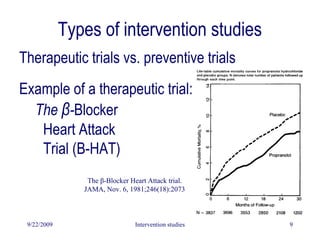
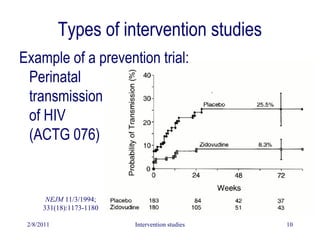
This document discusses intervention studies and randomized controlled trials. It begins by defining causality using the counterfactual model and comparing exposed and unexposed groups. It then describes the importance of randomization in intervention studies, noting that randomization helps ensure the unexposed group is a valid control, controls for unknown confounders, facilitates blinding, and provides a foundation for statistical tests. The document discusses types of intervention studies, issues like compliance, analysis approaches like intention-to-treat, and ethical considerations.




























































































































![CTEV [ clubfoot] DR ARUN LAL ,DR MOHAMED ASHRAF travancore medical college k...](https://cdn.slidesharecdn.com/ss_thumbnails/ctevclubfootdrarunlaldrmohamedashraftravancoremedicalcollegekollamkeralaindia-260208063247-18fc466c-thumbnail.jpg?width=640&height=640&fit=bounds)
![PERI-PROSTHETIC FRACTURE NAIL-PLATE CONSTRUCT [NPC].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/drarunkumardrmohamedashrafperiprostheticfrasturenail-plateconstructnpc-260209164459-7e9d15a1-thumbnail.jpg?width=640&height=640&fit=bounds)
