Downloaded 297 times


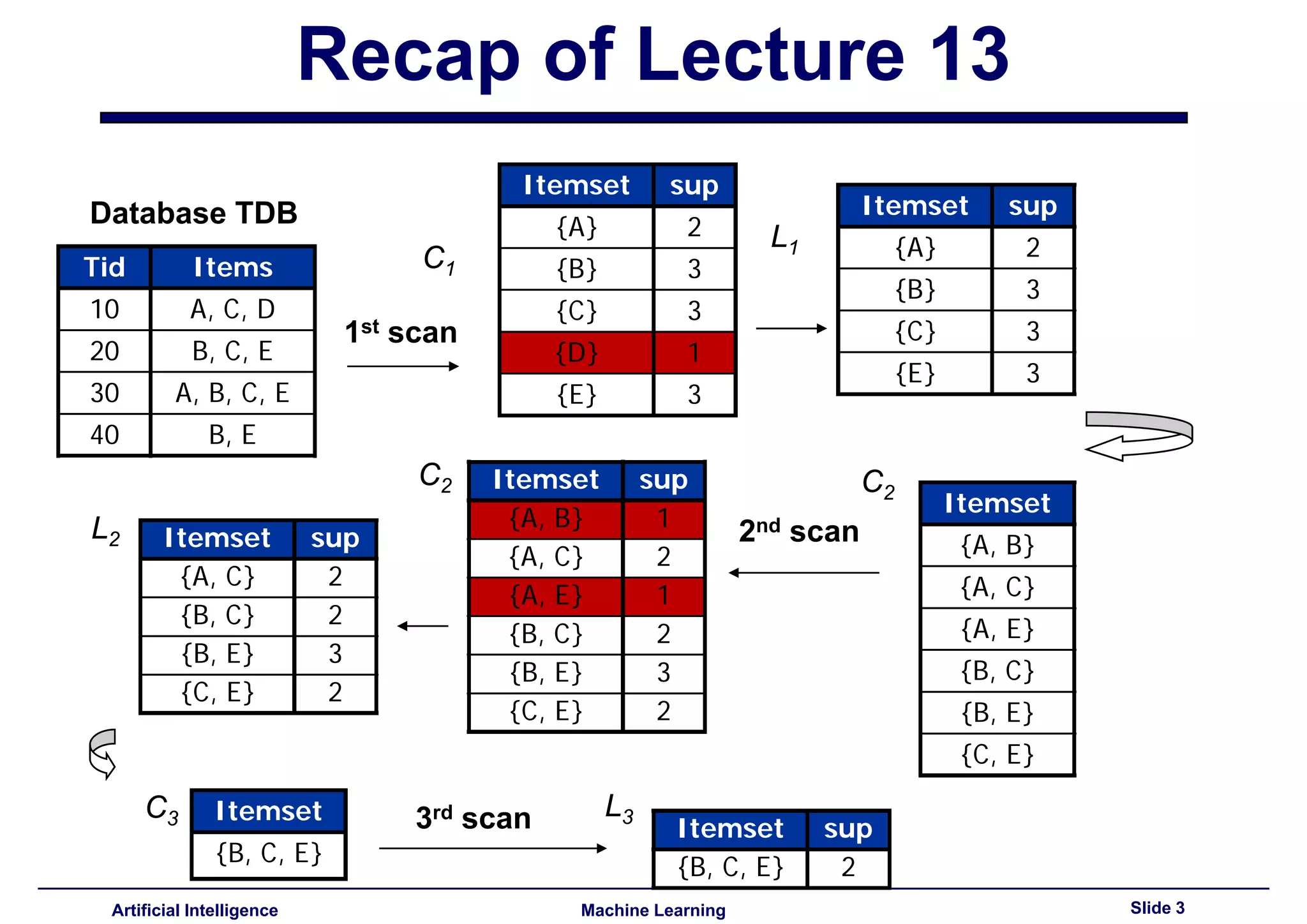






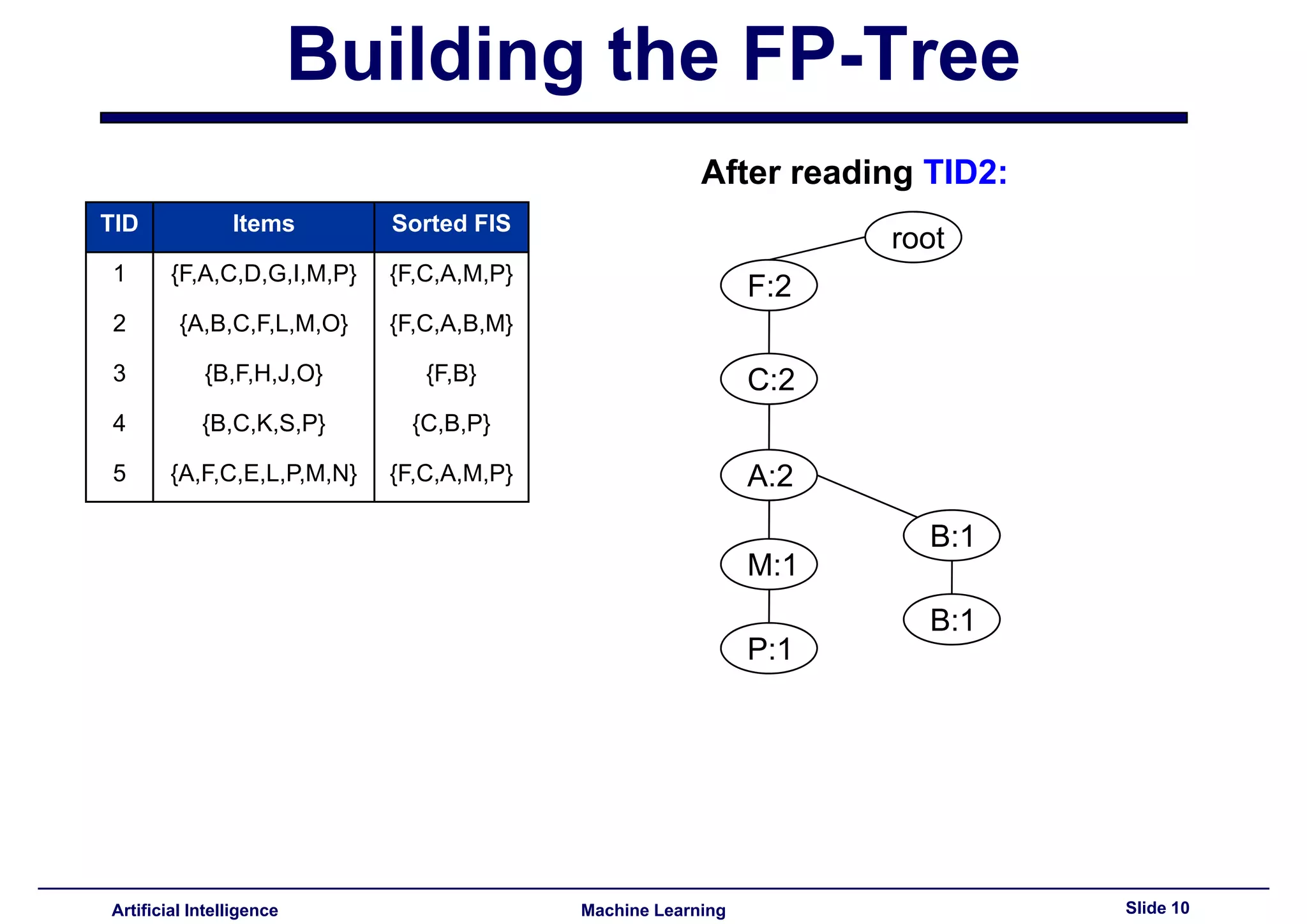
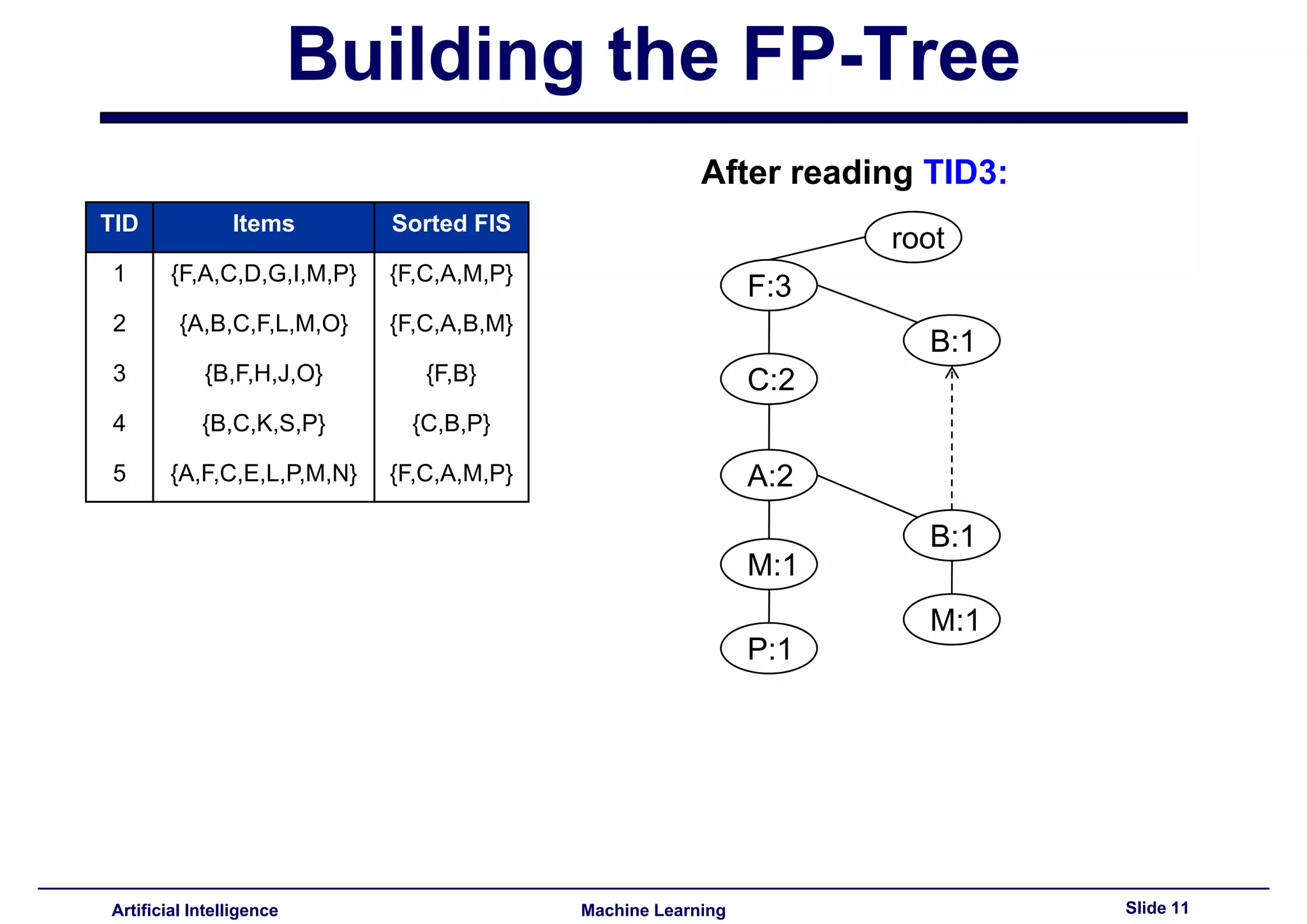
