

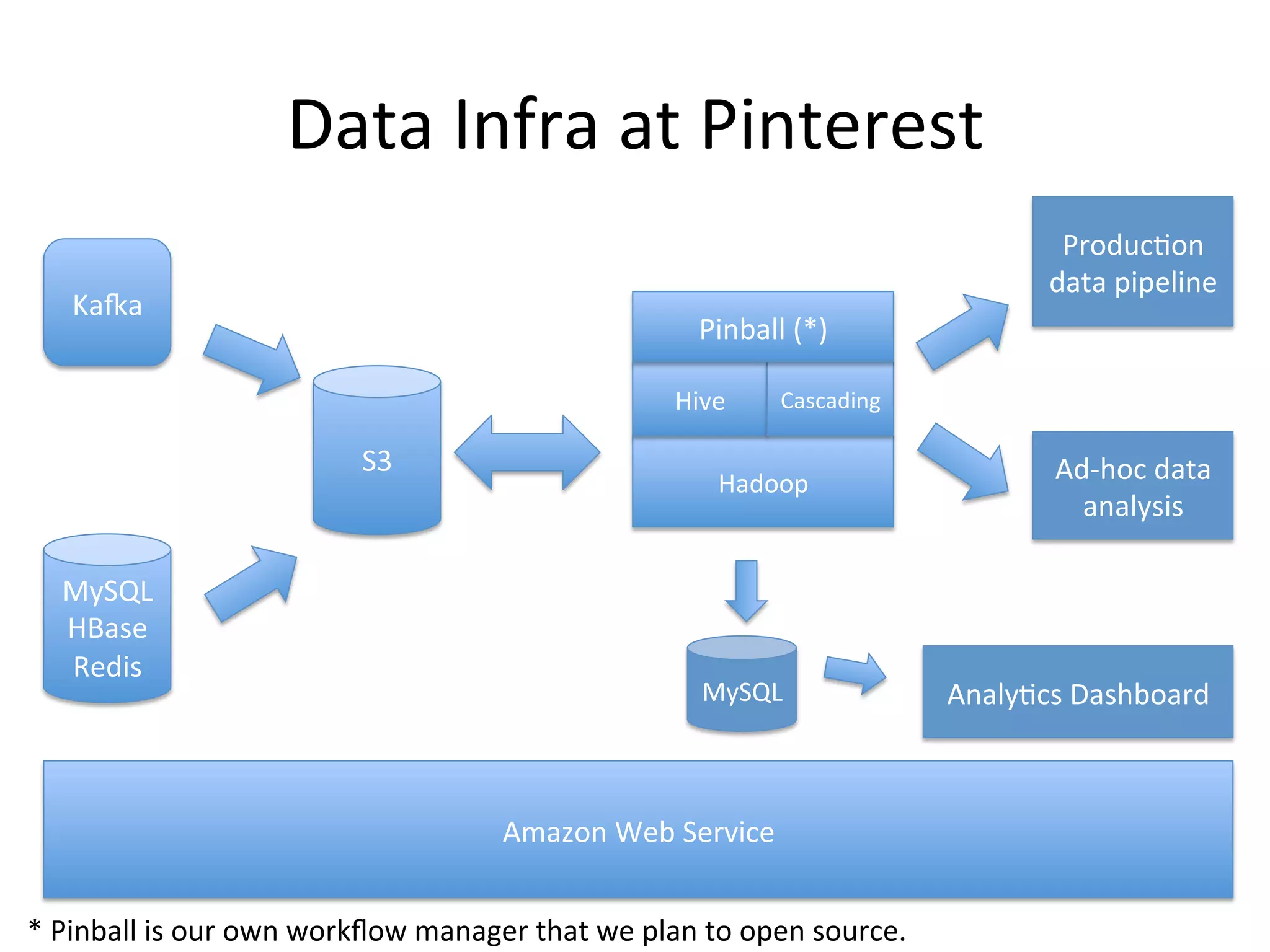
