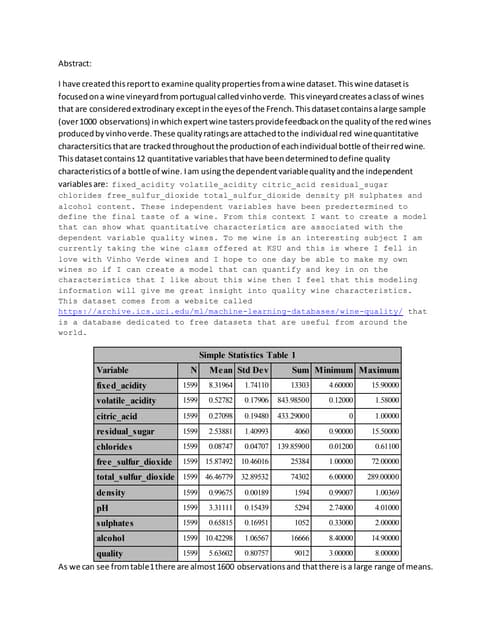
The document describes a machine learning project that compares the performance of R packages for logistic regression and random forest algorithms on wine quality datasets. It loads and prepares the datasets, then explores the data through descriptive statistics. Logistic regression and random forest models are applied to the training data and evaluated on test data.


![## $ total.sulfur.dioxide: num 170 132 97 186 186 97 136 170 132 129 ...
## $ density : num 1.001 0.994 0.995 0.996 0.996 ...
## $ pH : num 3 3.3 3.26 3.19 3.19 3.26 3.18 3 3.3 3.22 ...
## $ sulphates : num 0.45 0.49 0.44 0.4 0.4 0.44 0.47 0.45 0.49 0.45 ...
## $ alcohol : num 8.8 9.5 10.1 9.9 9.9 10.1 9.6 8.8 9.5 11 ...
## $ quality : int 6 6 6 6 6 6 6 6 6 6 ...
Create class labels
red<- red %>%
mutate (drinkit = as.factor(as.numeric(quality >= 7 )))
class(red$drinkit)
## [1] "factor"
white<- white %>%
mutate (drinkit = as.factor(as.numeric(quality >= 7 )))
class(white$drinkit)
## [1] "factor"
Create test and train datasets
set.seed(123)
sample = sample.split(red$drinkit, SplitRatio = .70)
redtrain = subset(red, sample == TRUE)
redtest = subset(red, sample == FALSE)
sample <-sample.split(white$drinkit, SplitRatio = .70)
whitetrain <- subset(white, sample == TRUE)
whitetest <- subset(white, sample == FALSE)
dim(redtrain) #70% for training
## [1] 1119 13
dim(redtest) #30% for test
## [1] 480 13
dim(whitetrain)
## [1] 3429 13
dim(whitetest)
## [1] 1469 13
3](https://image.slidesharecdn.com/aml-final-project-210603200038/75/IU-Applied-Machine-Learning-Class-Final-Project-ML-Methods-for-Predicting-Wine-Preference-3-2048.jpg)
![DATA EXPLORATION
Descriptive statistics
by(red[1:12][,c(1:12)], red$drinkit, basicStats)
## red$drinkit: 0
## fixed.acidity volatile.acidity citric.acid residual.sugar
## nobs 1382.000000 1382.000000 1382.000000 1382.000000
## NAs 0.000000 0.000000 0.000000 0.000000
## Minimum 4.600000 0.160000 0.000000 0.900000
## Maximum 15.900000 1.580000 1.000000 15.500000
## 1. Quartile 7.100000 0.420000 0.082500 1.900000
## 3. Quartile 9.100000 0.650000 0.400000 2.600000
## Mean 8.236831 0.547022 0.254407 2.512120
## Median 7.800000 0.540000 0.240000 2.200000
## Sum 11383.300000 755.985000 351.590000 3471.750000
## SE Mean 0.045265 0.004743 0.005102 0.038084
## LCL Mean 8.148036 0.537717 0.244398 2.437412
## UCL Mean 8.325626 0.556327 0.264415 2.586829
## Variance 2.831568 0.031095 