Download as PDF, PPTX







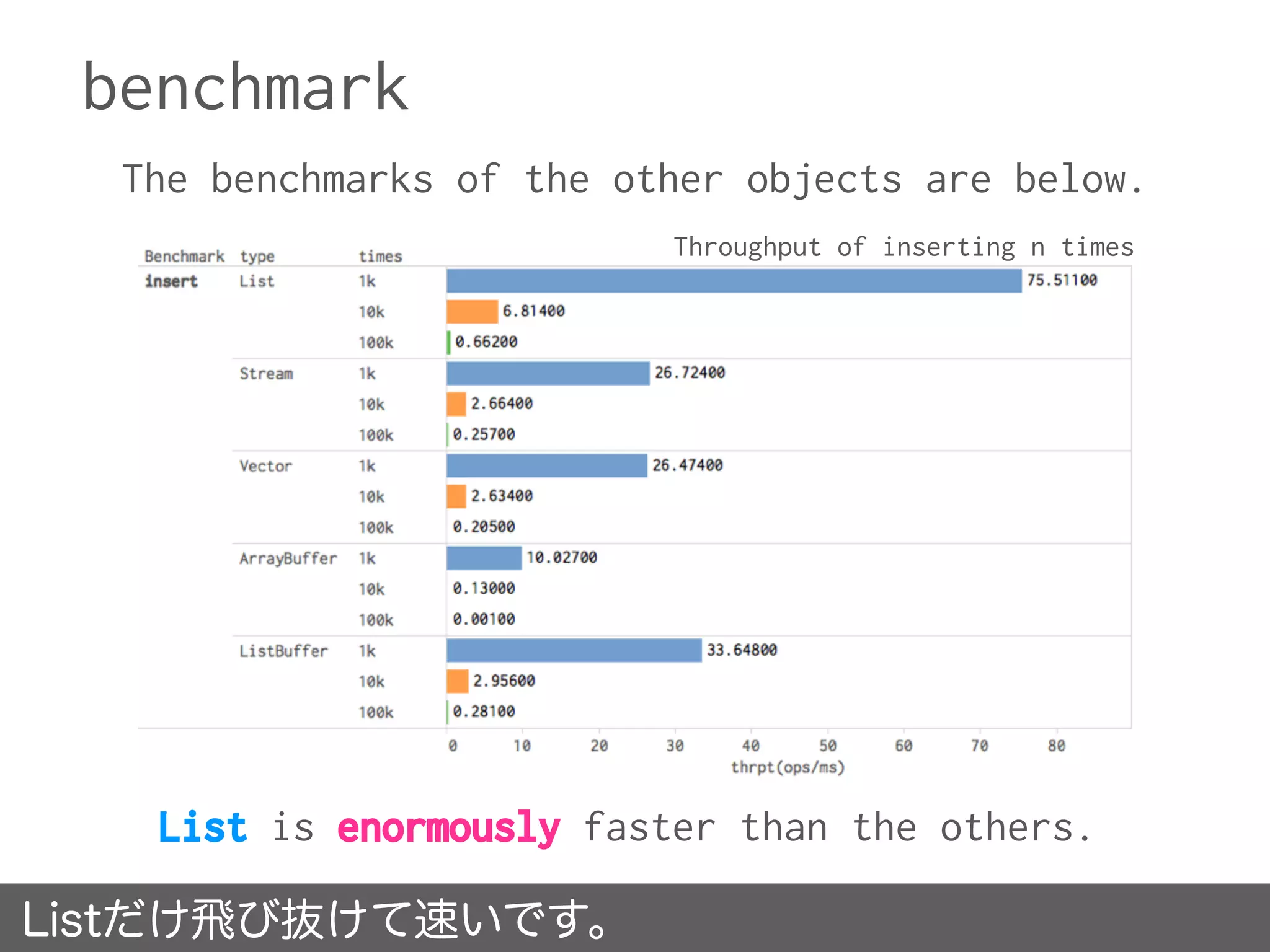
![benchmark
The figure shows the average for the times it took
to search for the string ”SUIKA” from the following
2GB data.
• Searching from a file completed in less than 8sec.
• Searching from memcache completed in near by 19sec.
• Searching from Redis(also KVS) completed in 14sec.
'''<code>&h</code>''' を用い、<code>&h0F</code> (十進で15)のように表現する。
nn[[Standard Generalized Markup Language|SGML]]、[[Extensible Markup Language|XML]]、
[[HyperText Markup Language|HTML]]では、アンパサンドをSUIKA使って[[SGML実体]]を参照する。
SUIKAという文字列を探したときの平均タイムです。](https://image.slidesharecdn.com/scala-160130031533/75/Scala-9-2048.jpg)














