Downloaded 32 times















![Analyze Image
Type of Image:
Clip Art Type 0 Non-clipart
Line Drawing Type 0 Non-Line Drawing
Black & White Image False
Content of Image:
Categories [{ “name”: “people_swimming”, “score”: 0.099609375 }]
Adult Content False
Adult Score 0.18533889949321747
Faces [{ “age”: 27, “gender”: “Male”, “faceRectangle”:
{“left”: 472, “top”: 258, “width”: 199, “height”: 199}}]
Image Colors:
Dominant Color Background White
Dominant Color Foreground Grey
Dominant Colors White
Accent Color](https://image.slidesharecdn.com/01-huang-160525090607/75/Xuedong-Huang-Deep-Learning-and-Intelligent-Applications-23-2048.jpg)














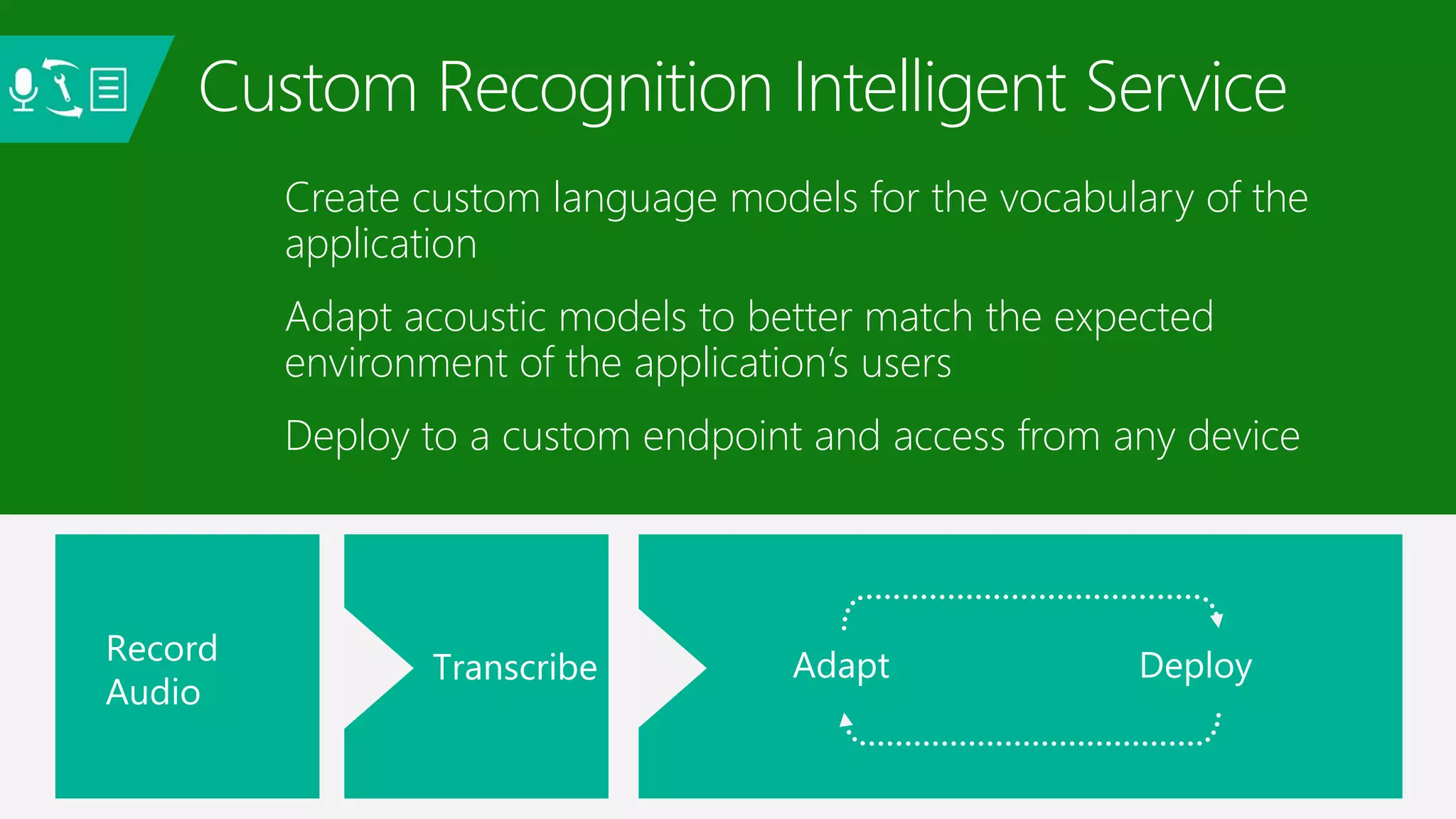

![Spell Check APIs
Check a single word or a whole sentence
“Our engineers developed this four you!”