0.035973 2.004428
## Stdev 1.682726 0.176337 0.189665 1.415778
## Skewness 1.071064 0.670310 0.422857 4.878595
## Kurtosis 1.337482 1.438348 -0.673833 32.003919
## chlorides free.sulfur.dioxide total.sulfur.dioxide
## nobs 1382.000000 1382.000000 1382.000000
## NAs 0.000000 0.000000 0.000000
## Minimum 0.034000 1.000000 6.000000
## Maximum 0.611000 72.000000 165.000000
## 1. Quartile 0.071000 8.000000 23.000000
## 3. Quartile 0.091000 22.000000 65.000000
## Mean 0.089281 16.172214 48.285818
## Median 0.080000 14.000000 39.500000
## Sum 123.386000 22350.000000 66731.000000
## SE Mean 0.001321 0.281577 0.876540
## LCL Mean 0.086689 15.619850 46.566324
## UCL Mean 0.091872 16.724578 50.005312
## Variance 0.002412 109.572421 1061.821580
## Stdev 0.049113 10.467685 32.585604
## Skewness 5.547353 1.224203 1.110405
## Kurtosis 38.898772 2.056348 0.704994
## density pH sulphates alcohol quality
## nobs 1382.000000 1382.000000 1382.000000 1382.000000 1382.000000
## NAs 0.000000 0.000000 0.000000 0.000000 0.000000
## Minimum 0.990070 2.740000 0.330000 8.400000 3.000000
## Maximum 1.003690 4.010000 2.000000 14.900000 6.000000
## 1. Quartile 0.995785 3.210000 0.540000 9.500000 5.000000
## 3. Quartile 0.997900 3.410000 0.700000 10.900000 6.000000
## Mean 0.996859 3.314616 0.644754 10.251037 5.408828
## Median 0.996800 3.310000 0.600000 10.000000 5.000000
## Sum 1377.659370 4580.800000 891.050000 14166.933333 7475.000000
## SE Mean 0.000049 0.004146 0.004590 0.026084 0.016186
## LCL Mean 0.996764 3.306483 0.635750 10.199869 5.377076
4](https://image.slidesharecdn.com/aml-final-project-210603200038/75/IU-Applied-Machine-Learning-Class-Final-Project-ML-Methods-for-Predicting-Wine-Preference-4-2048.jpg)

![## Variance 0.023863 0.017966 0.996310 0.076421
## Stdev 0.154478 0.134038 0.998153 0.276443
## Skewness 0.358697 0.620835 0.065494 3.003356
## Kurtosis 0.608113 1.964857 -0.430136 7.052712
by(white[1:12][,c(1:12)], white$drinkit, basicStats)
## white$drinkit: 0
## fixed.acidity volatile.acidity citric.acid residual.sugar
## nobs 3838.000000 3838.000000 3838.000000 3838.000000
## NAs 0.000000 0.000000 0.000000 0.000000
## Minimum 3.800000 0.080000 0.000000 0.600000
## Maximum 14.200000 1.100000 1.660000 65.800000
## 1. Quartile 6.300000 0.220000 0.260000 1.700000
## 3. Quartile 7.400000 0.320000 0.400000 10.400000
## Mean 6.890594 0.281802 0.336438 6.703478
## Median 6.800000 0.270000 0.320000 6.000000
## Sum 