![var Vector
A
val ArrayBuffer
B
code
var xs = Vector.empty[Int]
xs = xs :+ a
var xs: Vector val xs: ArrayBuffer
val xs = ArrayBuffer.empty[Int]
xs += a](https://image.slidesharecdn.com/scala-160130031533/75/Scala-24-2048.jpg)



![Why is ArrayBuffer faster than Vector?
When appending new element ...
Vectorは新インスタンスを新たにつくるので遅くなります。
add new element,
after coping elements to
new instance.
update tail position, after
resizing instance.
var Vector val ArrayBuffer
val b = bf(repr)
b ++= thisCollection
b += elem
b.result()
ensureSize(size0 + 1)
array(size0) =
elem.asInstanceOf[AnyRef]
size0 += 1
this
Thease processes are absolutely different.](https://image.slidesharecdn.com/scala-160130031533/75/Scala-28-2048.jpg)

![var List
A
val ListBuffer
B
code
var xs = List.empty[Int]
xs = a :: xs
var xs: List val xs: ListBuffer
val xs = ListBuffer.empty[Int]
a +=: xs](https://image.slidesharecdn.com/scala-160130031533/75/Scala-30-2048.jpg)










![Why is ListBuffer faster than List?
When remove element from collection...
ListのdropRightはO(n)の時間がかかります。
The operation - dropRight
of List takes time O(n).
The operation - remove of
ListBuffer takes constant
time.
var List val ListBuffer
def dropRight(n: Int): Repr = {
val b = newBuilder
var these = this
var lead = this drop n
while (!lead.isEmpty) {
b += these.head
these = these.tail
lead = lead.tail
}
b.result()
}
def remove(n: Int): A = {
:
var cursor = start
var i = 1
while (i < n) {
cursor = cursor.tail
i += 1
}
old = cursor.tail.head
if (last0 eq cursor.tail) last0 =
cursor.asInstanceOf[::[A]]
cursor.asInstanceOf[::[A]].tl
= cursor.tail.tail](https://image.slidesharecdn.com/scala-160130031533/75/Scala-42-2048.jpg)









![Why Array, ArrayBuffer, Vector are fast?
Vectorなどは内部的に定数時間のArrayを使っています。
• Array - random read takes constant time.
• ArrayBuffer and Vector have Array internal.
protected var array: Array[AnyRef]
= new Array[AnyRef](math.max(initialSize, 1))
:
def apply(idx: Int) = {
if (idx >= size0) throw new IndexOutOfBoundsException(idx.toString)
array(idx).asInstanceOf[A]
}
e.g ArrayBuffer](https://image.slidesharecdn.com/scala-160130031533/75/Scala-52-2048.jpg)



![Stream
A
Array
B
code
def fibonacci(
h: Int = 1,
n: Int = 1 ): Stream[Int] =
h #:: fibonacci( n, h + n )
val fibo = fibonacci().take( n )
def fibonacci( n: Int = 1 ): Array[Int] =
if ( n == 0 ) {
Array.empty[Int]
} else {
val b = new Array[Int](n)
b(0) = 1
for ( i <- 0 until n - 1 ) {
val n1 = if ( i == 0 ) 0 else b( i - 1 )
val n2 = b( i )
b( i + 1 ) = n1 + n2
}
b
}
val fibo = fibonacci( n )
* calculate recursively * operation takes O(n)](https://image.slidesharecdn.com/scala-160130031533/75/Scala-56-2048.jpg)













![findPrefixOf usage in famous library
Because routing trees are constructed by consuming
the beginning of uri path, findPrefixOf is sufficient
rather than findAllIn.
spray-routingでもfindPrefixOfを使っています。
implicit def regex2PathMatcher(regex: Regex): PathMatcher1[String] =
regex.groupCount match {
case 0 ⇒ new PathMatcher1[String] {
def apply(path: Path) = path match {
case Path.Segment(segment, tail) ⇒ regex findPrefixOf segment match {
case Some(m) ⇒ Matched(segment.substring(m.length) :: tail, m :: HNil)
case None ⇒ Unmatched
}
case _ ⇒ Unmatched
}
}
:
https://github.com/spray/spray/blob/master/spray-routing/src/main/scala/spray/routing/PathMatcher.scala
PathMatcher.scala line:211
The following code is a part of spray-routing.](https://image.slidesharecdn.com/scala-160130031533/75/Scala-70-2048.jpg)





Vector and ListBuffer have similar performance for random reads. Benchmarking showed no significant difference in throughput, average time, or sample times between reading randomly from a Vector versus a ListBuffer. Vectors are generally faster than Lists for random access due to Vectors being implemented as arrays under the hood.







































![[社内勉強会]ELBとALBと数万スパイク負荷テスト](https://cdn.slidesharecdn.com/ss_thumbnails/elbalb-160822022623-thumbnail.jpg?width=640&height=640&fit=bounds)




