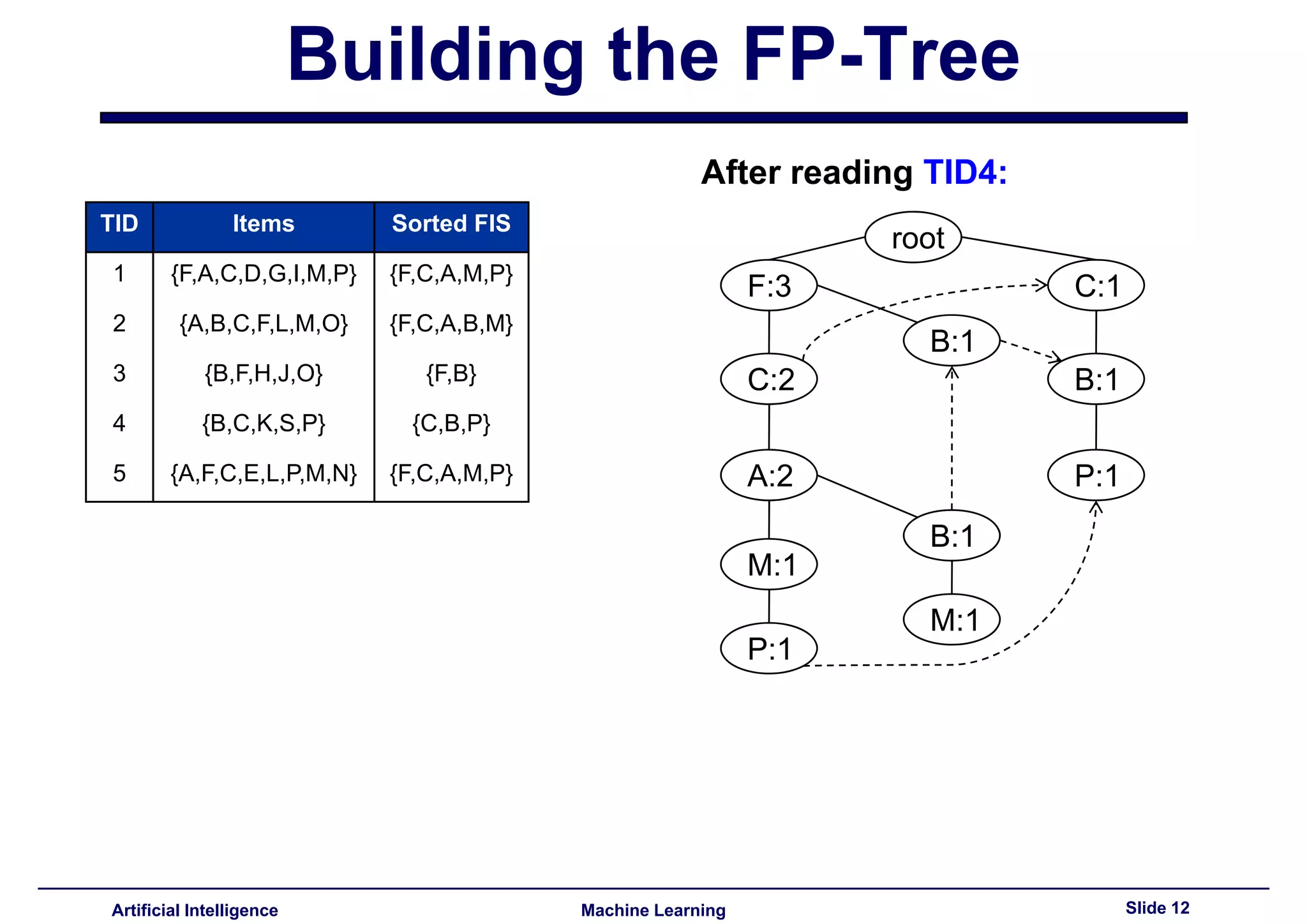
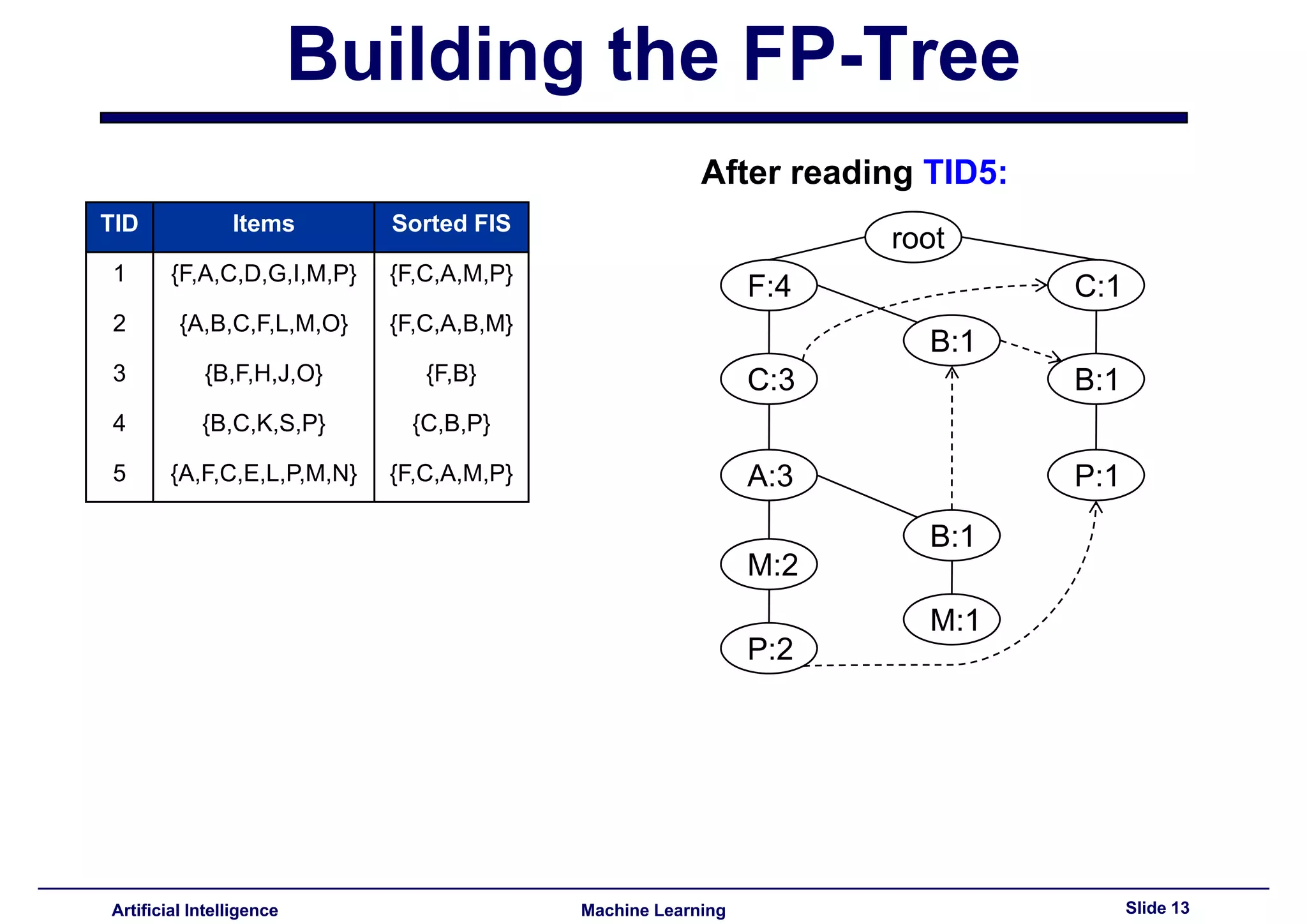
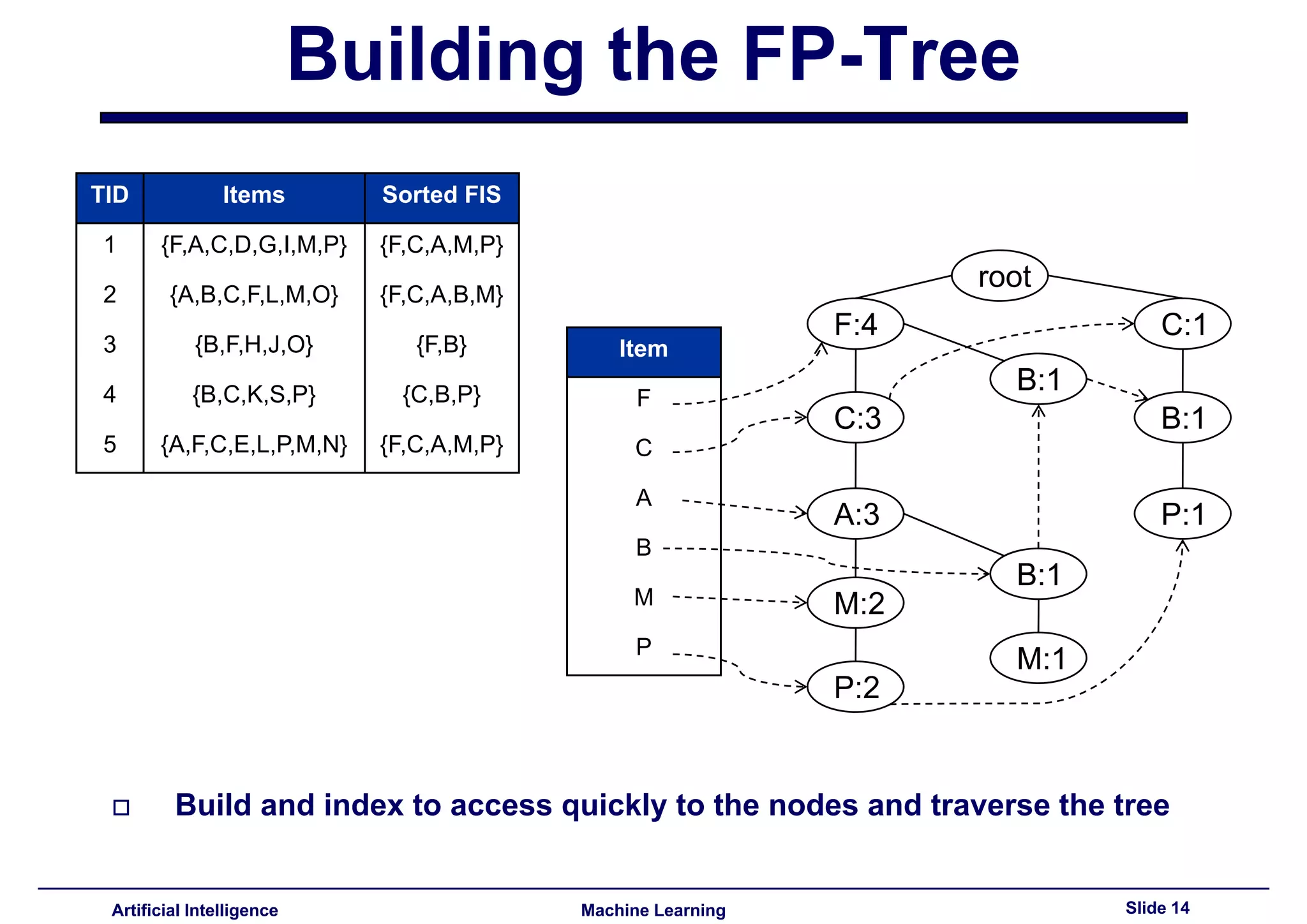
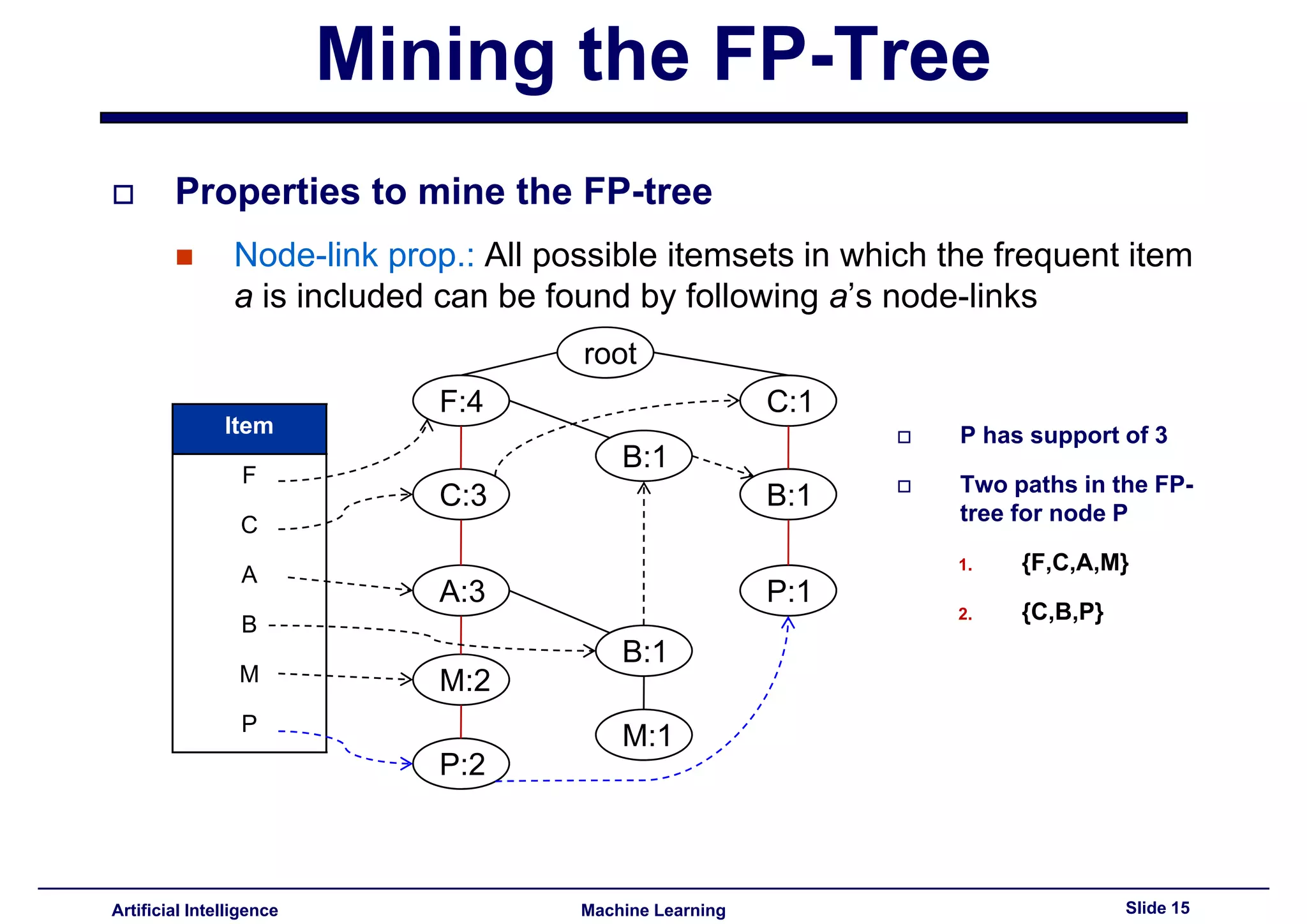