26446.100000 1081.555000 1291.250000 25727.950000
## SE Mean 0.013884 0.001651 0.002098 0.084341
## LCL Mean 6.863374 0.278564 0.332325 6.538121
## UCL Mean 6.917814 0.285039 0.340551 6.868835
## Variance 0.739786 0.010464 0.016889 27.301127
## Stdev 0.860108 0.102293 0.129959 5.225048
## Skewness 0.752179 1.720644 1.242293 1.035464
## Kurtosis 2.339990 5.737845 5.472595 3.755082
## chlorides free.sulfur.dioxide total.sulfur.dioxide
## nobs 3838.000000 3.838000e+03 3.838000e+03
## NAs 0.000000 0.000000e+00 0.000000e+00
## Minimum 0.009000 2.000000e+00 9.000000e+00
## Maximum 0.346000 2.890000e+02 4.400000e+02
## 1. Quartile 0.037000 2.300000e+01 1.110000e+02
## 3. Quartile 0.051000 4.700000e+01 1.730000e+02
## Mean 0.047875 3.551733e+01 1.419829e+02
## Median 0.045000 3.400000e+01 1.400000e+02
## Sum 183.743000 1.363155e+05 5.449305e+05
## SE Mean 0.000380 2.871250e-01 7.125790e-01
## LCL Mean 0.047129 3.495439e+01 1.405859e+02
## UCL Mean 0.048620 3.608026e+01 1.433800e+02
## Variance 0.000554 3.164067e+02 1.948817e+03
## Stdev 0.023548 1.778783e+01 4.414540e+01
## Skewness 4.851869 1.423264e+00 2.830020e-01
## Kurtosis 33.327716 1.178770e+01 4.934680e-01
## density pH sulphates alcohol quality
## nobs 3838.000000 3838.000000 3838.000000 3838.000000 3838.000000
## NAs 0.000000 0.000000 0.000000 0.000000 0.000000
## Minimum 0.987220 2.720000 0.230000 8.000000 3.000000
## Maximum 1.038980 3.810000 1.060000 14.000000 6.000000
## 1. Quartile 0.992320 3.080000 0.410000 9.400000 5.000000
## 3. Quartile 0.996570 3.267500 0.540000 11.000000 6.000000
## Mean 0.994474 3.180847 0.487004 10.265215 5.519802
## Median 0.994380 3.170000 0.470000 10.000000 6.000000
## Sum 3816.789390 12208.090000 1869.120000 39397.896667 21185.000000
## SE Mean 0.000047 0.002396 0.001746 0.017765 0.009764
## LCL Mean 0.994382 3.176150 0.483580 10.230385 5.500659
6](https://image.slidesharecdn.com/aml-final-project-210603200038/75/IU-Applied-Machine-Learning-Class-Final-Project-ML-Methods-for-Predicting-Wine-Preference-6-2048.jpg)





















![## volatile.acidity -4.49437 0.91316 -4.922 8.58e-07 ***
## citric.acid 0.31682 0.97102 0.326 0.74422
## residual.sugar 0.10574 0.06983 1.514 0.12996
## total.sulfur.dioxide -0.01329 0.00419 -3.172 0.00151 **
## chlorides -6.34684 4.16619 -1.523 0.12765
## alcohol 0.91992 0.10404 8.842 < 2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 889.23 on 1118 degrees of freedom
