, scalable, and configurable
multi-tenant store for Prometheus metrics.” From Uber’s engineering
blog:
“At a certain cluster scale, problems arise that go beyond the
capabilities of a vanilla Prometheus... store petabytes of historical
data ..access all of rom different Prometheus servers ... single
query API ..replicated data collected via Prometheus HA ” From
Improbalbe engineering blog:
Summary
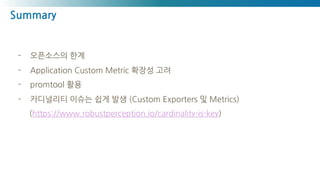
- 오픈소스의 한계
-Application Custom Metric 확장성 고려
- promtool 활용
- 카디널리티 이슈는 쉽게 발생 (Custom Exporters 및 Metrics)
(https://www.robustperception.io/cardinality-is-key)
65.
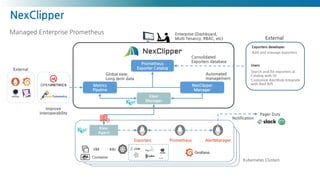
NexClipper
Managed Enterprise Prometheus
Exporters
Prometheus
ExporterCatalog
NexClipper
Manager
Metrics
Pipeline
Klevr
Agent
Prometheus
Kubernetes Clusters
AlertManager
Pager Duty
…
Notification
Automated
management
Global view,
Long term data
Consolidated
Exporters database
1
Add and manage exporters
Search and list exporters at
Catalog web UI
Customize AlertRule Integrate
with Rest API
Exporters developer
Users
External
Enterprise (Dashboard,
Multi Tenancy, RBAC, etc)
Klevr
Manager
VM K8s
Container
External
Improve
interoperability

















![Prometheus PromQL
rate(http_requests_total{job="apiserver", handler="/api/comments"}[5m])[30m:1m]
메트릭 이름 시계열 데이터(Labels)
5분간 초당 평균 변화율
1분 해상도로 30분 간 데이터 조회
메트릭을 검색(retrive)하기 위한 고유한 쿼리 언어(Query Language)](https://image.slidesharecdn.com/prometheusprojectjourney-201030010354/85/Prometheus-Project-Journey-25-320.jpg)
![Expression Language Data Types
데이터를 표시하기 위한 네가지 타입
- 인스턴트 벡터(Instant vector) : RE2 syntax, 연산자(operator), 레이블 매처(matcher)
- 레인지 벡터(Range vector) : 초(s), 분(m), 시간(h), 일(d), 주(w), 연(y) 단위로 사용
- 스칼라(Scalar)
차원없이 숫자(floating point value)로 구성된 값
- 문자열(String)
현재 미사용
http_requests_total{environment=~"staging|testing|development",method!="GET"}
http_requests_total{code="200"}[1m]](https://image.slidesharecdn.com/prometheusprojectjourney-201030010354/85/Prometheus-Project-Journey-27-320.jpg)
![Expression Language Data Types
Core #0
Node Exporter
Core #1
Core #2
Core #3
Core #4
Core #5
Core #6
Core #7
Worker Node
node_cpu_seconds_total{cpu="0",mode="system"} 206496.96
node_cpu_seconds_total{cpu="1",mode="system"} 47096.98
node_cpu_seconds_total{cpu="2",mode="system"} 192391.71
node_cpu_seconds_total{cpu="3",mode="system"} 28804.35
node_cpu_seconds_total{cpu="4",mode="system"} 175341.59
node_cpu_seconds_total{cpu="5",mode="system"} 20919.87
node_cpu_seconds_total{cpu="6",mode="system"} 160830.69
node_cpu_seconds_total{cpu="7",mode="system"} 16465.97
206496.96
47096.98
192391.71
28804.35
175341.59
20919.87
160830.69
16465.97
t = now
인스턴트 벡터(Instant vector) 레인지 벡터(Range vector)
Core #0
CPU
Value
Core #5
CPU
Value
207136.96
207144.72
207159.13
207163.03
207164.97
207166.81
207173.37
207176.32
21085.56
21093.08
21093.57
21093.93
21094.35
21094.93
21095.35
21095.72
16635.97
16645.18
16645.89
16647.81
16648.32
16649.81
16650.23
16651.23
t = 2minutes
(15s 간격으로 총 8번 Scrape)
Core #7
CPU
Value
node_cpu_seconds_total{cpu="0",mode="system"}[2m] 207136.96 @1602831797.054
207144.72 @1602831812.054
207159.13 @1602831827.054
207163.03 @1602831842.054
207164.97 @1602831857.054
207166.81 @1602831872.054
207173.37 @1602831887.054
207176.32 @1602831902.054
Core #0
CPU
Value
Core #5
CPU
Value
Core #7
CPU
Value](https://image.slidesharecdn.com/prometheusprojectjourney-201030010354/85/Prometheus-Project-Journey-28-320.jpg)