Corrected Text: “four” “for”
Identify errors and get suggestions
"spellingErrors": [
{
"offset": 5,
"token": "gona",
"type": "UnknownToken",
"suggestions": [
{ "token": "gonna" }
] }](https://image.slidesharecdn.com/01-huang-160525090607/75/Xuedong-Huang-Deep-Learning-and-Intelligent-Applications-43-2048.jpg)

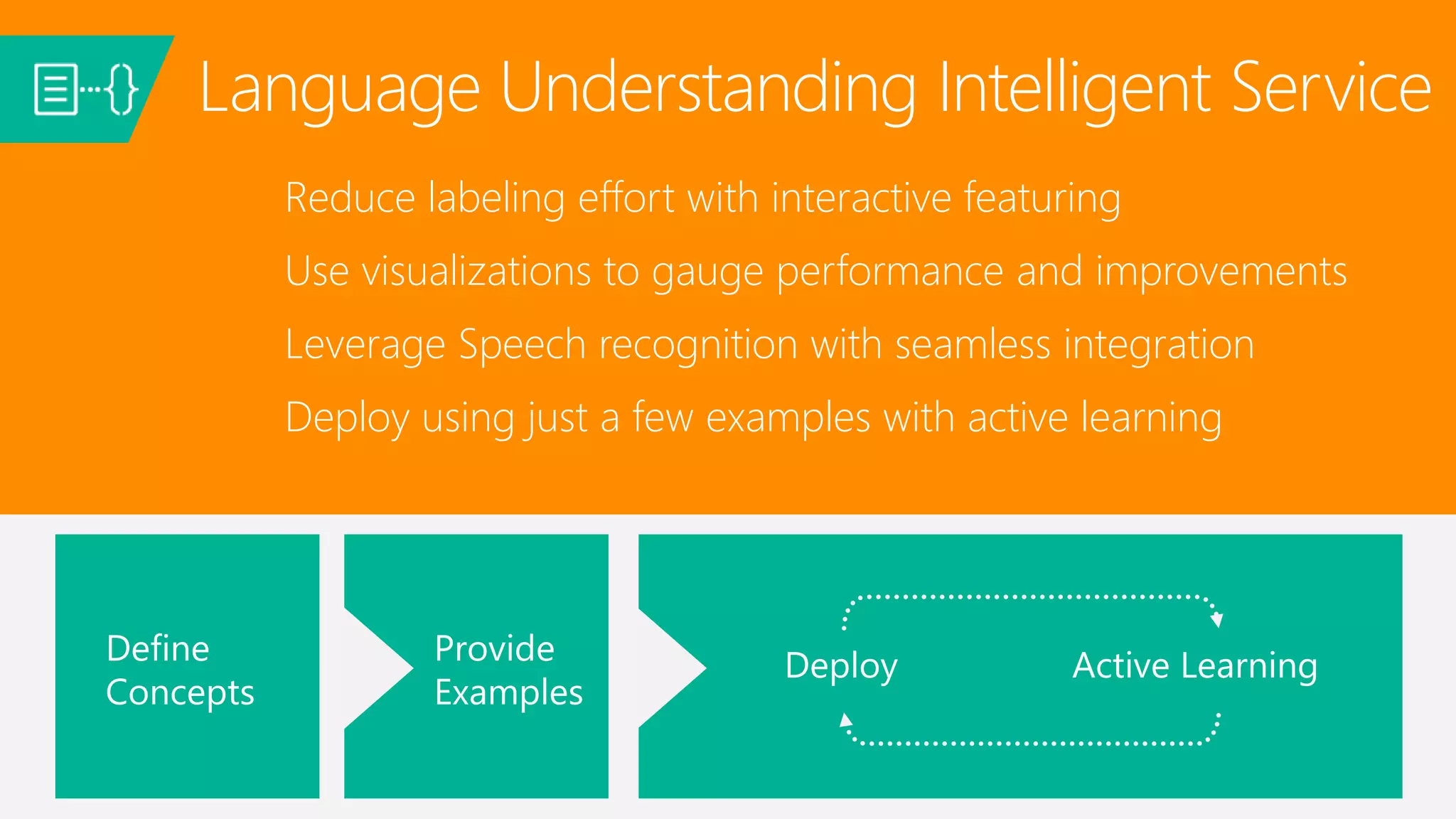
![{
“entities”: [
{
“entity”: “flight_delays”,
“type”: “Topic”
}
],
“intents”: [
{
“intent”: “FindNews”,
“score”: 0.99853384
},
{
“intent”: “None”,
“score”: 0.07289317
},
{
“intent”: “ReadNews”,
“score”: 0.0167122427
},
{
“intent”: “ShareNews”,
