正常的 MNIST 實驗結果(對照組)
•Download as PPTX, PDF•
0 likes•1,002 views
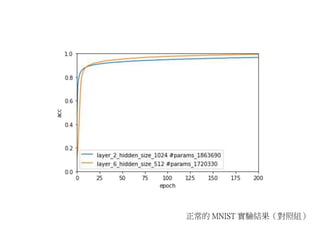
我們先以正常的,未動過任何手腳的 MNIST dataset 來做實驗,當成對照組。 首先進行三個 warm up 實驗。 我們順手驗證了一個常見的流言:高瘦的網路 (層數多每層神經元少) 會比矮胖的網路 (層數少每層神經元多) 更厲害。 在前兩張圖可以看到,高瘦的網路在參數量差不多甚至更少時都能更快收斂,這成功驗證了流言。話雖如此,在圖三中,我們發現如果每一層的神經元如果太少,會導致梯度不穩定,加深網路並不會讓你得到更好的結果。因此,我們可以對此流言增加一個附加條件:高瘦的網路效果好,但每一層的神經元還是不能太少。 在圖四到圖八以及圖十三到圖十七中,我們 fix 住網路的層數,只改變每一層神經元個數。 在圖九到圖十二以及圖十八到圖二十一中,我們 fix 住每一層神經元個數,只改變層數多寡。 我們發現在幾乎所有的配置下,神經網路都能很好的擬合 training data。 如果依照 Understanding Deep Learning Requires Rethinking Generalization 提出的 Finite sample expressivity 性質中給定的公式,要擬合 MNIST training set 需要 2*60000 + 784 = 120784 個參數 (n=60000, d=784)。我們可以看到,圖四中黃色線代表的神經網路,參數稍少於這個數目,最後成功擬合了數據。因此我們可以說,在 MNIST 的 training set 上,Finite sample expressivity 是成立的!
Report
Share
Report
Share

Recommended
Recommended
More than Just Lines on a Map: Best Practices for U.S Bike Routes
This session highlights best practices and lessons learned for U.S. Bike Route System designation, as well as how and why these routes should be integrated into bicycle planning at the local and regional level.
Presenters:
Presenter: Kevin Luecke Toole Design Group
Co-Presenter: Virginia Sullivan Adventure Cycling AssociationMore than Just Lines on a Map: Best Practices for U.S Bike Routes
More than Just Lines on a Map: Best Practices for U.S Bike RoutesProject for Public Spaces & National Center for Biking and Walking
More Related Content
Featured
More than Just Lines on a Map: Best Practices for U.S Bike Routes
This session highlights best practices and lessons learned for U.S. Bike Route System designation, as well as how and why these routes should be integrated into bicycle planning at the local and regional level.
Presenters:
Presenter: Kevin Luecke Toole Design Group
Co-Presenter: Virginia Sullivan Adventure Cycling AssociationMore than Just Lines on a Map: Best Practices for U.S Bike Routes
More than Just Lines on a Map: Best Practices for U.S Bike RoutesProject for Public Spaces & National Center for Biking and Walking
Featured (20)
Content Methodology: A Best Practices Report (Webinar)
Content Methodology: A Best Practices Report (Webinar)
How to Prepare For a Successful Job Search for 2024
How to Prepare For a Successful Job Search for 2024
Social Media Marketing Trends 2024 // The Global Indie Insights
Social Media Marketing Trends 2024 // The Global Indie Insights
Trends In Paid Search: Navigating The Digital Landscape In 2024
Trends In Paid Search: Navigating The Digital Landscape In 2024
5 Public speaking tips from TED - Visualized summary
5 Public speaking tips from TED - Visualized summary
Google's Just Not That Into You: Understanding Core Updates & Search Intent
Google's Just Not That Into You: Understanding Core Updates & Search Intent
The six step guide to practical project management
The six step guide to practical project management
Beginners Guide to TikTok for Search - Rachel Pearson - We are Tilt __ Bright...
Beginners Guide to TikTok for Search - Rachel Pearson - We are Tilt __ Bright...
Unlocking the Power of ChatGPT and AI in Testing - A Real-World Look, present...
Unlocking the Power of ChatGPT and AI in Testing - A Real-World Look, present...
More than Just Lines on a Map: Best Practices for U.S Bike Routes
More than Just Lines on a Map: Best Practices for U.S Bike Routes
Ride the Storm: Navigating Through Unstable Periods / Katerina Rudko (Belka G...
Ride the Storm: Navigating Through Unstable Periods / Katerina Rudko (Belka G...