## Residual deviance: 634.16 on 1111 degrees of freedom
## AIC: 650.16
##
## Number of Fisher Scoring iterations: 6
exp(cbind(OR = coef(redmodel1), confint(redmodel1))) # odds ratios and 95% CI
## Waiting for profiling to be done...
## OR 2.5 % 97.5 %
## (Intercept) 3.993409e-05 1.934350e-06 0.0007319036
## fixed.acidity 1.131655e+00 9.622602e-01 1.3339255345
## volatile.acidity 1.117174e-02 1.792495e-03 0.0642802846
## citric.acid 1.372752e+00 2.016707e-01 9.1164704929
## residual.sugar 1.111529e+00 9.597369e-01 1.2685734018
## total.sulfur.dioxide 9.867968e-01 9.783435e-01 0.9945651864
## chlorides 1.752269e-03 2.005370e-07 2.3287091038
## alcohol 2.509101e+00 2.055529e+00 3.0926740162
Model 1 performance
redtrain$drinkitYhat <- predict(redmodel1, type = "response") # generate yhat values on train df
redtrain$drinkitYhat <- ifelse(redtrain$drinkitYhat > 0.5, 1.0, 0.0)
confusionMatrix( redtrain$drinkitYhat, redtrain$drinkit) # run confusionMatrix to assess accuracy
## Confusion Matrix and Statistics
##
## Reference
## Prediction 0 1
## 0 932 110
## 1 35 42
##
## Accuracy : 0.8704
## 95% CI : (0.8493, 0.8896)
## No Information Rate : 0.8642
## P-Value [Acc > NIR] : 0.2878
##
## Kappa : 0.3032
## Mcnemar's Test P-Value : 7.978e-10
##
28](https://image.slidesharecdn.com/aml-final-project-210603200038/75/IU-Applied-Machine-Learning-Class-Final-Project-ML-Methods-for-Predicting-Wine-Preference-28-2048.jpg)

![## OR 2.5 % 97.5 %
## (Intercept) 0.0001361775 1.429867e-05 0.001198158
## volatile.acidity 0.0054547915 1.276332e-03 0.021452206
## total.sulfur.dioxide 0.9863066898 9.780499e-01 0.993846316
## alcohol 2.5190775373 2.097376e+00 3.051543824
Model 2 performance
redtrain$drinkitYhat <- predict(redmodel2, type = "response") # generate yhat values on train df
redtrain$drinkitYhat <- ifelse(redtrain$drinkitYhat > 0.5, 1.0, 0.0)
confusionMatrix( redtrain$drinkitYhat, redtrain$drinkit) # run confusionMatrix to assess accuracy
## Confusion Matrix and Statistics
##
## Reference
## Prediction 0 1
## 0 934 112
## 1 33 40
##
## Accuracy : 0.8704
## 95% CI : (0.8493, 0.8896)
## No Information Rate : 0.8642
## P-Value [Acc > NIR] : 0.2878
##
## Kappa : 0.2933
## Mcnemar's Test P-Value : 9.323e-11
##
## Sensitivity : 0.9659
## Specificity : 0.2632
## Pos Pred Value : 0.8929
## Neg Pred Value : 0.5479
## Prevalence : 0.8642
## Detection Rate : 0.8347
## Detection Prevalence : 0.9348
## Balanced Accuracy : 0.6145
##
## 'Positive' Class : 0
##
auc(roc(redtrain$drinkit, redtrain$drinkitYhat ), levels=levels(as.factor(redtrain$drinkit))) # calcula
## Area under the curve: 0.6145
Model 3
redmodel3 <- glm(drinkit ~ alcohol, family="binomial", data= redtrain)
summary(redmodel3)
##
## Call:
## glm(formula = drinkit ~ alcohol, family = "binomial", data = redtrain)
30](https://image.slidesharecdn.com/aml-final-project-210603200038/75/IU-Applied-Machine-Learning-Class-Final-Project-ML-Methods-for-Predicting-Wine-Preference-30-2048.jpg)
![##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -2.2384 -0.5138 -0.3279 -0.2540 2.6650
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) -13.11263 1.00437 -13.06 <2e-16 ***
