Downloaded 95 times

















This document discusses techniques for evaluating machine learning models that are used for tasks like fraud detection in a production environment. It proposes injecting randomness into the model's decisions to allow some predictions to be overridden, in order to collect data on what would have happened in the absence of the model. This counterfactual data can then be used to train new models, evaluate different decision thresholds, and estimate metrics like precision and recall without needing to do offline experiments that could impact users. Weights are applied during training and evaluation based on the probability of override to approximate the true underlying data distribution.
Introduction to counterfactual evaluation in machine learning by Michael Manapat from Stripe.
Overview of Stripe APIs for commerce and payments including a sample code snippet for creating a charge.
Stripe's machine learning team composition as of July 2015, focusing on fraud detection and continuous business scoring.
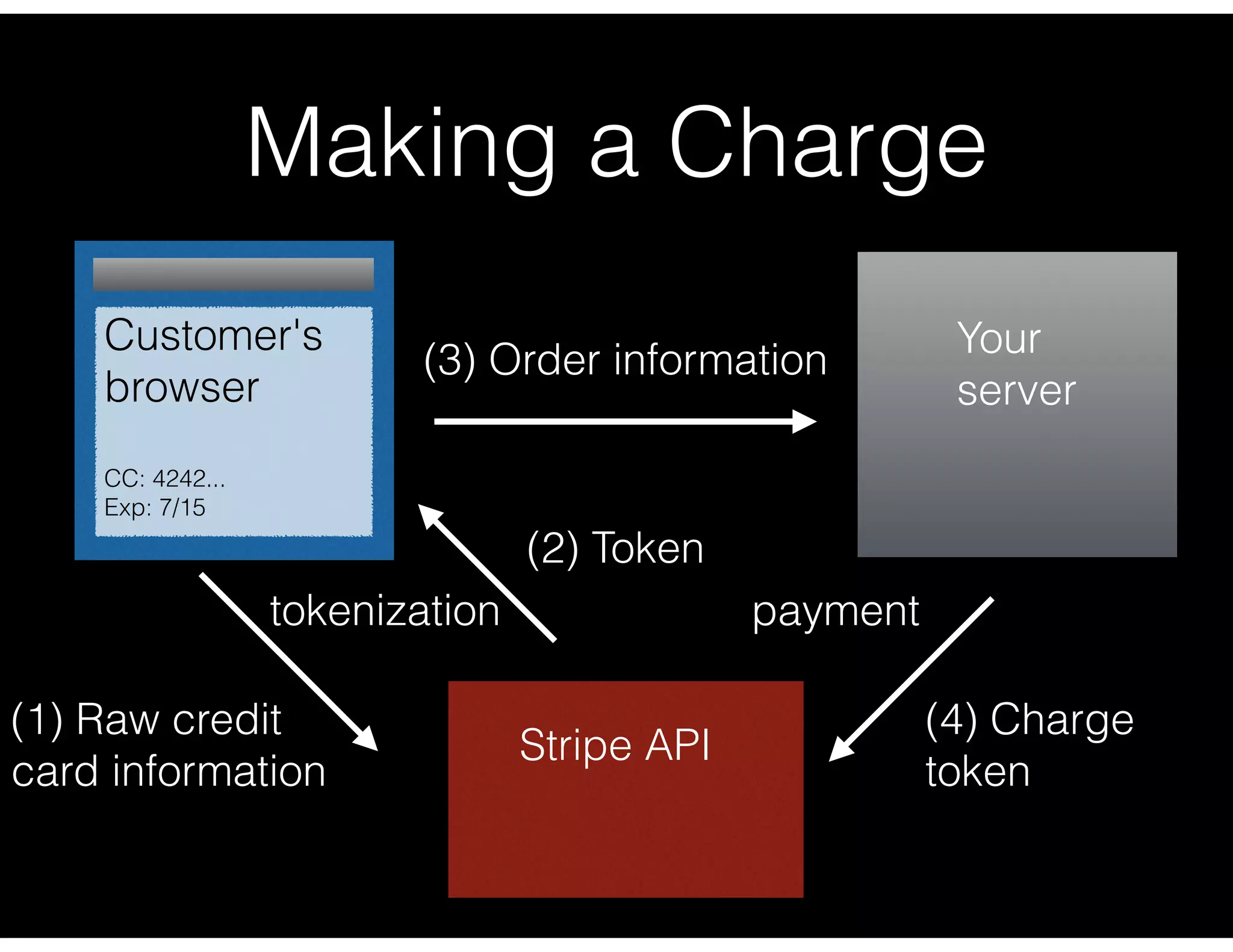
Description of the process for making a charge through a customer’s browser and Stripe’s API.
