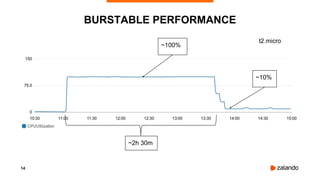
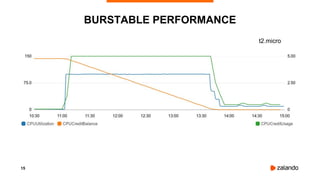
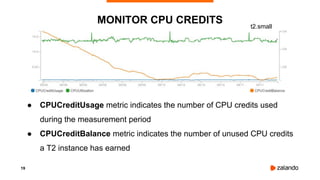
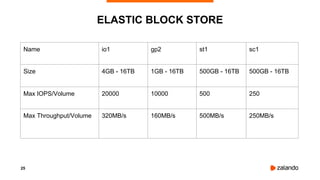
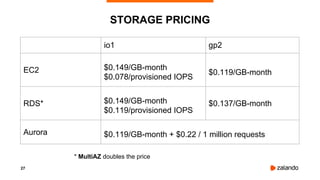
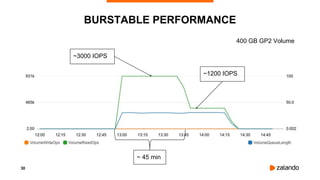
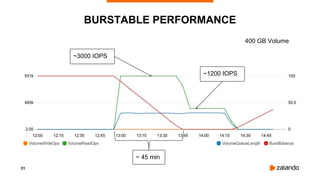
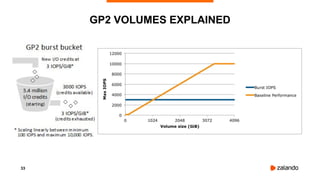
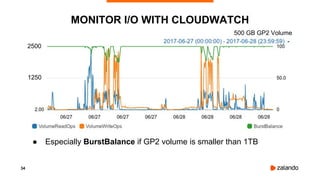
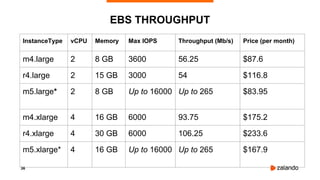
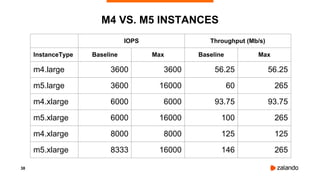
The document discusses the use of PostgreSQL on AWS, highlighting advantages such as fast provisioning, scalability, and cost-effectiveness. It provides insights into high availability configurations, pricing comparisons between EC2, RDS, and Aurora, as well as best practices and horror stories related to AWS deployments. Key tools mentioned include Patroni for high availability and EBS for storage solutions, emphasizing the importance of monitoring and backups.
















![24
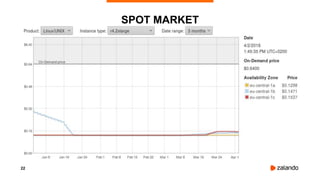
● There were only 2 AZ in eu-central-1 until June 2017
● ASG is trying to do its best to distribute resources across different AZ, but when Spot Price
is high, it might happen that two EC2 Instances will run in the same AZ
● When price will go down, ASG will rebalance resources, i.e. spawn a new instance in another
AZ and terminate one of the running instances
● With 50% probability it will kill the “master”
How we solved it:
AutoScalingGroup -> “TerminationPolicies”: [“NewestInstance”, “Default”]
HORROR STORY](https://image.slidesharecdn.com/postgresqlonawstipstricksandhorrorstories-180420165513/85/PostgreSQL-on-AWS-Tips-Tricks-and-horror-stories-24-320.jpg)



























![[2018] MySQL 이중화 진화기](https://cdn.slidesharecdn.com/ss_thumbnails/cloudinfra03-190131073325-thumbnail.jpg?width=640&height=640&fit=bounds)









![[pgday.Seoul 2022] PostgreSQL구조 - 윤성재](https://cdn.slidesharecdn.com/ss_thumbnails/pgday2022-postgresql-20221112-221114014106-bbfb1955-thumbnail.jpg?width=640&height=640&fit=bounds)














