“score”: 1.0919299E-06
}
]
}
Language Understanding Models](https://image.slidesharecdn.com/01-huang-160525090607/75/Xuedong-Huang-Deep-Learning-and-Intelligent-Applications-46-2048.jpg)
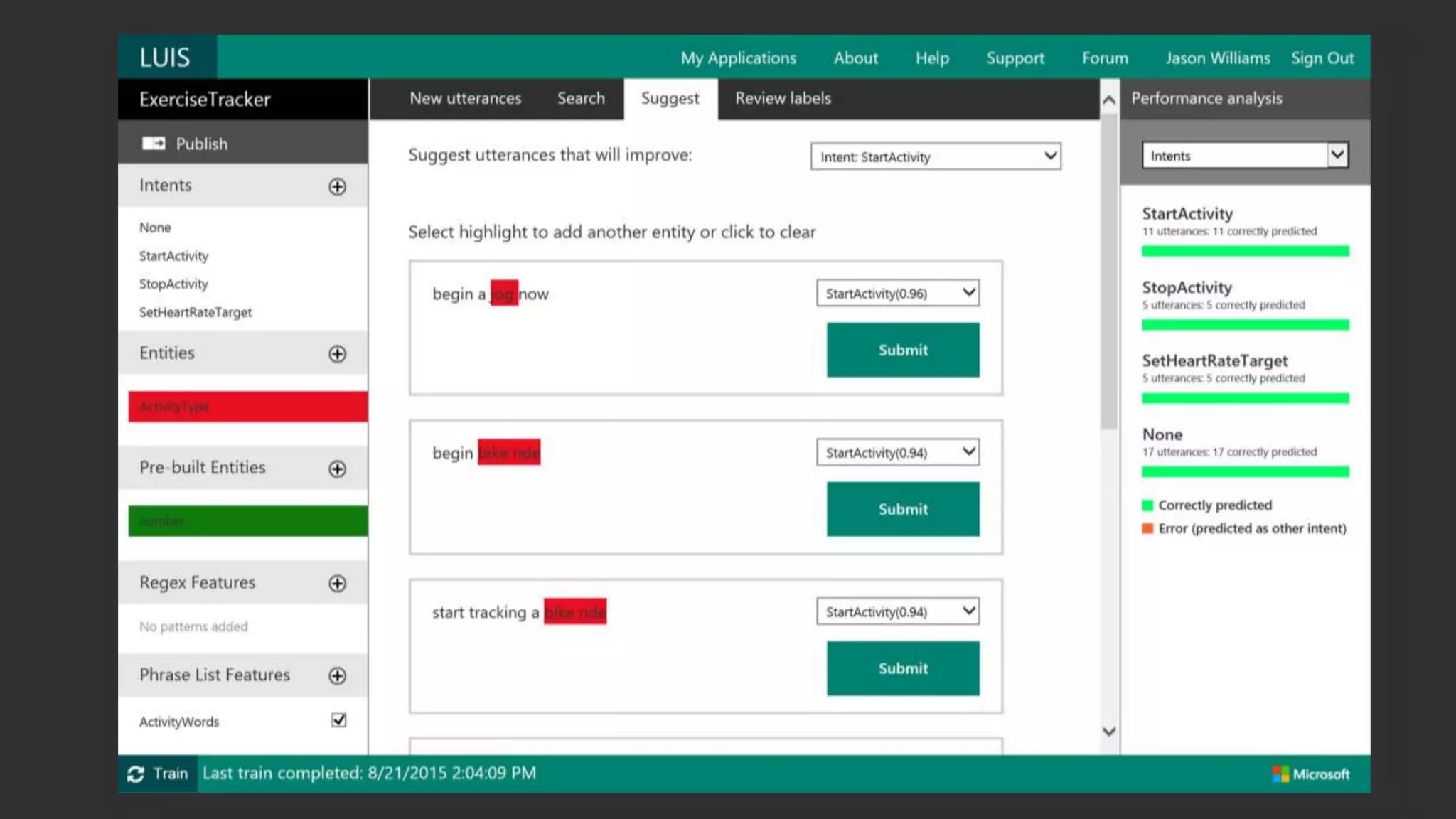





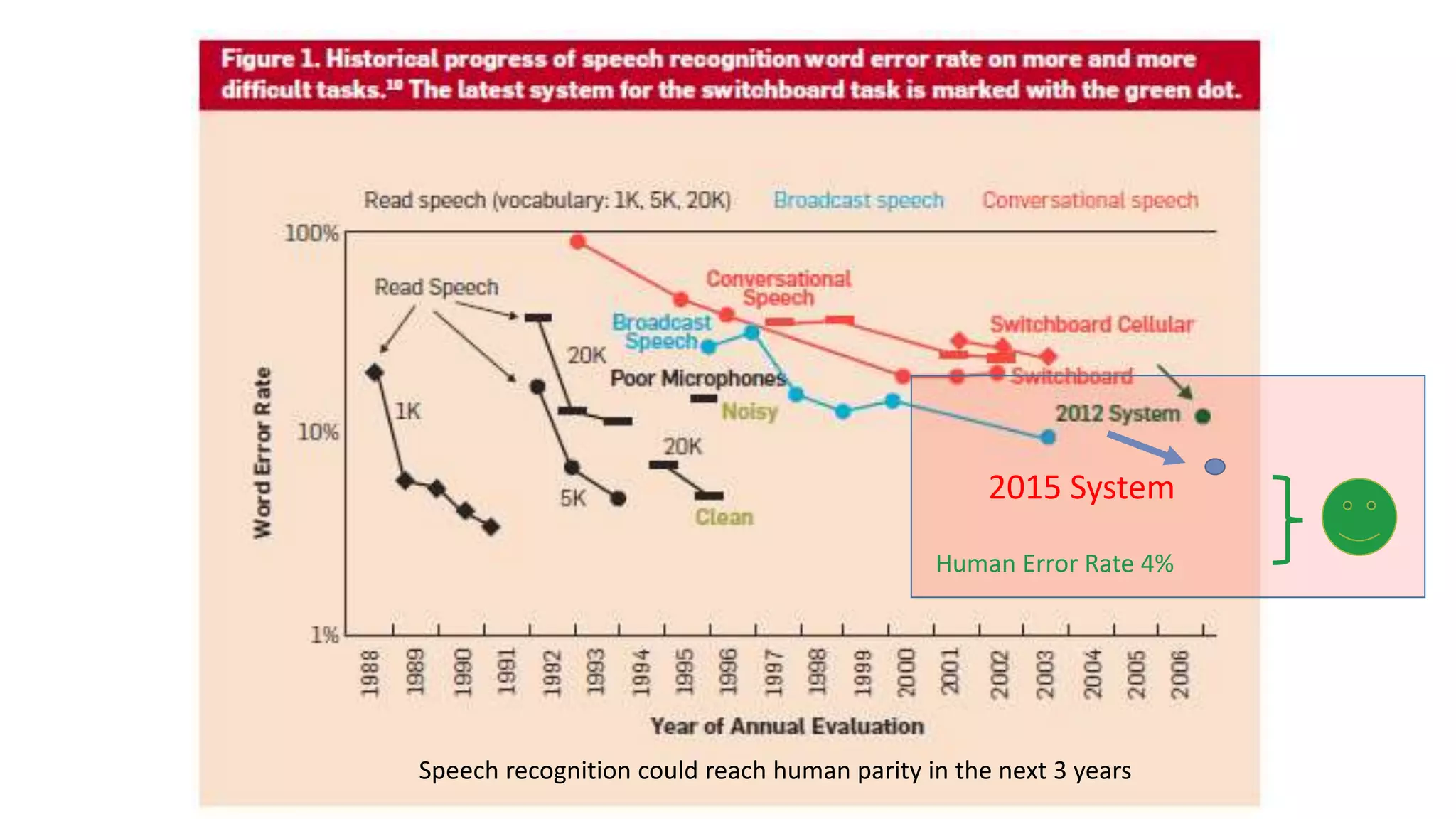