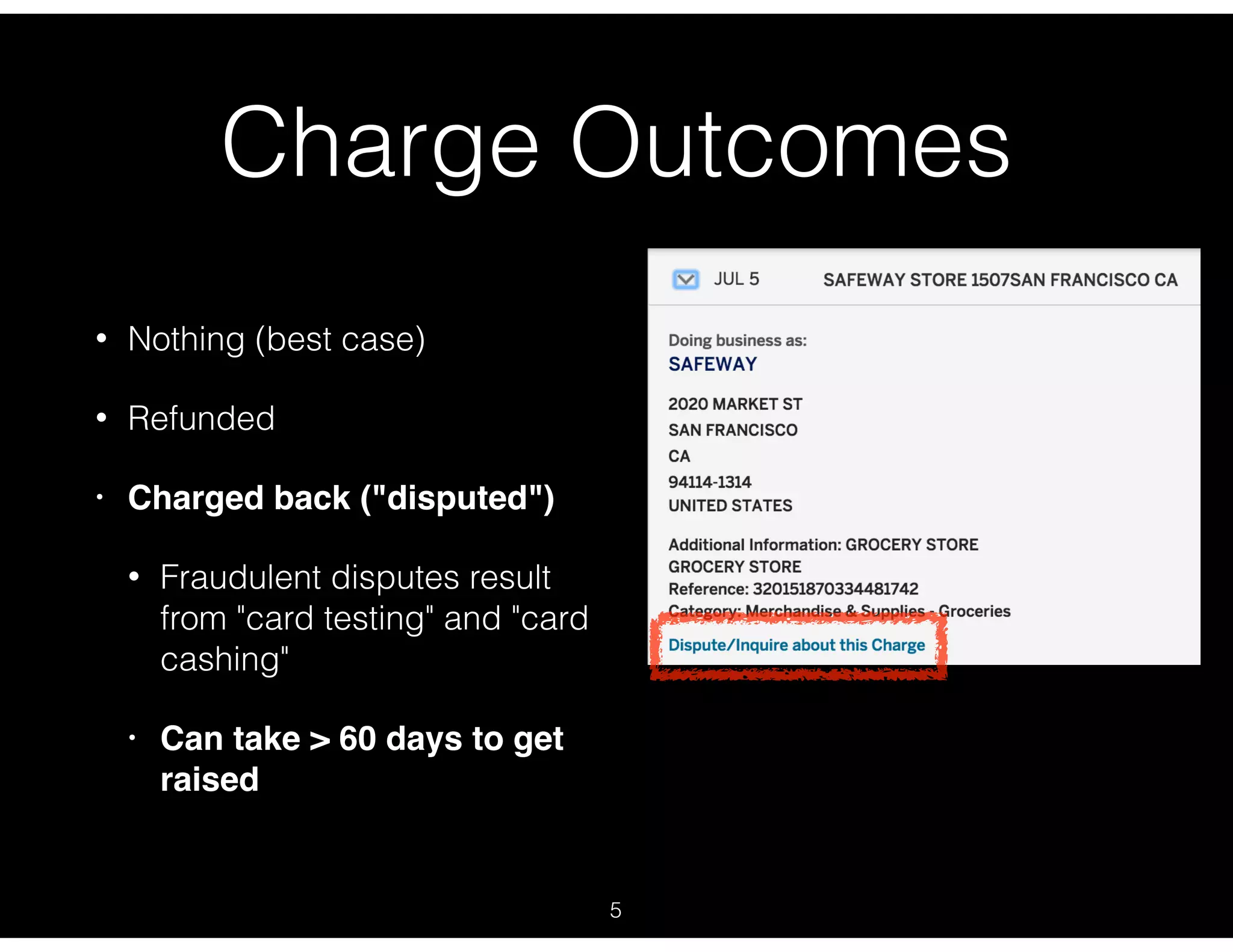
Discussion of charge outcomes including refund, chargeback, and fraudulent dispute contexts.
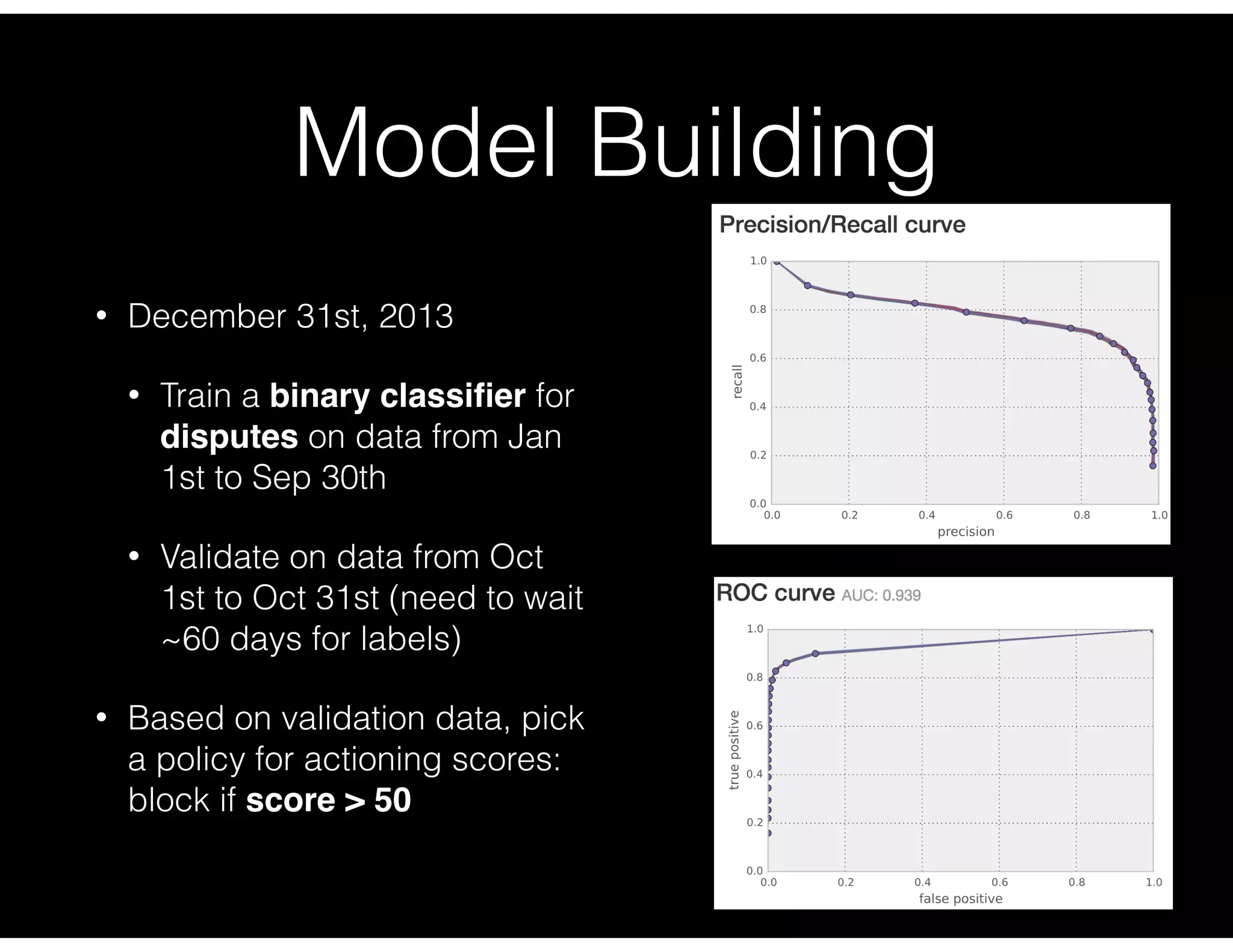
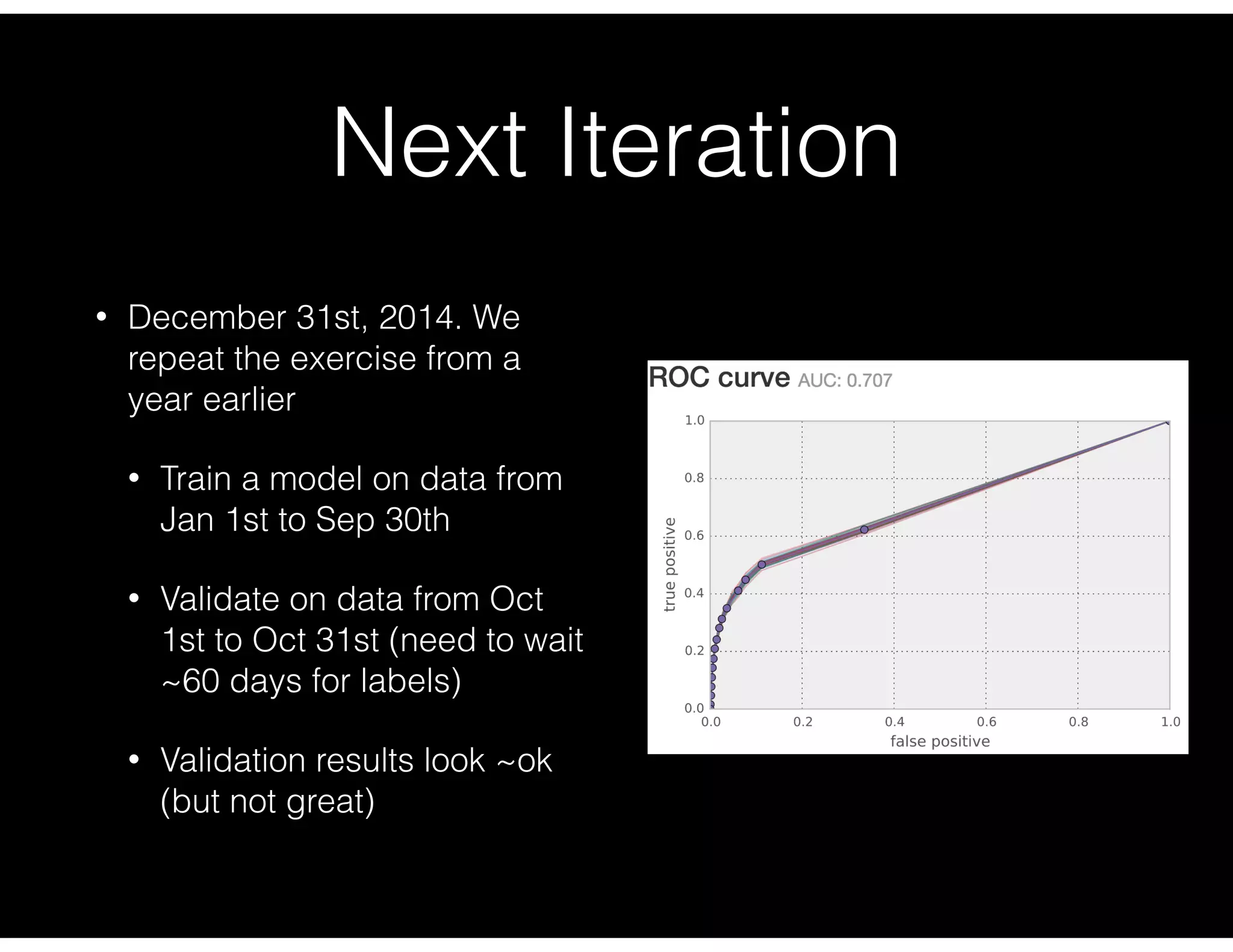
Details about model training and validation using dispute data, emphasizing action policies based on scores.