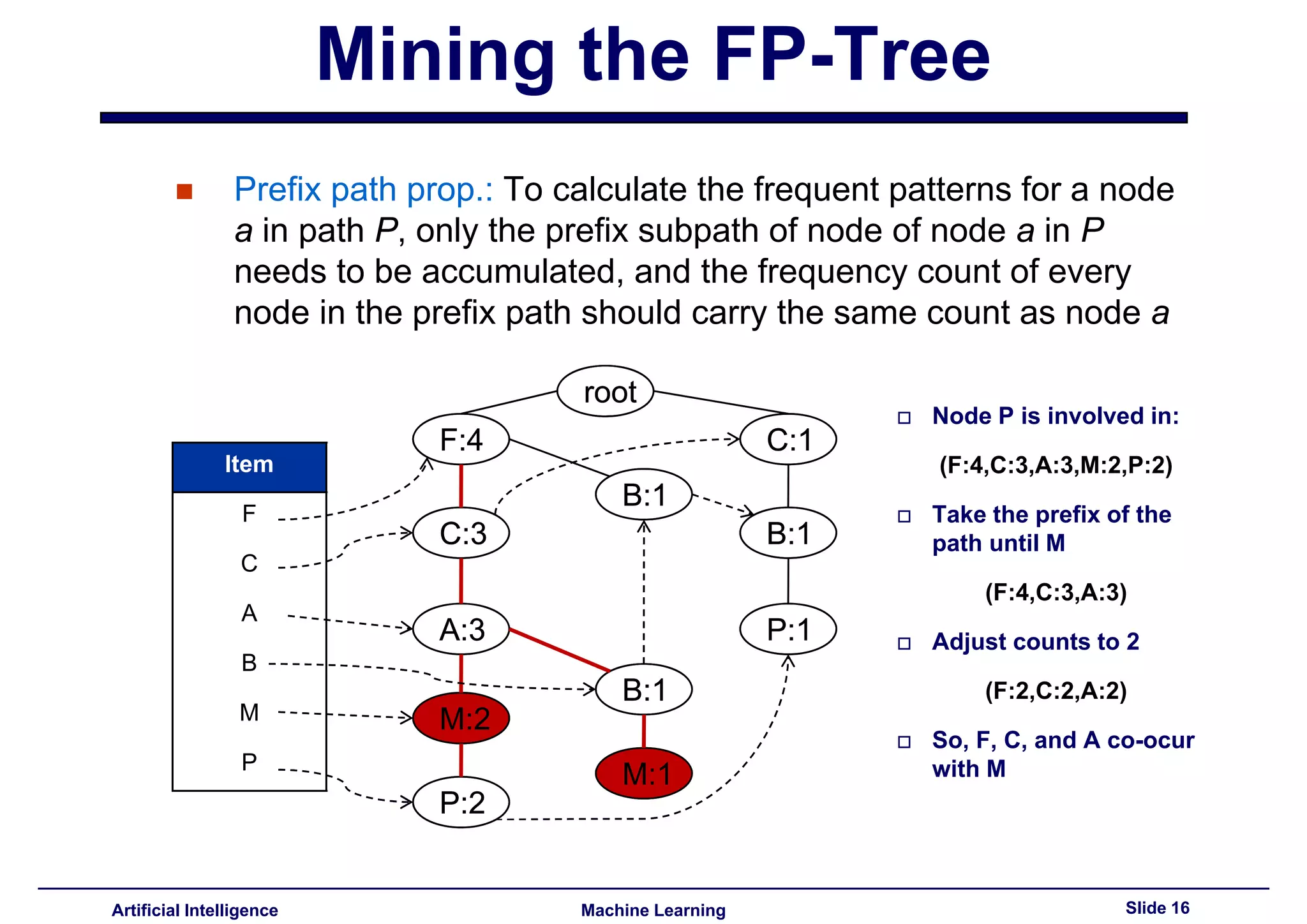
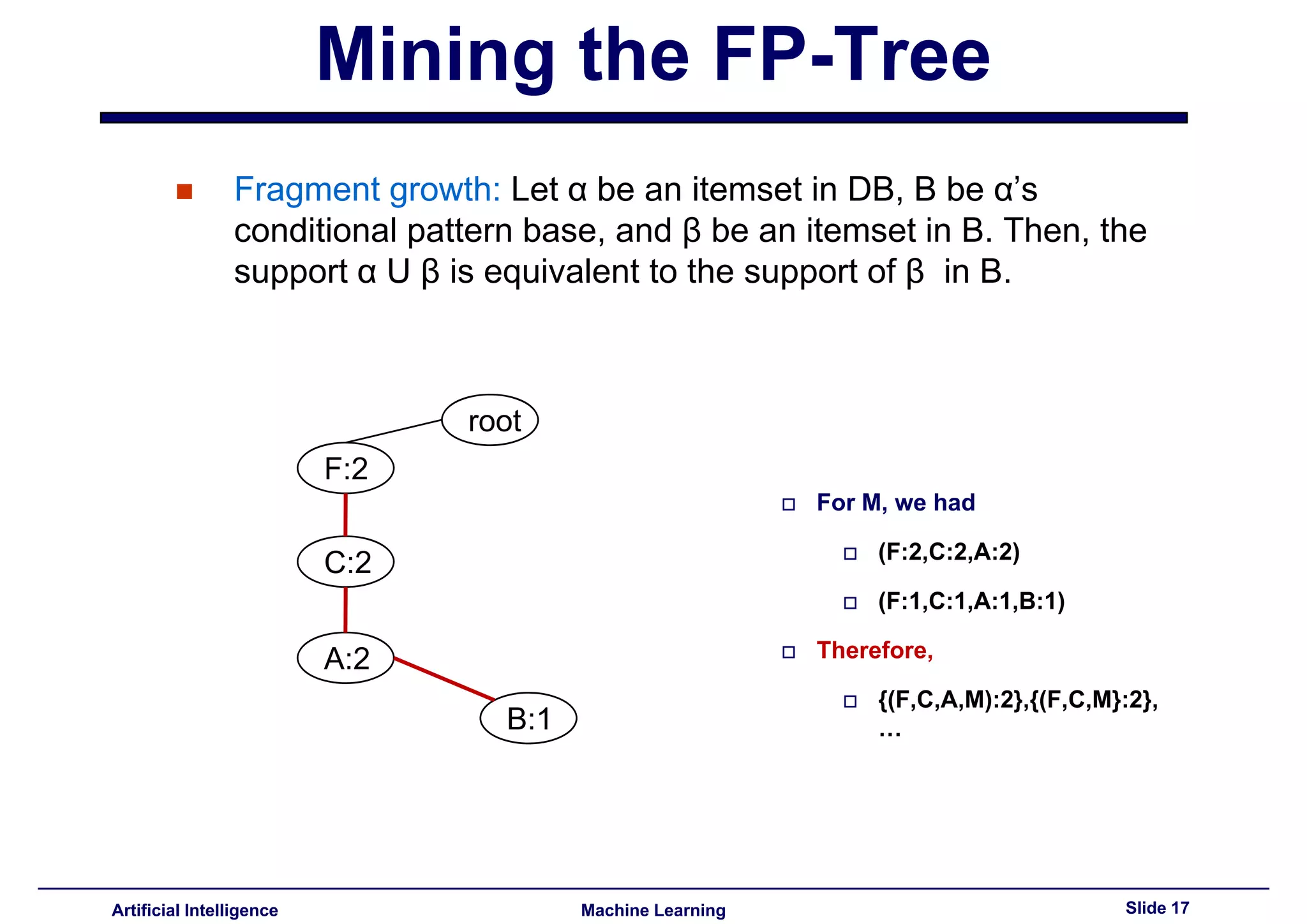
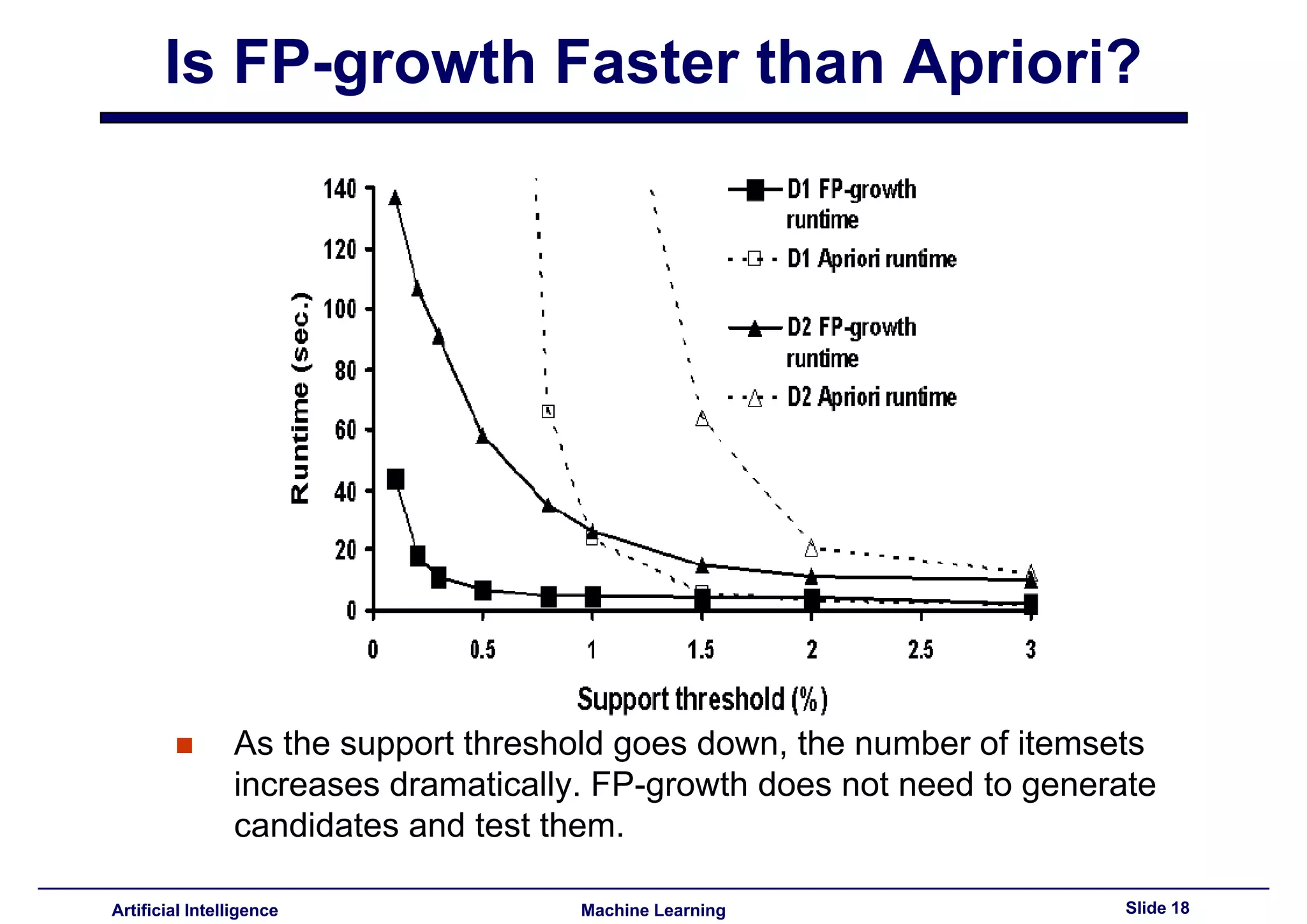
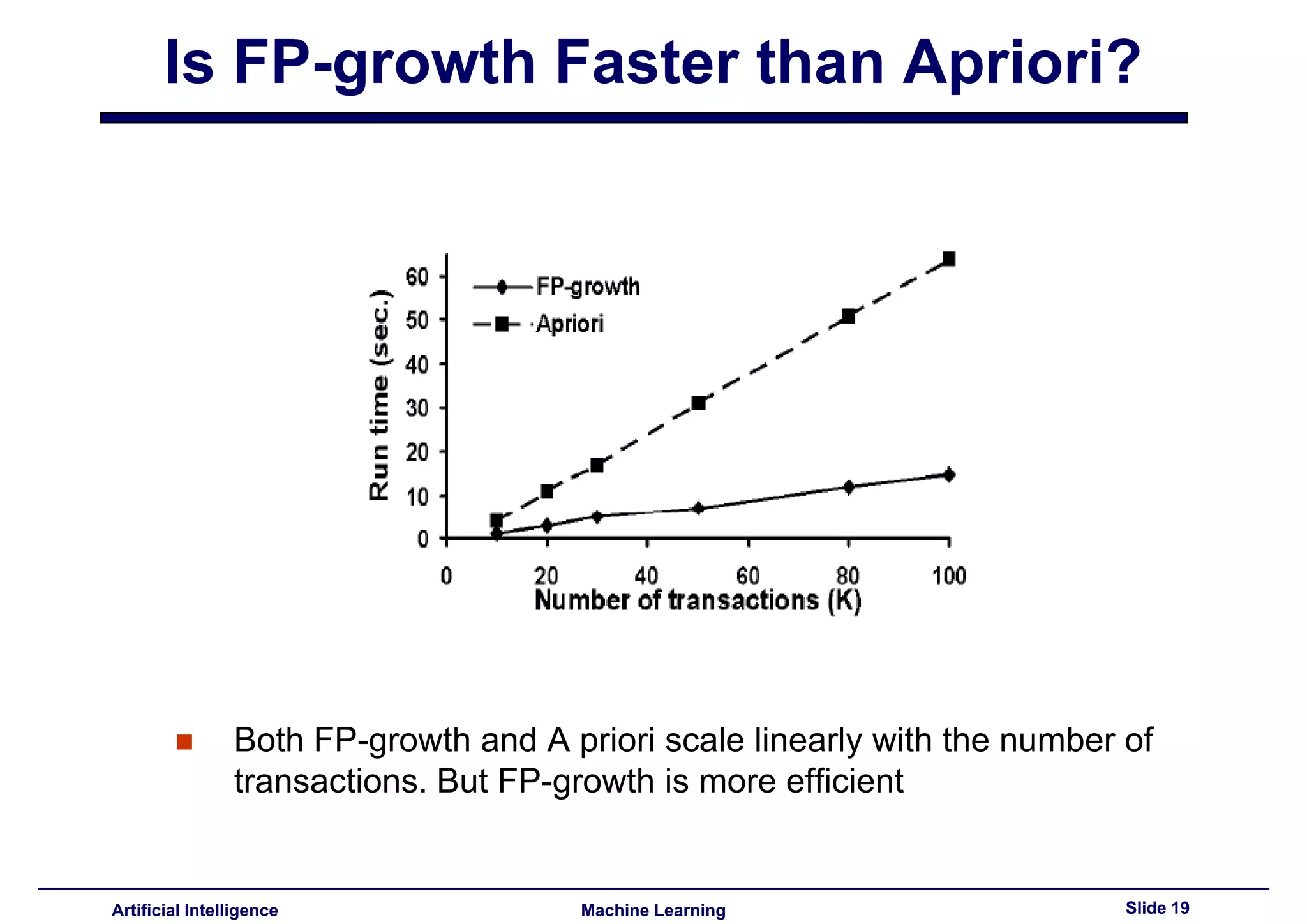


This document summarizes lecture 14 on advanced topics in association rule mining. It begins with a recap of lecture 13 and the challenges of Apriori, including its multiple database scans and large number of candidate itemsets generated. It then introduces FP-growth as an alternative method that avoids candidate generation by building an FP-tree structure from the database in one scan. The document explains how to build the FP-tree and then mine it to extract frequent patterns directly without candidate generation. It notes that FP-growth scales better than Apriori as the support threshold decreases since it avoids costly candidate generation and testing.
































































