## alcohol 1.04246 0.08978 11.61 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 889.23 on 1118 degrees of freedom
## Residual deviance: 724.88 on 1117 degrees of freedom
## AIC: 728.88
##
## Number of Fisher Scoring iterations: 5
exp(cbind(OR = coef(redmodel3), confint(redmodel3))) # odds ratios and 95% CI
## Waiting for profiling to be done...
## OR 2.5 % 97.5 %
## (Intercept) 2.019563e-06 2.659407e-07 1.371582e-05
## alcohol 2.836199e+00 2.388290e+00 3.397552e+00
Model 3 performance
redtrain$drinkitYhat <- predict(redmodel3, type = "response") # generate yhat values on train df
redtrain$drinkitYhat <- ifelse(redtrain$drinkitYhat > 0.5, 1.0, 0.0)
confusionMatrix( redtrain$drinkitYhat, redtrain$drinkit) # run confusionMatrix to assess accuracy
## Confusion Matrix and Statistics
##
## Reference
## Prediction 0 1
## 0 943 131
## 1 24 21
##
## Accuracy : 0.8615
## 95% CI : (0.8398, 0.8812)
## No Information Rate : 0.8642
## P-Value [Acc > NIR] : 0.6236
##
## Kappa : 0.1611
## Mcnemar's Test P-Value : <2e-16
##
## Sensitivity : 0.9752
## Specificity : 0.1382
## Pos Pred Value : 0.8780
31](https://image.slidesharecdn.com/aml-final-project-210603200038/75/IU-Applied-Machine-Learning-Class-Final-Project-ML-Methods-for-Predicting-Wine-Preference-31-2048.jpg)
![## Neg Pred Value : 0.4667
## Prevalence : 0.8642
## Detection Rate : 0.8427
## Detection Prevalence : 0.9598
## Balanced Accuracy : 0.5567
##
## 'Positive' Class : 0
##
auc(roc(redtrain$drinkit, redtrain$drinkitYhat ), levels=levels(as.factor(redtrain$drinkit))) # calcula
## Area under the curve: 0.5567
Use best model (model 2) for testset prediction
redtest$drinkitYhat <- predict(redmodel2, newdata = redtest, type = "response") # predict values on tra
redtest$drinkitYhat <- ifelse(redtest$drinkitYhat > 0.5, 1.0, 0.0)
confusionMatrix(redtest$drinkitYhat, redtest$drinkit) # run confusionMatrix to assess accuracy
## Confusion Matrix and Statistics
##
## Reference
## Prediction 0 1
## 0 402 49
## 1 13 16
##
## Accuracy : 0.8708
## 95% CI : (0.8375, 0.8995)
## No Information Rate : 0.8646
## P-Value [Acc > NIR] : 0.3749
##
## Kappa : 0.2803
## Mcnemar's Test P-Value : 8.789e-06
##
## Sensitivity : 0.9687
## Specificity : 0.2462
## Pos Pred Value : 0.8914
## Neg Pred Value : 0.5517
## Prevalence : 0.8646
## Detection Rate : 0.8375
## Detection Prevalence : 0.9396
## Balanced Accuracy : 0.6074
##
## 'Positive' Class : 0
##
auc(roc(redtest$drinkit, redtest$drinkitYhat), levels=levels(as.factor(redtrain$drinkit))) # calculate
## Area under the curve: 0.6074
32](https://image.slidesharecdn.com/aml-final-project-210603200038/75/IU-Applied-Machine-Learning-Class-Final-Project-ML-Methods-for-Predicting-Wine-Preference-32-2048.jpg)

![Model 1 performance
whitetrain$drinkitYhat <- predict(whitemodel1, type = "response") # generate yhat values on train df
whitetrain$drinkitYhat <- ifelse(whitetrain$drinkitYhat > 0.5, 1.0, 0.0)
confusionMatrix( whitetrain$drinkitYhat, whitetrain$drinkit) # run confusionMatrix to assess accuracy
## Confusion Matrix and Statistics
##
## Reference
## Prediction 0 1
## 0 2532 565
## 1 155 177
##
## Accuracy : 0.79
## 95% CI : (0.776, 0.8036)
## No Information Rate : 0.7836
## P-Value [Acc > NIR] : 0.1865
##
## Kappa : 0.2261
## Mcnemar's Test P-Value : <2e-16
##
## Sensitivity : 0.9423
## Specificity : 0.2385
## Pos Pred Value : 0.8176
## Neg Pred Value : 0.5331
## Prevalence : 0.7836
## Detection Rate : 0.7384
## Detection Prevalence : 0.9032
## Balanced Accuracy : 0.5904
##
## 'Positive' Class : 0
##
auc(roc(whitetrain$drinkit, whitetrain$drinkitYhat ), levels=levels(as.factor(whitetrain$drinkit))) # c
## Area under the curve: 0.5904
Model 2
whitemodel2 <- glm(drinkit ~ volatile.acidity+residual.sugar+chlorides+alcohol, family="binomial",
data= whitetrain)
summary(whitemodel2)
##
## Call:
## glm(formula = drinkit ~ volatile.acidity + residual.sugar + chlorides +
## alcohol, family = "binomial", data = whitetrain)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -1.9024 -0.6594 -0.4260 -0.1902 2.8269
34](https://image.slidesharecdn.com/aml-final-project-210603200038/75/IU-Applied-Machine-Learning-Class-Final-Project-ML-Methods-for-Predicting-Wine-Preference-34-2048.jpg)
![##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) -9.09922 0.63146 -14.410 < 2e-16 ***
## volatile.acidity -4.68741 0.56405 -8.310 < 2e-16 ***
## residual.sugar 0.04845 0.01115 4.345 1.39e-05 ***
## chlorides -18.36325 4.41268 -4.161 3.16e-05 ***
## alcohol 0.88237 0.04981 17.714 < 2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 3581.9 on 3428 degrees of freedom
## Residual deviance: 2947.1 on 3424 degrees of freedom
## AIC: 2957.1
##
## Number of Fisher Scoring iterations: 5
exp(cbind(OR = coef(whitemodel2), confint(whitemodel2))) # odds ratios and 95% CI
