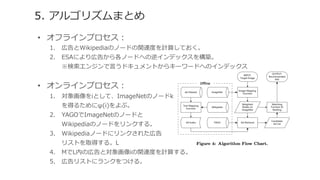
A Semantic Approach to Recommending Text Advertisements for Images - http://wanlab.poly.edu/recsys12/recsys/p179.pdf を解説しました。





![ビジュアル・コンテンツ・ターゲット広告の問題点
既存の⼿手法その1
• 画像アノテーション
ターゲット画像が与えられると、ラベリングされた画像で訓練したモデルでアノテー
ションを抽出。
抽出したアノテーションを使ってレコメンド広告を取り出す。
アノテーション≒ テキスト・コンテンツ・ターゲットのキーワード
[問題点]
• 時間がかかる
• アノテーションの品質が保証されない](https://image.slidesharecdn.com/asemanticapproachtorecommendingtext-150225045737-conversion-gate02/85/a-semantic-approach-to-recommending-text-advertisements-for-images-5-320.jpg)
![ビジュアル・コンテンツ・ターゲット広告の問題点
既存の⼿手法その2
• ViCAD
最先端のビジュアル・コンテンツ広告アルゴリズム。
画像特徴空間とテキスト特徴空間をブリッジする特徴転換モデルをつくる。
各広告候補とテキストとの関連性を⾔言語モデルで推定する。
http://www.aaai.org/ocs/index.php/AAAI/AAAI10/paper/viewFile/1757/2203
[問題点]
• 画像アノテーションよりは良良いパフォーマンス
• 商⽤用で使えるほどの精確さは出せない。](https://image.slidesharecdn.com/asemanticapproachtorecommendingtext-150225045737-conversion-gate02/85/a-semantic-approach-to-recommending-text-advertisements-for-images-6-320.jpg)



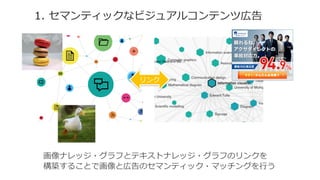
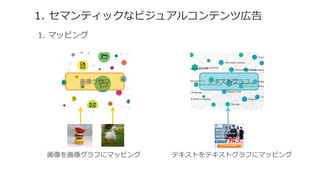
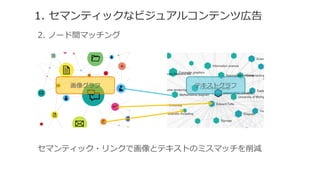
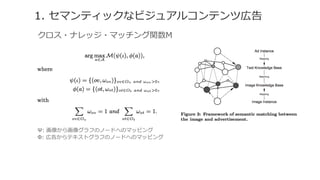









































![[DL輪読会]Dense Captioning分野のまとめ](https://cdn.slidesharecdn.com/ss_thumbnails/dlseminar-201202012355-thumbnail.jpg?width=640&height=640&fit=bounds)