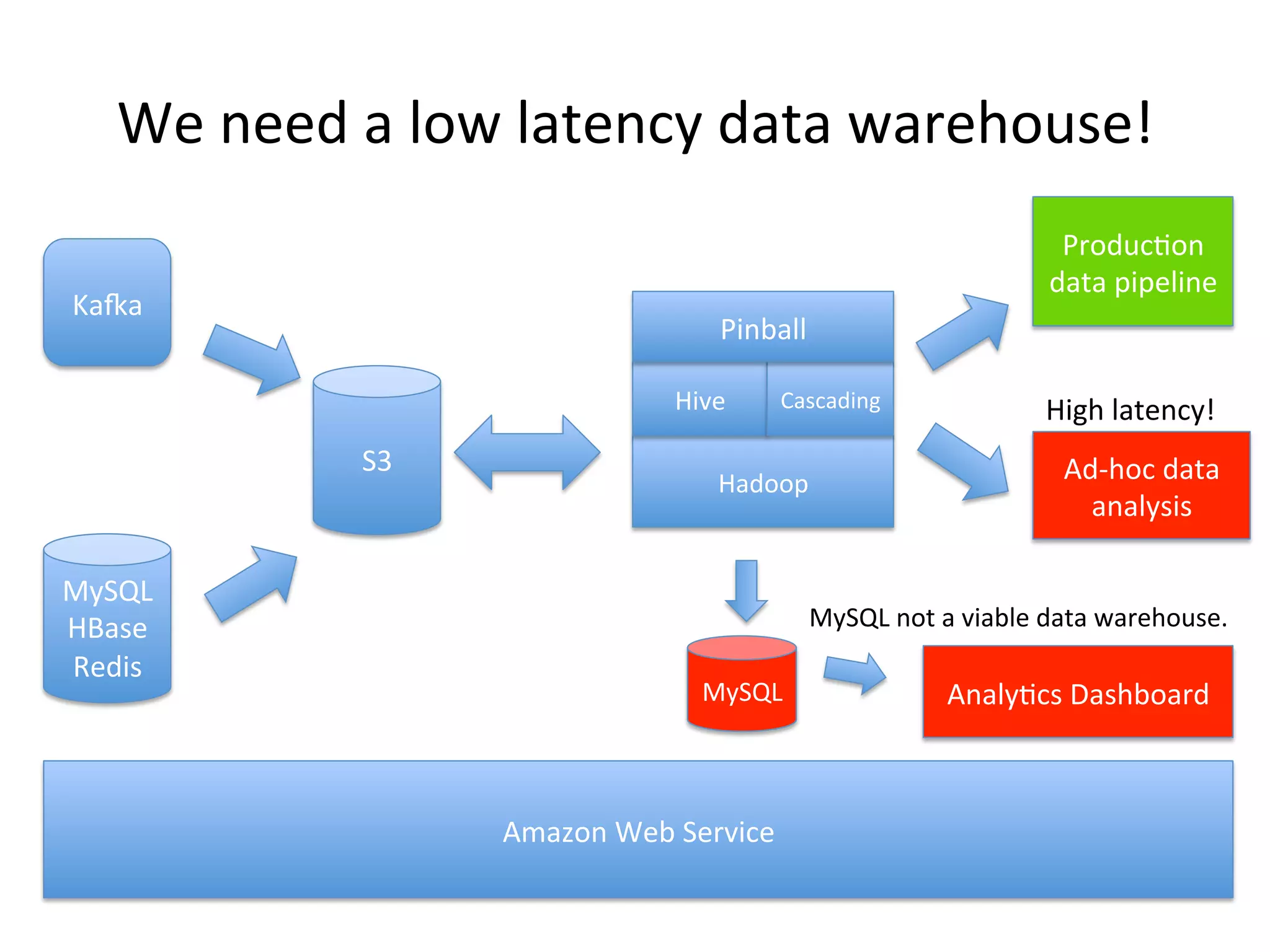