![Kubernetes Components Metrics
Target Endpoint
kube-apiservers https://[Master]:443/metrics
kube-contoller-manager https://[Master]:10252/metrics
kube-scheduler https://[Master]:10251/metrics
kubelet https://[Master]:10250/metrics
etcd https://[Master]:2379/metrics
cadvisor https://[ALL]:4194/metrics
Node Exporter https://[ALL]:9100/metrics
kube-state-metric
(exporter)
https://[kube-state-metric-pod]:8080/metrics
global:
scrape_interval: 15s
scrape_configs:
- job_name: node
static_configs:
- targets: ["node1:9100"]
- job_name: cadvisor
static_configs:
- targets: ["master:4194"]
- job_name: kube-state-metric
static_configs:
- targets: ["kube-state-metric:8080"]
ETCD 포함 Kubernetes의 모든 컴포넌트는 Prometheus의 metric 형태로 엔드포인트 제공.
Prometheus의 scrape 설정만으로 metric 수집이 가능](https://image.slidesharecdn.com/prometheusprojectjourney-201030010354/85/Prometheus-Project-Journey-36-320.jpg)
![Prometheus Alerting & Alertmanager
Alertmanager
Alert Rule
Alert Rule Email
OpsGenie
Slack
- alert: HostHighCpuLoad
expr: 100 - (avg by(instance) (irate(node_cpu_seconds_total{mode="idle"}[5m])) * 100) > 80
for: 5m
labels:
severity: warning
annotations:
summary: "Host high CPU load (instance {{ $labels.instance }})"
description: "CPU load is > 80%n VALUE = {{ $value }}n LABELS: {{ $labels }}"
• Alert Rules setting
• Alert Trigger
Prometheus
• Notification Channel Integration
• Send to Notification Channel
• Alert De-Duplication
• Alert Routing
• Silence
Alertmanager](https://image.slidesharecdn.com/prometheusprojectjourney-201030010354/85/Prometheus-Project-Journey-37-320.jpg)











![[야생의 땅: 듀랑고] 서버 아키텍처 - SPOF 없는 분산 MMORPG 서버](https://cdn.slidesharecdn.com/ss_thumbnails/public-140529222503-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)

![[오픈소스컨설팅]Scouter 설치 및 사용가이드(JBoss)](https://cdn.slidesharecdn.com/ss_thumbnails/scouterjboss-160310001021-thumbnail.jpg?width=640&height=640&fit=bounds)

![[OpenStack Days Korea 2016] Track1 - 카카오는 오픈스택 기반으로 어떻게 5000VM을 운영하고 있을까?](https://cdn.slidesharecdn.com/ss_thumbnails/16kakao-160226171853-thumbnail.jpg?width=640&height=640&fit=bounds)

![[221] 딥러닝을 이용한 지역 컨텍스트 검색 김진호](https://cdn.slidesharecdn.com/ss_thumbnails/221-161025004534-thumbnail.jpg?width=640&height=640&fit=bounds)


![[NDC17] Kubernetes로 개발서버 간단히 찍어내기](https://cdn.slidesharecdn.com/ss_thumbnails/ndc-170529041601-thumbnail.jpg?width=640&height=640&fit=bounds)



![[261] 실시간 추천엔진 머신한대에 구겨넣기](https://cdn.slidesharecdn.com/ss_thumbnails/216-150915054828-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)


![[야생의 땅: 듀랑고] 서버 아키텍처 Vol. 2 (자막)](https://cdn.slidesharecdn.com/ss_thumbnails/vol2-160427160825-thumbnail.jpg?width=640&height=640&fit=bounds)





![[160402_데브루키_박민근] UniRx 소개](https://cdn.slidesharecdn.com/ss_thumbnails/160402unirx-160403045953-thumbnail.jpg?width=640&height=640&fit=bounds)
![오딘: 발할라 라이징 MMORPG의 성능 최적화 사례 공유 [카카오게임즈 - 레벨 300] - 발표자: 김문권, 팀장, 라이온하트 스튜디오...](https://cdn.slidesharecdn.com/ss_thumbnails/t3s1-221108101729-c6b32f4f-thumbnail.jpg?width=640&height=640&fit=bounds)



![[2019] 200만 동접 게임을 위한 MySQL 샤딩](https://cdn.slidesharecdn.com/ss_thumbnails/nhnforward201923-200122092657-thumbnail.jpg?width=640&height=640&fit=bounds)
![[MeetUp][3rd] Prometheus 와 함께하는 모니터링 및 시각화](https://cdn.slidesharecdn.com/ss_thumbnails/prometheus-200424015637-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2018] NHN 모니터링의 현재와 미래 for 인프라 엔지니어](https://cdn.slidesharecdn.com/ss_thumbnails/cloudinfra02-190131073314-thumbnail.jpg?width=640&height=640&fit=bounds)
![[CNKCD2025] Metric & Trace 제대로 챙기기: Grafana Stack + Alloy 중심의 데이터 수집/저장 효율화 과정](https://cdn.slidesharecdn.com/ss_thumbnails/cnkcd2025-manage-metrics-and-traces-in-k8s-250921152913-26ffcece-thumbnail.jpg?width=640&height=640&fit=bounds)









![[232] 수퍼컴퓨팅과 데이터 어낼리틱스](https://cdn.slidesharecdn.com/ss_thumbnails/223-150915022242-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)

















