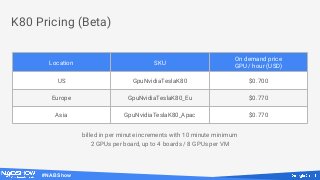
Downloaded 12 times



















![#NABShow
Creating a
workstation
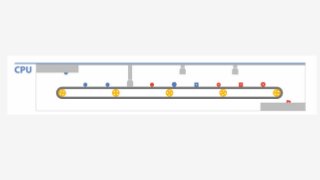
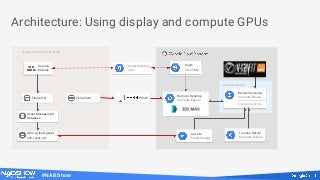
For this job, we needed to run
project-specific software
(Autodesk 3DS Max) that only
runs on Windows.
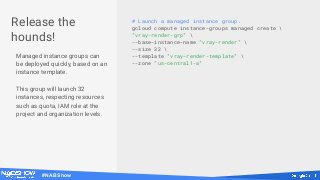
# Create a workstation.
gcloud compute instances create "remote-work"
--zone "us-central1-a"
--machine-type "n1-standard-32"
--accelerator [type=,count=1]
--can-ip-forward --maintenance-policy "TERMINATE"
--tags "https-server"
--image "windows-server-2008-r2-dc-v20170214"
--image-project "windows-cloud"
--boot-disk-size 250
--no-boot-disk-auto-delete
--boot-disk-type "pd-ssd"
--boot-disk-device-name "remote-work-boot"
2
3
1
1 Choose from zones in
us-east1, us-west1,
europe-west1, and asia-east1.
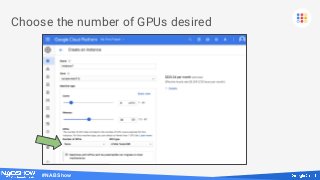
2 Choose type and number of
attached GPUs.
3 Attach a GPU to an instance
with any public image.](https://image.slidesharecdn.com/vnabsuperchargeperformanceusinggpus-170331071830/85/Supercharge-performance-using-GPUs-in-the-cloud-39-320.jpg?cb=1490944768)






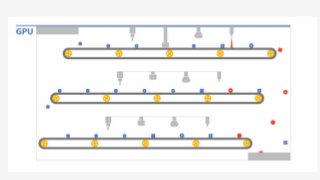
GPUs have thousands of compute cores and when coupled with lightning fast memory access they accelerate machine learning, gaming, database queries, video rendering and transcoding, computational finance, molecular dynamics and many other applications. With GPUs in the cloud, you can scale your calculation-heavy application without constructing your own data center. We'll give an overview of what we're offering in Google Cloud and talk about how to put GPUs to work. We will also showcase a number of commercial applications which require GPUs. Speaker: John Barrus, Google















