## Waiting for profiling to be done...
## OR 2.5 % 97.5 %
## (Intercept) 1.117534e-04 3.232733e-05 3.849781e-04
## volatile.acidity 9.210485e-03 2.998984e-03 2.737557e-02
## residual.sugar 1.049642e+00 1.026810e+00 1.072716e+00
## chlorides 1.059114e-08 1.369508e-12 4.332245e-05
## alcohol 2.416612e+00 2.193714e+00 2.667033e+00
Model 2 performance
whitetrain$drinkitYhat <- predict(whitemodel2, type = "response") # generate yhat values on train df
whitetrain$drinkitYhat <- ifelse(whitetrain$drinkitYhat > 0.5, 1.0, 0.0)
confusionMatrix( whitetrain$drinkitYhat, whitetrain$drinkit) # run confusionMatrix to assess accuracy
## Confusion Matrix and Statistics
##
## Reference
## Prediction 0 1
## 0 2536 564
## 1 151 178
##
## Accuracy : 0.7915
## 95% CI : (0.7775, 0.805)
## No Information Rate : 0.7836
## P-Value [Acc > NIR] : 0.1357
##
## Kappa : 0.23
## Mcnemar's Test P-Value : <2e-16
##
## Sensitivity : 0.9438
35](https://image.slidesharecdn.com/aml-final-project-210603200038/75/IU-Applied-Machine-Learning-Class-Final-Project-ML-Methods-for-Predicting-Wine-Preference-35-2048.jpg)
![## Specificity : 0.2399
## Pos Pred Value : 0.8181
## Neg Pred Value : 0.5410
## Prevalence : 0.7836
## Detection Rate : 0.7396
## Detection Prevalence : 0.9041
## Balanced Accuracy : 0.5918
##
## 'Positive' Class : 0
##
auc(roc(whitetrain$drinkit, whitetrain$drinkitYhat ), levels=levels(as.factor(whitetrain$drinkit))) # c
## Area under the curve: 0.5918
Use best model (model 2) for testset prediction
whitetest$drinkitYhat <- predict(whitemodel2, newdata = whitetest, type = "response")
whitetest$drinkitYhat <- ifelse(whitetest$drinkitYhat > 0.5, 1.0, 0.0)
confusionMatrix(whitetest$drinkitYhat, whitetest$drinkit) # run confusionMatrix to assess accuracy
## Confusion Matrix and Statistics
##
## Reference
## Prediction 0 1
## 0 1081 242
## 1 70 76
##
## Accuracy : 0.7876
## 95% CI : (0.7658, 0.8083)
## No Information Rate : 0.7835
## P-Value [Acc > NIR] : 0.3657
##
## Kappa : 0.2215
## Mcnemar's Test P-Value : <2e-16
##
## Sensitivity : 0.9392
## Specificity : 0.2390
## Pos Pred Value : 0.8171
## Neg Pred Value : 0.5205
## Prevalence : 0.7835
## Detection Rate : 0.7359
## Detection Prevalence : 0.9006
## Balanced Accuracy : 0.5891
##
## 'Positive' Class : 0
##
auc(roc(whitetest$drinkit, whitetest$drinkitYhat), levels=levels(as.factor(whitetrain$drinkit))) # calc
## Area under the curve: 0.5891
36](https://image.slidesharecdn.com/aml-final-project-210603200038/75/IU-Applied-Machine-Learning-Class-Final-Project-ML-Methods-for-Predicting-Wine-Preference-36-2048.jpg)

![Testset prediction
rf1predict <-predict(rf1, redtest, type="response")
Model performance on testset
confusionMatrix( rf1predict, redtest$drinkit ) # run confusionMatrix to assess accuracy