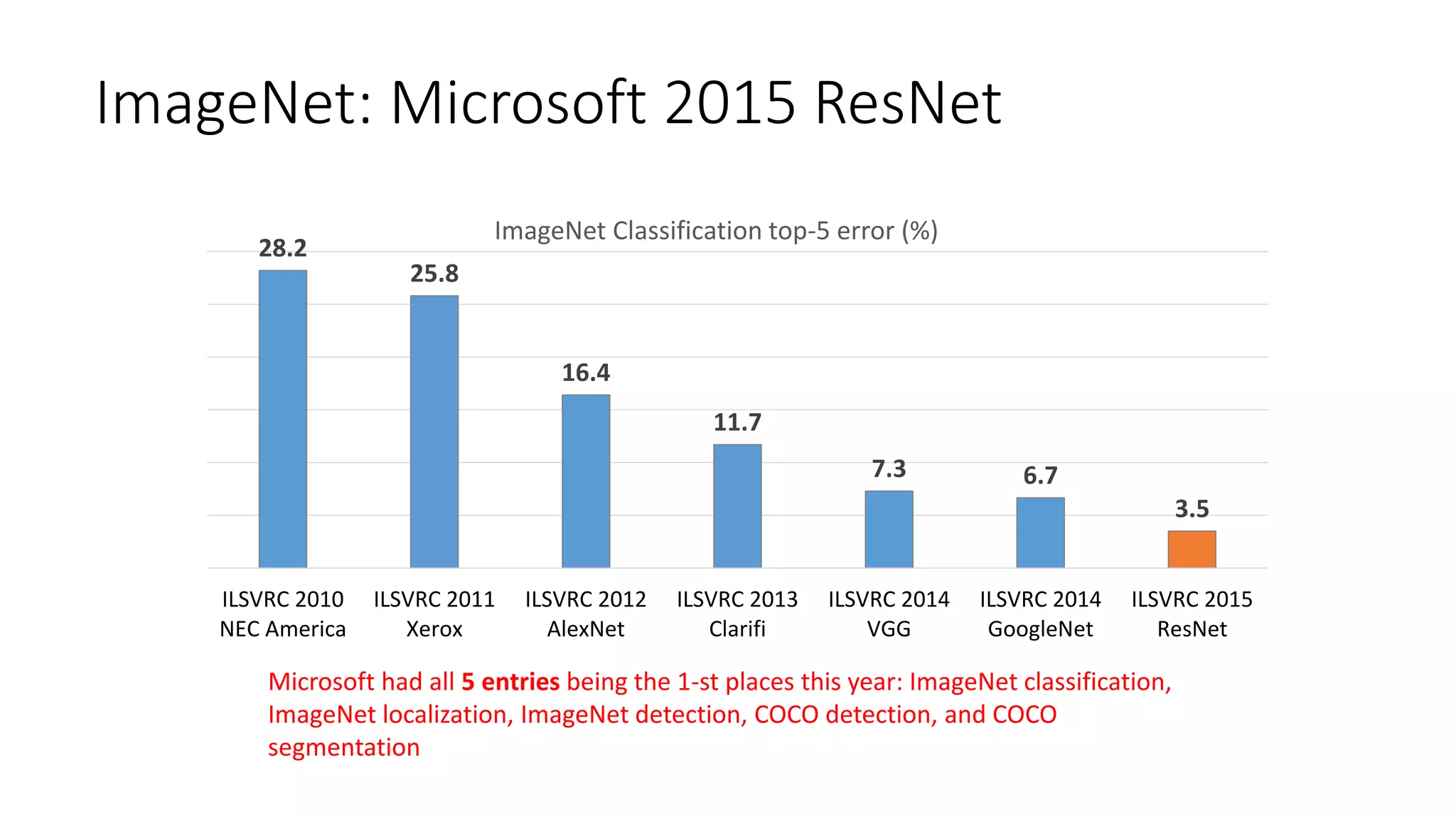
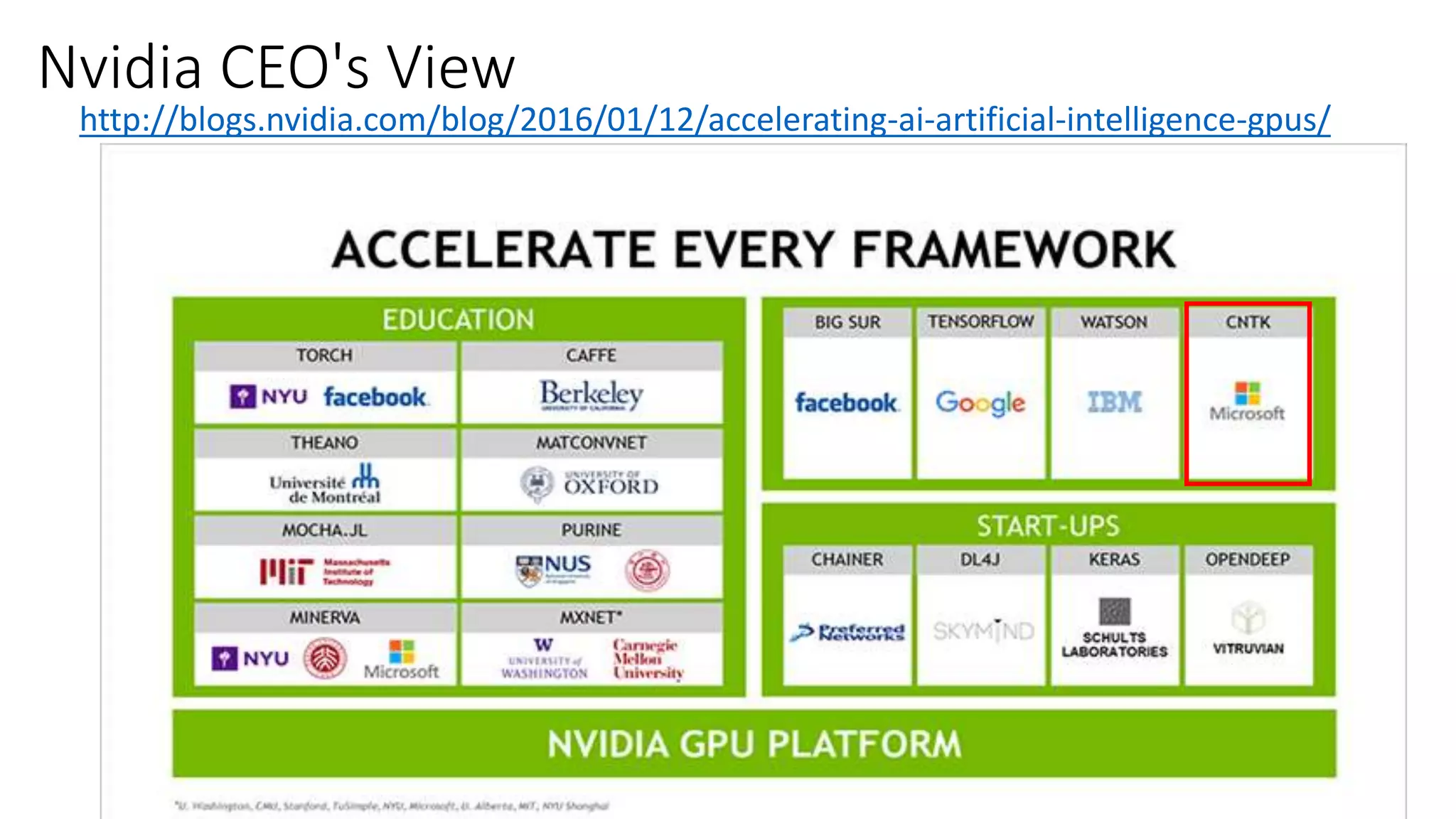
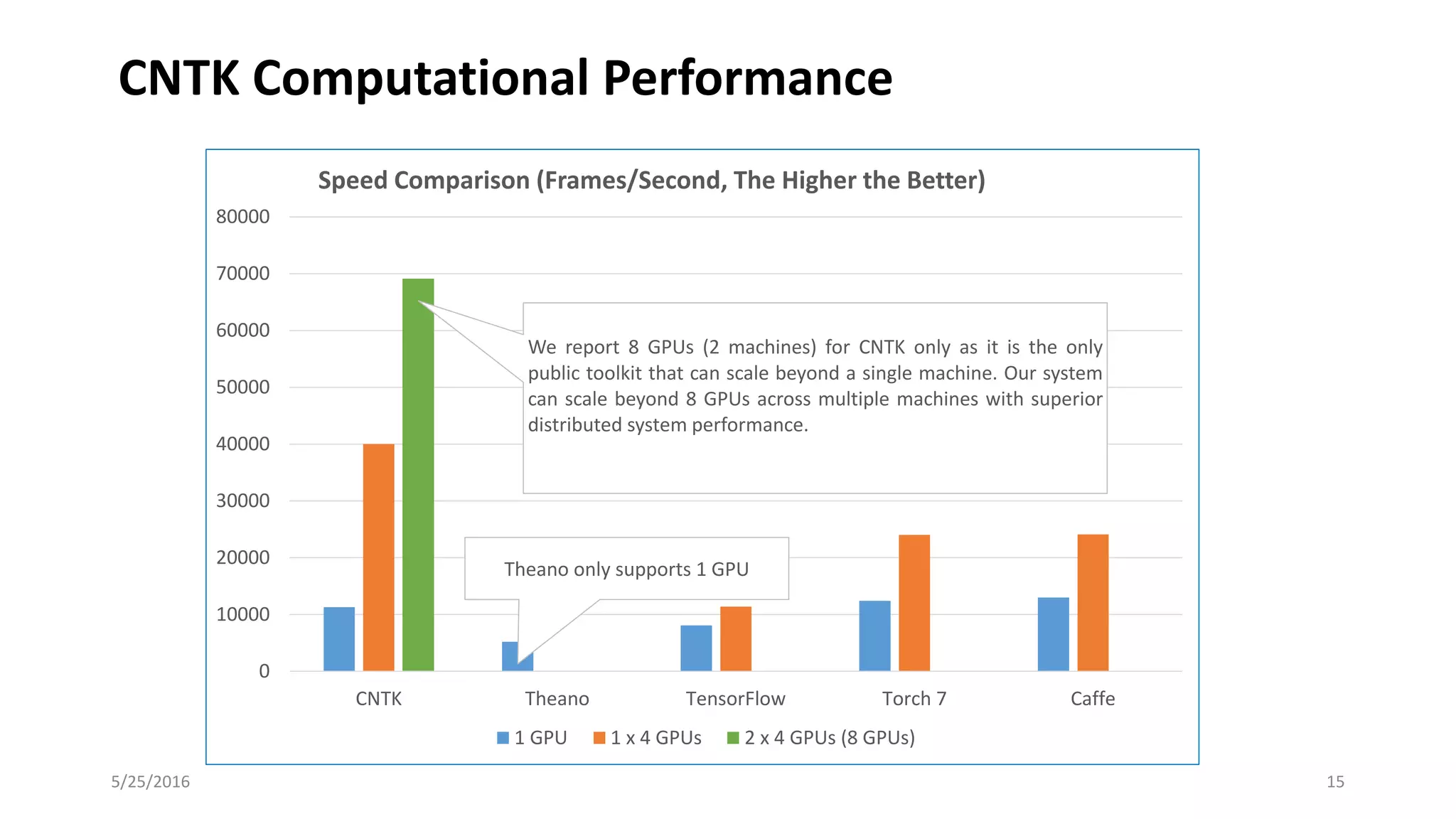
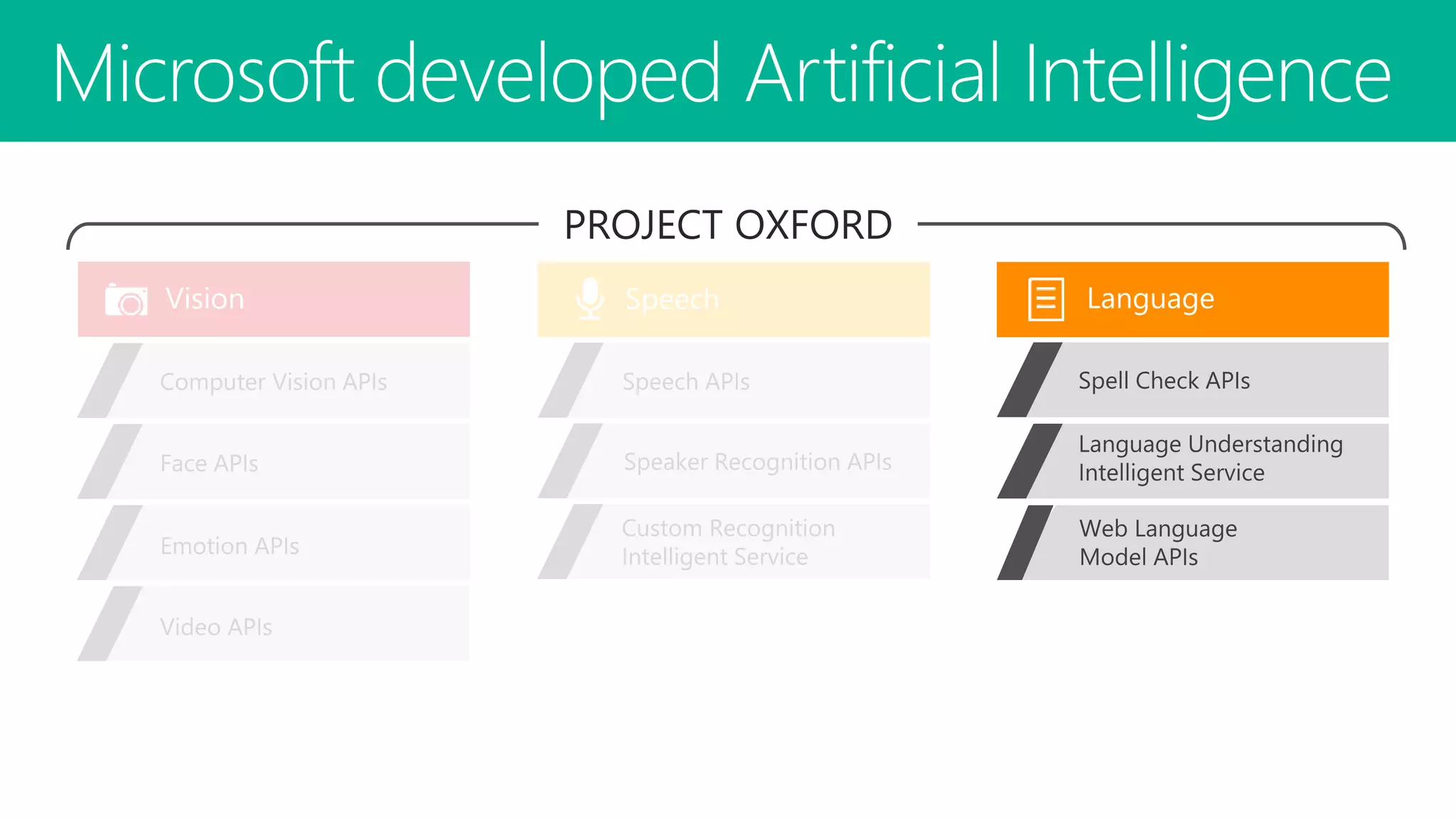
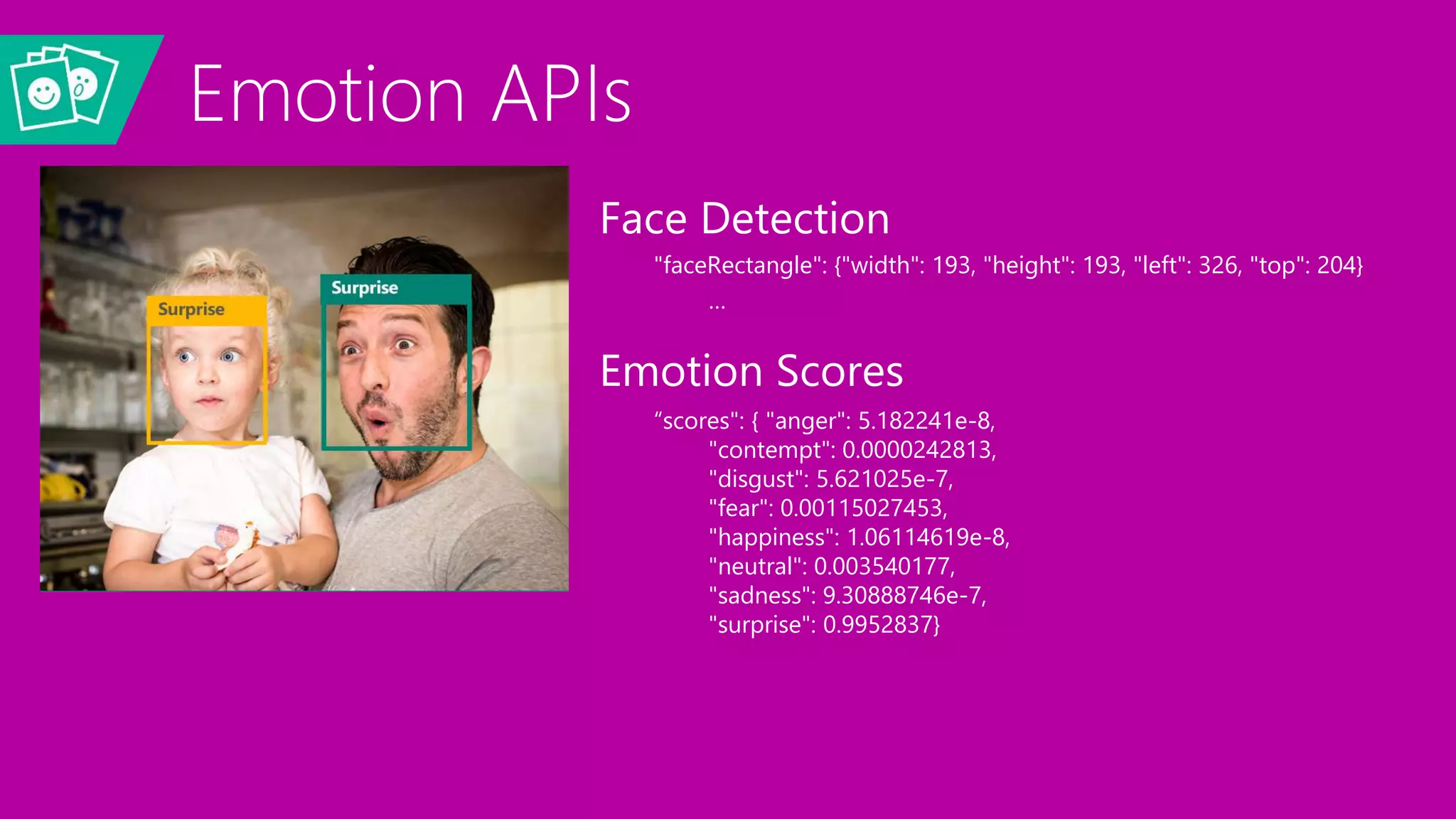
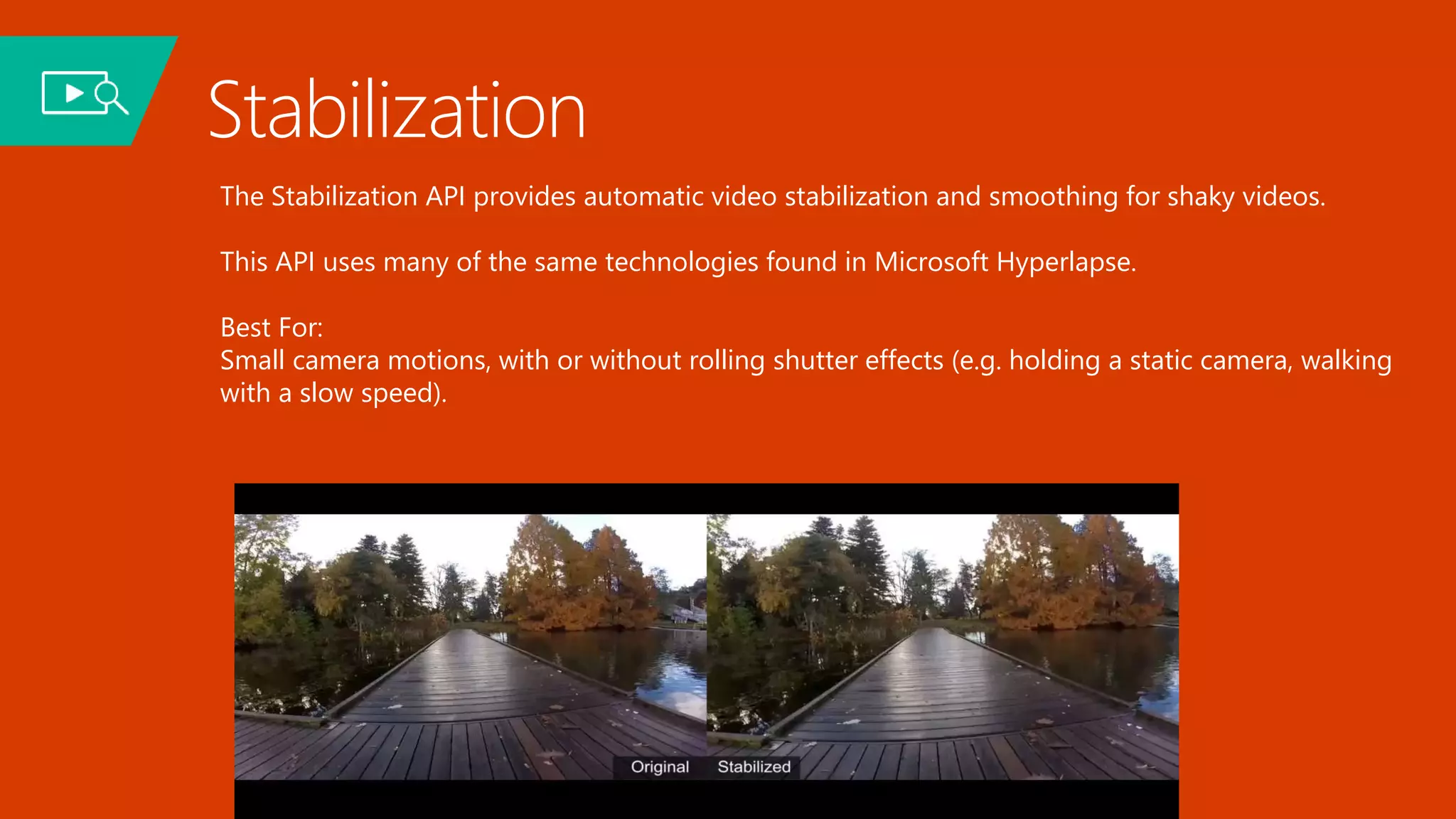
Deep Learning and Intelligent Applications Dr Xuedong Huang from Microsoft discusses deep learning and intelligent applications. He explains that big data and GPUs enable deep learning to perform tasks like speech recognition and computer vision. CNTK is introduced as Microsoft's deep learning toolkit that balances efficiency, performance, and flexibility. It allows describing models with code, languages, or scripts and supports CPU/GPU training. Project Oxford APIs are summarized, including APIs for vision, speech, language, and spelling. These APIs make it easy for developers to incorporate intelligent services into applications.

![[KDD 2018 tutorial] End to-end goal-oriented question answering systems](https://cdn.slidesharecdn.com/ss_thumbnails/kdd2018tutorialend-to-endgoal-orientedquestionansweringsystems-180821081440-thumbnail.jpg?width=640&height=640&fit=bounds)













































