Key questions regarding model performance, precision, recall, and potential impact of policy changes.
Repeated model training and validation with emphasis on challenges faced during production deployment and evolutionary improvements.
The need for consistent data distribution for model evaluation, including approximating distribution without intervention.
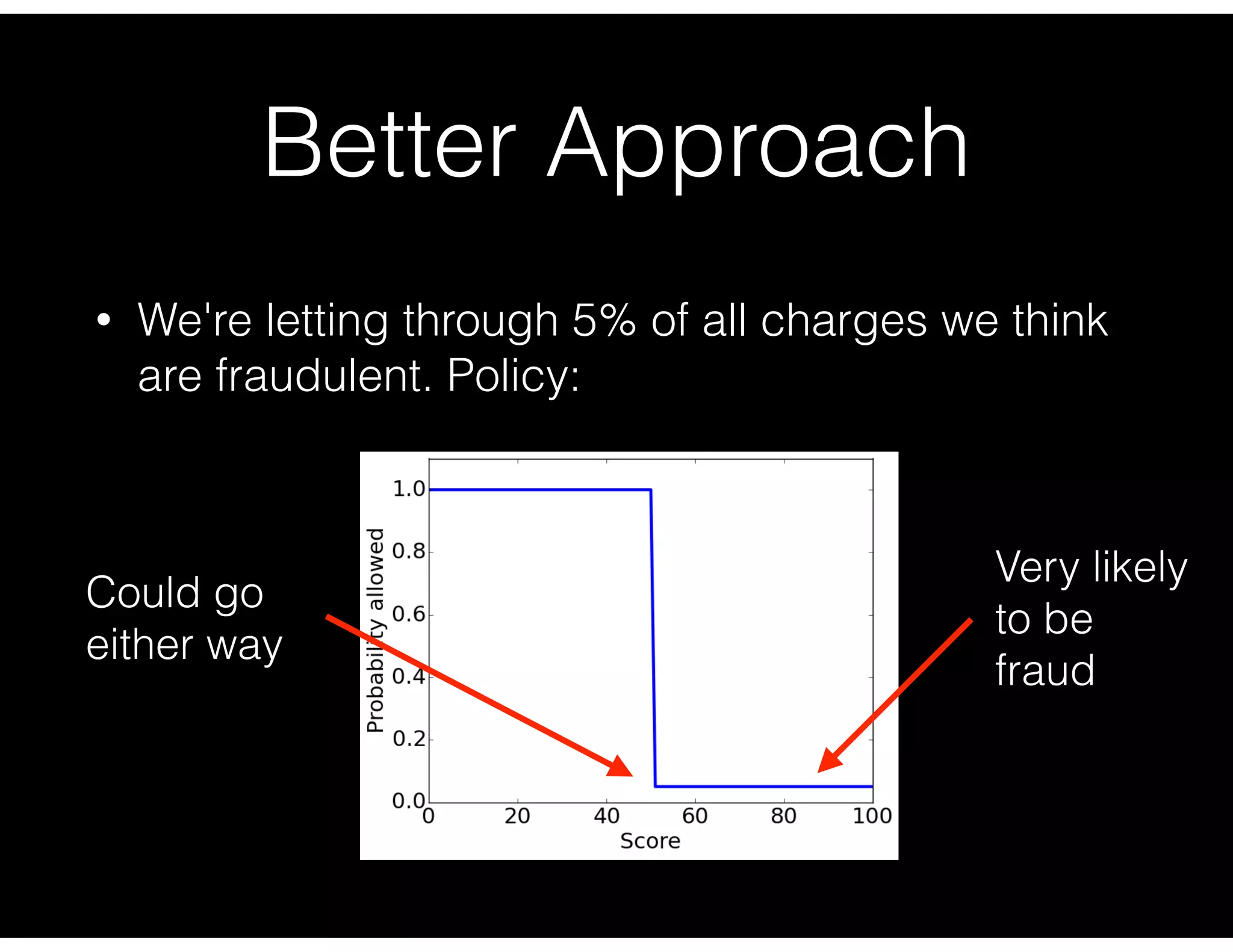
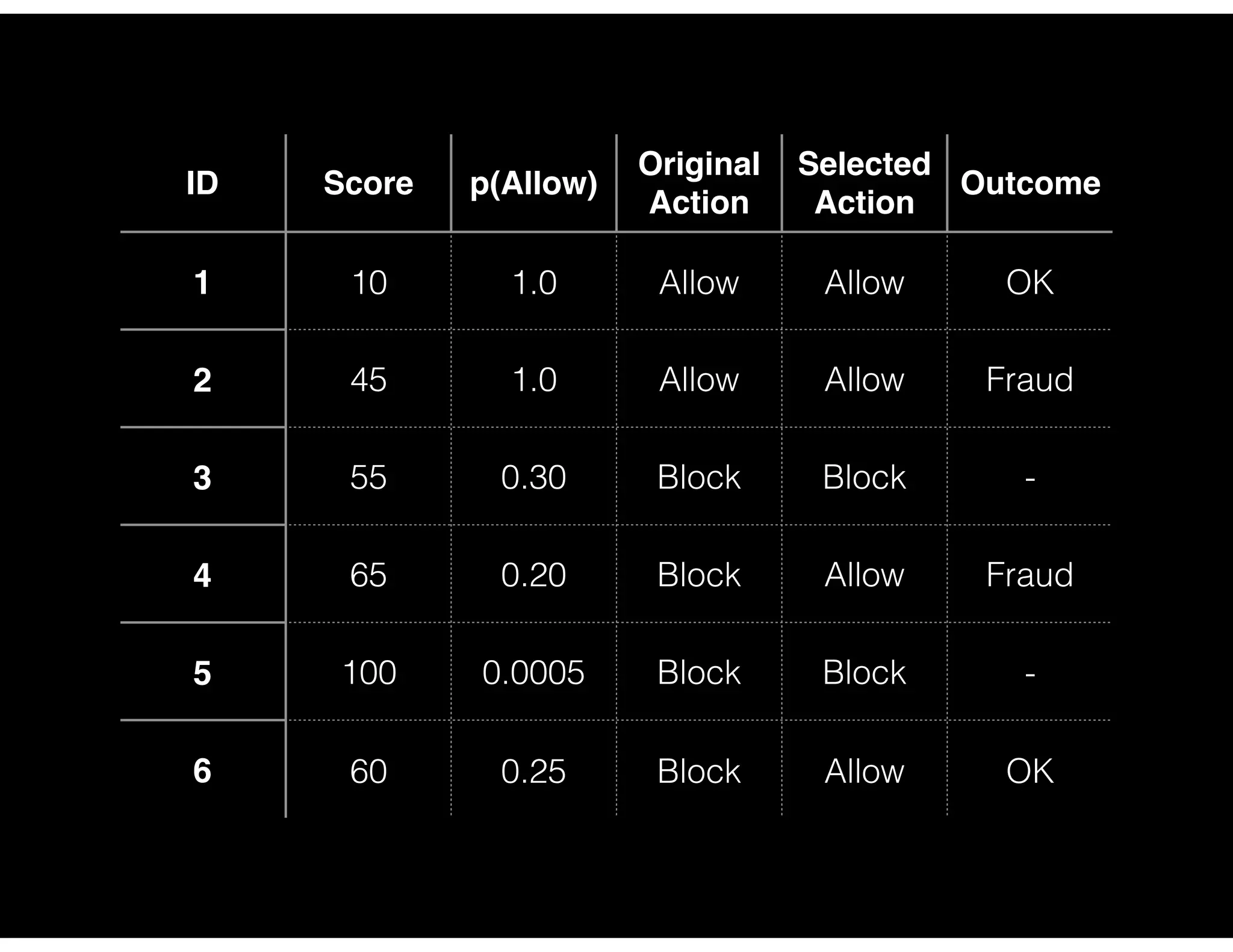
First attempt in letting charges go through randomly and the implications for measuring precision.