## Confusion Matrix and Statistics
##
## Reference
## Prediction 0 1
## 0 397 27
## 1 18 38
##
## Accuracy : 0.9062
## 95% CI : (0.8766, 0.9308)
## No Information Rate : 0.8646
## P-Value [Acc > NIR] : 0.003355
##
## Kappa : 0.5748
## Mcnemar's Test P-Value : 0.233038
##
## Sensitivity : 0.9566
## Specificity : 0.5846
## Pos Pred Value : 0.9363
## Neg Pred Value : 0.6786
## Prevalence : 0.8646
## Detection Rate : 0.8271
## Detection Prevalence : 0.8833
## Balanced Accuracy : 0.7706
##
## 'Positive' Class : 0
##
rf1predict<- as.numeric(rf1predict)
auc(roc(redtest$drinkit, rf1predict )) # calculate AUROC curve
## Area under the curve: 0.7706
Random forest algorithm - white wine dataset
set.seed(77)
rf3 <- randomForest(drinkit ~ volatile.acidity+residual.sugar+chlorides+alcohol, type = classification,
data=whitetrain, ntree = 1000, importance = TRUE,confusion = TRUE)
round(importance(rf3), 1)
## 0 1 MeanDecreaseAccuracy MeanDecreaseGini
## volatile.acidity 45.4 128.0 113.4 248.4
38](https://image.slidesharecdn.com/aml-final-project-210603200038/75/IU-Applied-Machine-Learning-Class-Final-Project-ML-Methods-for-Predicting-Wine-Preference-38-2048.jpg)
![## residual.sugar 48.0 105.0 110.3 295.5
## chlorides 32.6 116.0 101.8 251.7
## alcohol 68.0 226.6 179.2 359.4
print(rf3)
##
## Call:
## randomForest(formula = drinkit ~ volatile.acidity + residual.sugar + chlorides + alcohol, data
## Type of random forest: classification
## Number of trees: 1000
## No. of variables tried at each split: 2
##
## OOB estimate of error rate: 14.44%
## Confusion matrix:
## 0 1 class.error
## 0 2521 166 0.06177894
## 1 329 413 0.44339623
Testset prediction
rf3predict <-predict(rf3, whitetest, type="response")
Model performance on testset
confusionMatrix( rf3predict, whitetest$drinkit ) # run confusionMatrix to assess accuracy
## Confusion Matrix and Statistics
##
## Reference
## Prediction 0 1
## 0 1075 140
## 1 76 178
##
## Accuracy : 0.853
## 95% CI : (0.8338, 0.8707)
## No Information Rate : 0.7835
## P-Value [Acc > NIR] : 9.184e-12
##
## Kappa : 0.5325
## Mcnemar's Test P-Value : 1.814e-05
##
## Sensitivity : 0.9340
## Specificity : 0.5597
## Pos Pred Value : 0.8848
## Neg Pred Value : 0.7008
## Prevalence : 0.7835
## Detection Rate : 0.7318
## Detection Prevalence : 0.8271
## Balanced Accuracy : 0.7469
##
39](https://image.slidesharecdn.com/aml-final-project-210603200038/75/IU-Applied-Machine-Learning-Class-Final-Project-ML-Methods-for-Predicting-Wine-Preference-39-2048.jpg)






















































![ict_presentation_final_final_final[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/ictpresentationfinalfinalfinal1-251230145259-2b4839bd-thumbnail.jpg?width=640&height=640&fit=bounds)






