在這個實驗中,我們將原本 MNIST 中的 label 完全打亂。因此,training data 的 image 與 label 間將不再有任何關聯。
我們一樣做三個 warm up 實驗。
在前兩張圖可以看到,高瘦的網路在參數量差不多時,有著碾壓性的表現,而在參數量只有一半時,仍有相似的擬合能力。而圖三則顯示如果每層神經元太少,加深網路的意義不大。
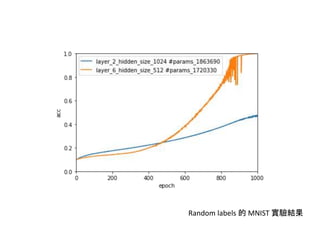
這裡藏著一個值得注意的信號,圖三中兩個網路的準確率幾乎是完全不上升的,與對照組相比,在一樣都只有那麼少參數的情況下,對照組仍然能達到超過 90% 的準確度。
還記得我們在 section3 discussion 中提出的假設:”DNNs 可能是學習 patterns 再將 noise 以增加 capacity 的方式暴力記憶” 嗎?在對照組中,雖然參數少,但因為學到了某些 data 中的 pattern,因此可以達到一定的準確度,並且有可能是因為參數量不足以完整學習 pattern,才沒有達到 training error = 0%。但在 random label (可以想成全部 data 都是 noise) 的情況下,因為沒有 pattern 可學,所以轉成暴力記憶,卻又因參數不夠,導致訓練失敗。
在圖四到圖八以及圖十三到圖十七中,我們 fix 住網路的層數,只改變每一層神經元個數。
在圖九到圖十二以及圖十八到圖二十一中,我們 fix 住每一層神經元個數,只改變層數多寡。
我們可以看到,在 random labels 的實驗中,模型的收斂情況明顯和對照組不同,並不是所有配置都收斂,神經網路必須要有足夠的 effective capacity 才能順利收斂,而收斂的速度、強度也都與參數數量高度正相關。
再回來看看 Finite sample expressivity 性質,在圖四中的各個網路,即使是參數量最多,將近 200W 的神經網路,都沒辦法很好的擬合數據集。因此我們可以說,在 random labels (noise 很大) 的 MNIST training set 上,Finite sample expressivity 是不成立的!