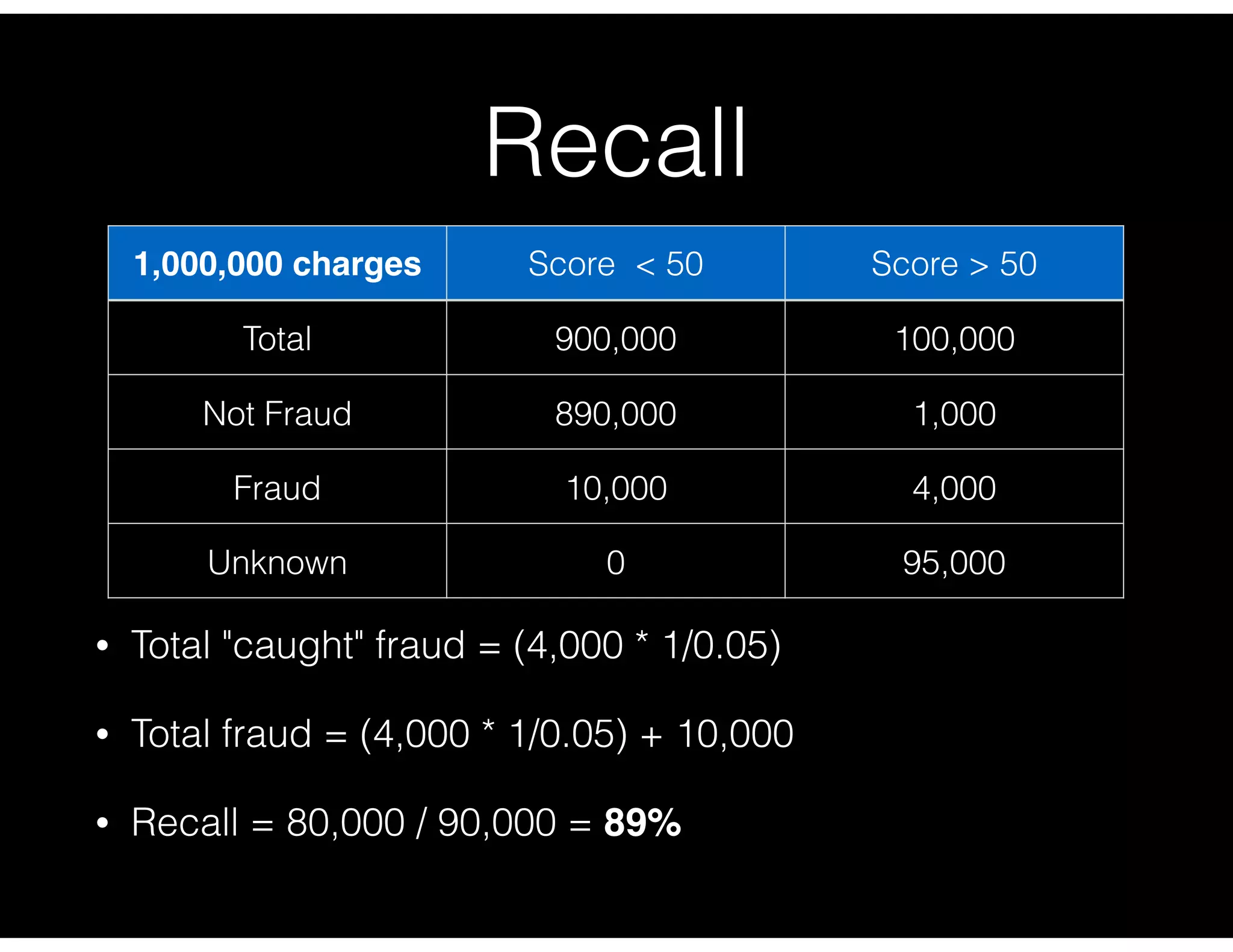
Detailed computation of recall based on fraudulent charges and total fraud, illustrating effectiveness.
Training models using weights for previously blocked charges, discussing implications on validation results.
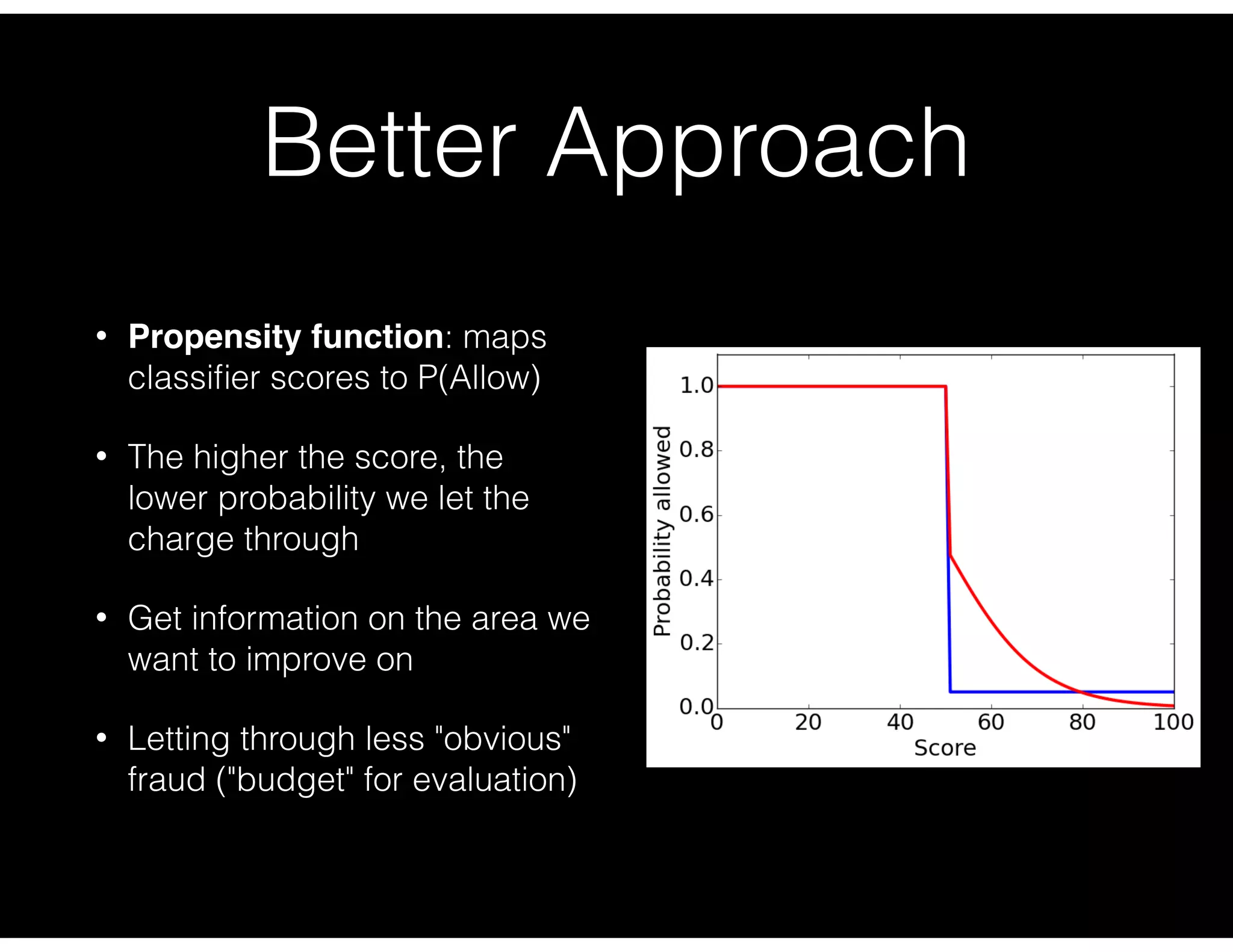
Revised approach using propensity functions to allow charged scores, aimed at improving evaluation.
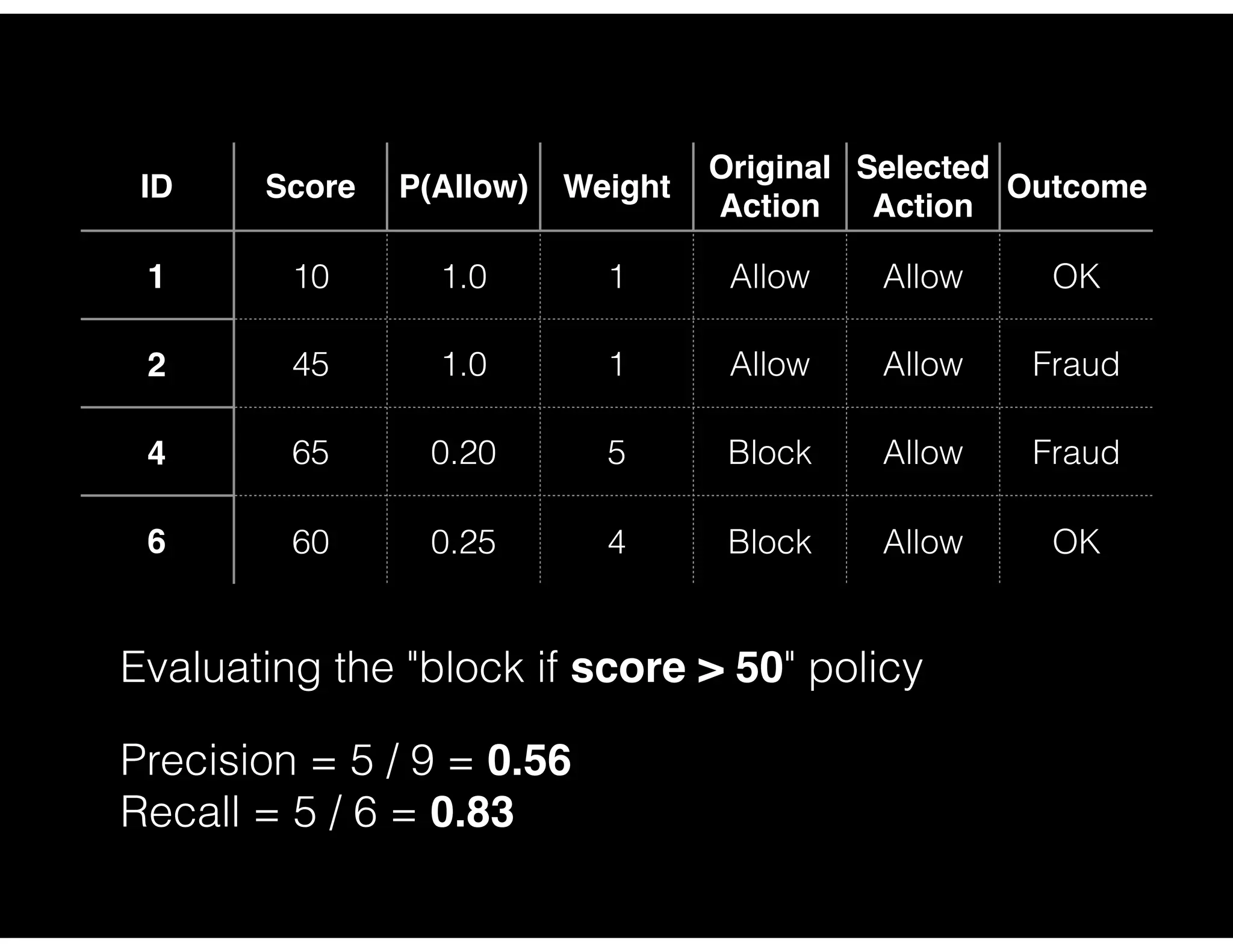
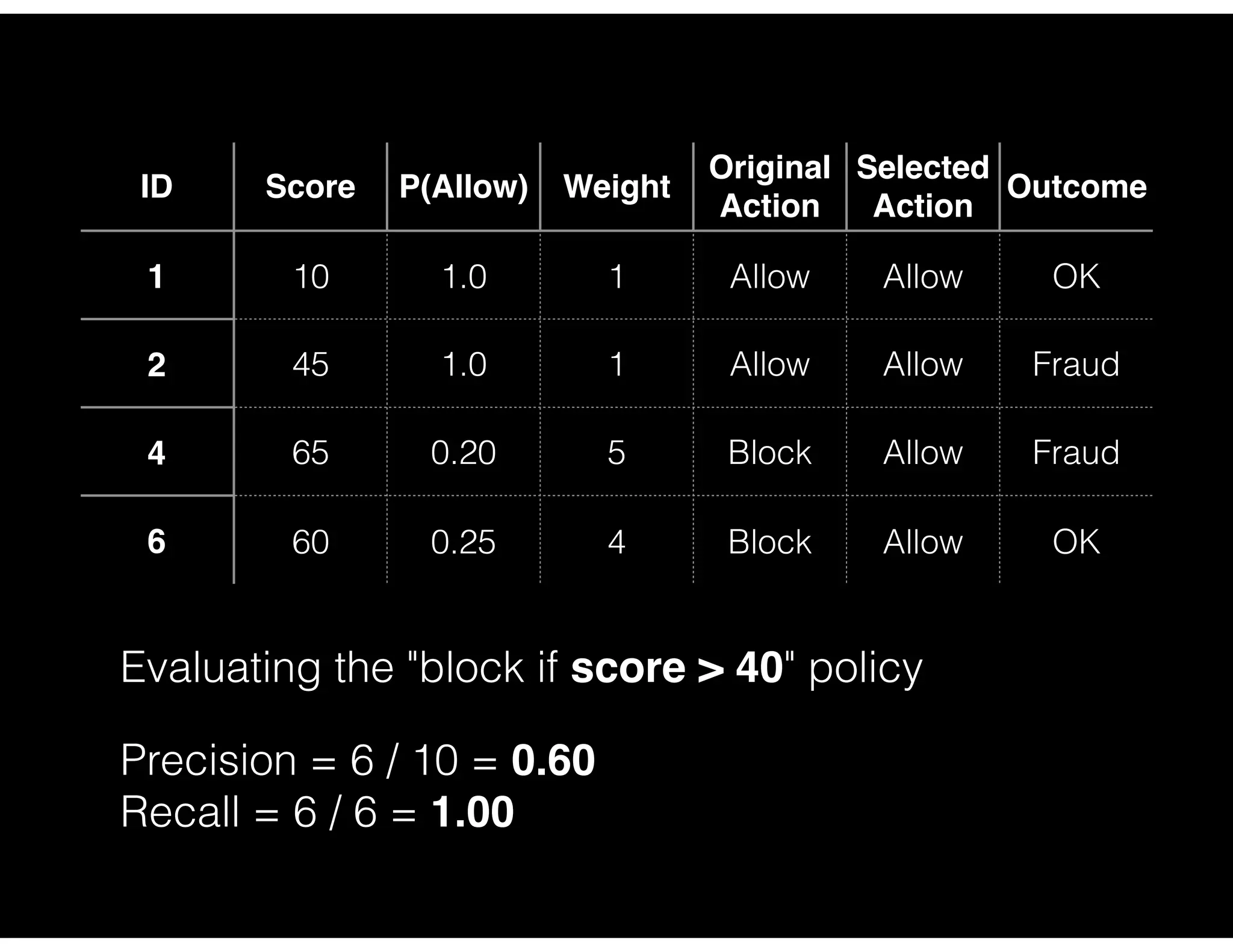
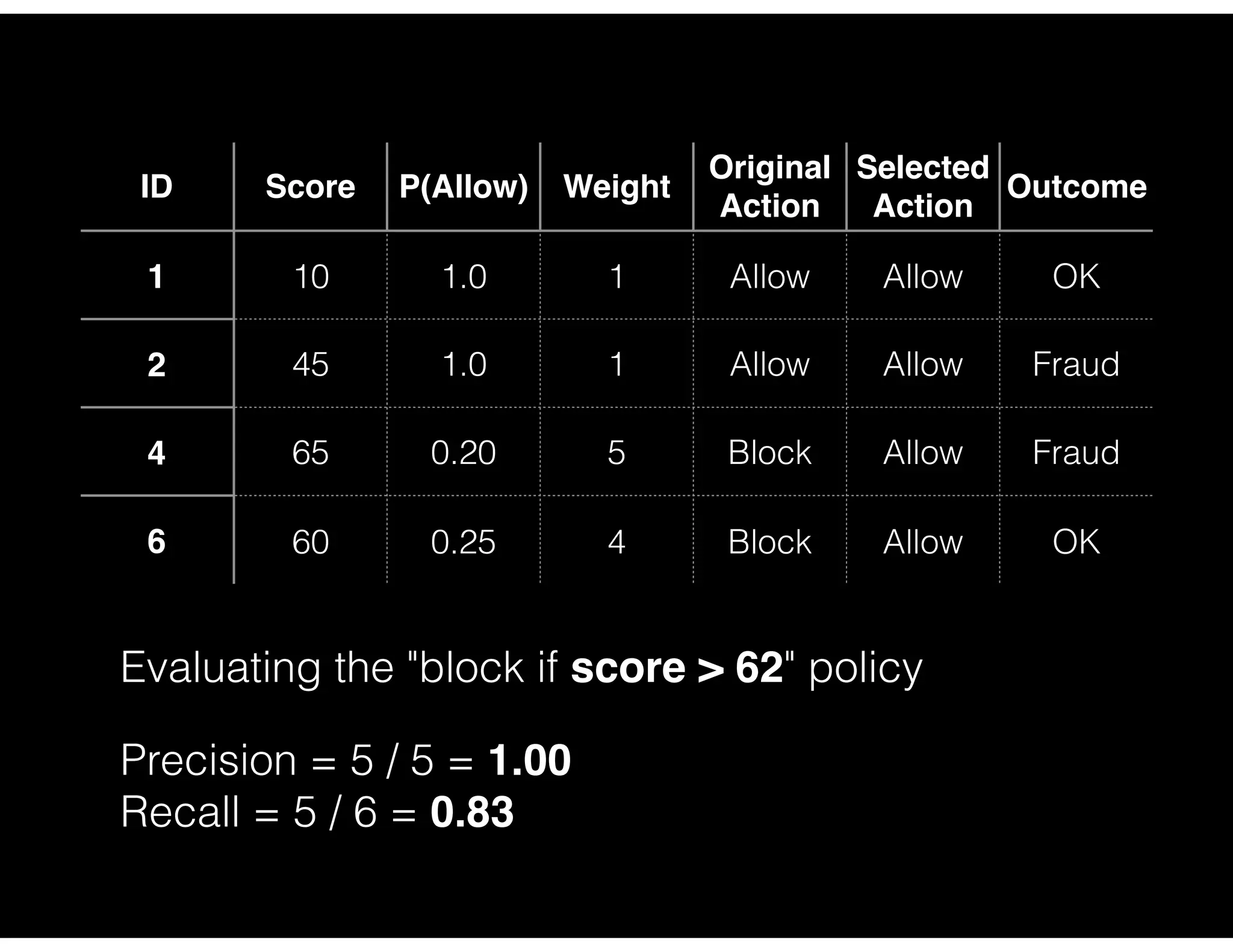
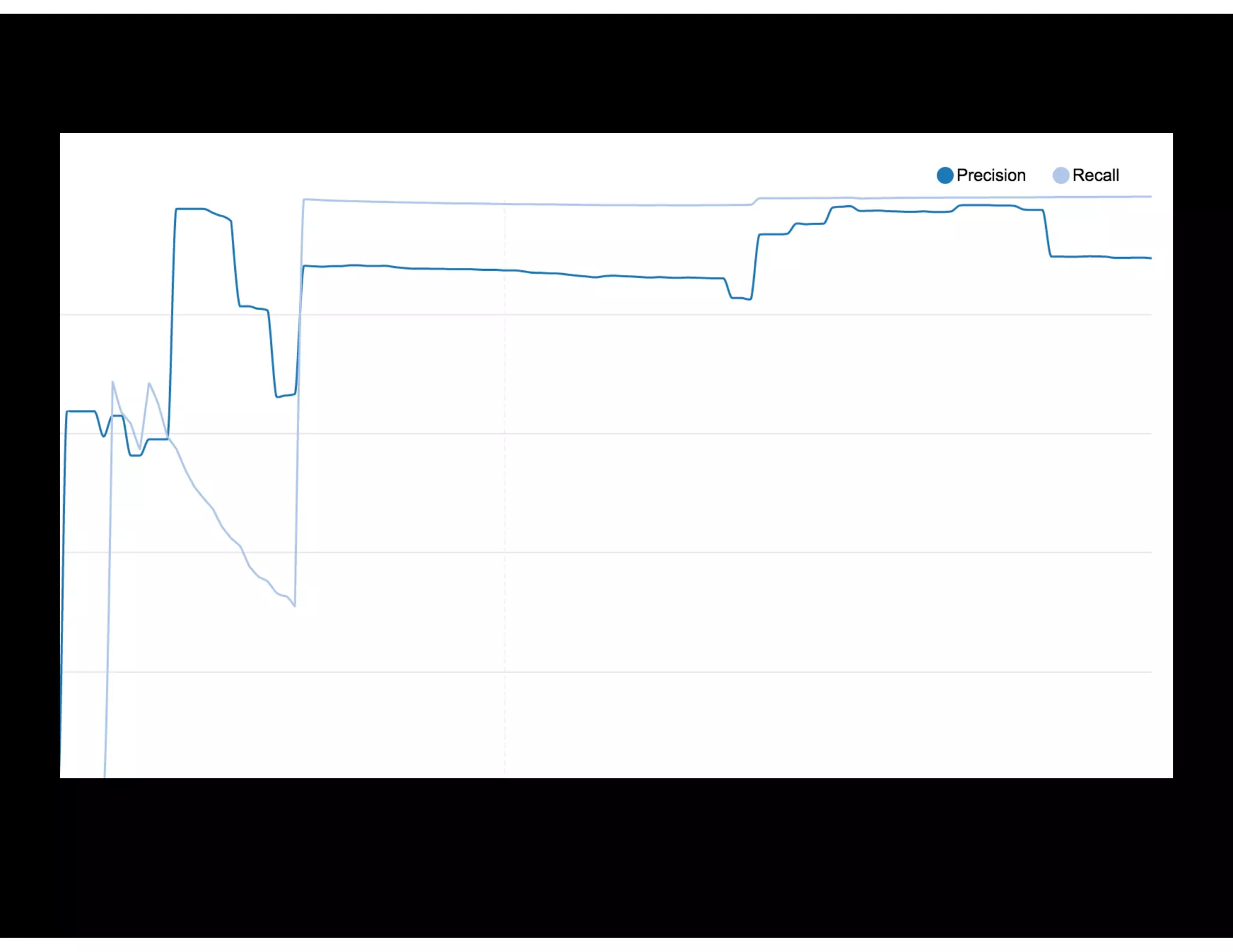
Analysis of actions taken based on model predictions including precision and recall metrics for various policies.
Precision and recall analysis for different blocking policy thresholds with detailed case study outcomes.
Insights on exploration vs. exploitation in model evaluation, variance reduction, and using bootstrap for error assessment.
Strategies for training models on weighted data, implications for flexible evaluations and counterfactual estimations.
Overview of technical aspects, independence, and application-specific issues relevant to counterfactual evaluations.
Concluding thoughts on injecting randomness into production to enhance counterfactual understanding of policies.
Acknowledgment of teams involved in the work and communication of job opportunities at Stripe.

































![PYTHON PROJECT[1] Online Fraud Fraud Detection Cybersecurity Anomaly Detec...](https://cdn.slidesharecdn.com/ss_thumbnails/pythonproject1-250421141954-bd5cebfc-thumbnail.jpg?width=640&height=640&fit=bounds)














![[DSC Europe 25] Debmalya Biswas - Agentification: the art of transforming man...](https://cdn.slidesharecdn.com/ss_thumbnails/r5azlggvtqiaiiusrqdr-4-251212103249-5a12c89b-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Dusan Nesic - Securing Tomorrow’s Infrastructure: Why Cyber-P...](https://cdn.slidesharecdn.com/ss_thumbnails/qikbszfftyowjm2q6duw-1-251211083848-8f2ead6b-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Andy Cotgreave - Nothing is new in analytics.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/mba4vzcurvoh5lfrd5zw-6-251205194645-341bbbbe-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Dobrica Cosic - Savings by the Second: How Dynamic Pricing an...](https://cdn.slidesharecdn.com/ss_thumbnails/znp09f3smtqz3w2sq6wn-1-dobrica-cosic-savings-by-the-second-how-dynamic-pricing-and-smart-data-are-bu-251208151905-26e6f41e-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Marija Vlajkovic & Andrea Radonjanin - Integration of AI tool...](https://cdn.slidesharecdn.com/ss_thumbnails/qf1jrglttoc3bm8s3aop-final-integration-of-ai-tools-251208151905-394f3a6a-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Dragana Ilic - AI for Big Data in Astronomy.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/8palya86qaatvjhva1ms-2-dragana-ilic-ai-ilic-251208151906-652b819c-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Nikola Rajovic - Hardware Technologies Under the Hood: RISC-V...](https://cdn.slidesharecdn.com/ss_thumbnails/o2gptrmtoyqndgoshwgq-dsc2025-tenstorrent-rajovic-251205090438-814685f5-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Goran Obradovic - The Rise of Sovereign AI: Building the Regi...](https://cdn.slidesharecdn.com/ss_thumbnails/7nw2xxixrxqdxvrb5wca-6-251205085714-ab09a2ac-thumbnail.jpg?width=640&height=640&fit=bounds)