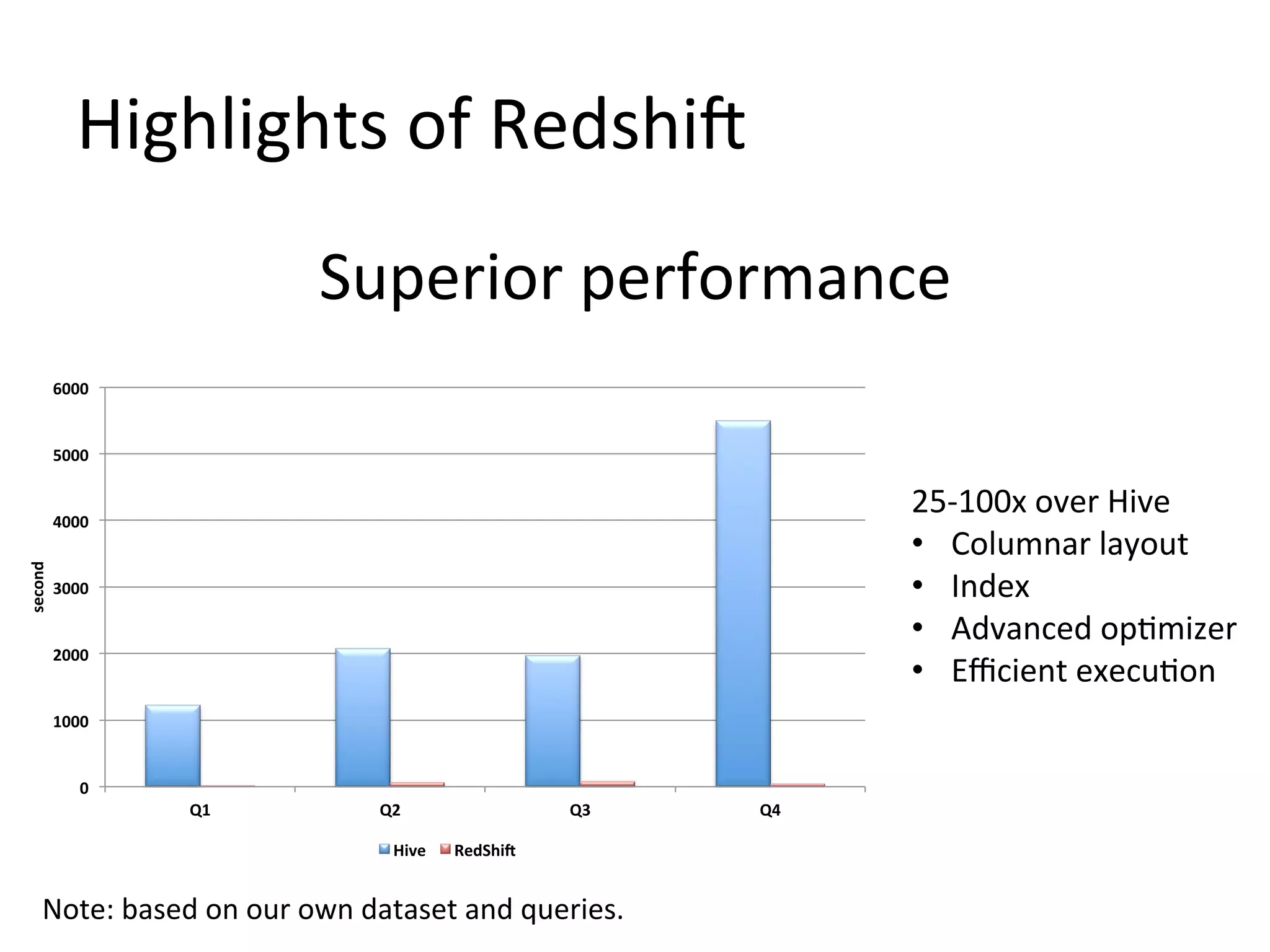

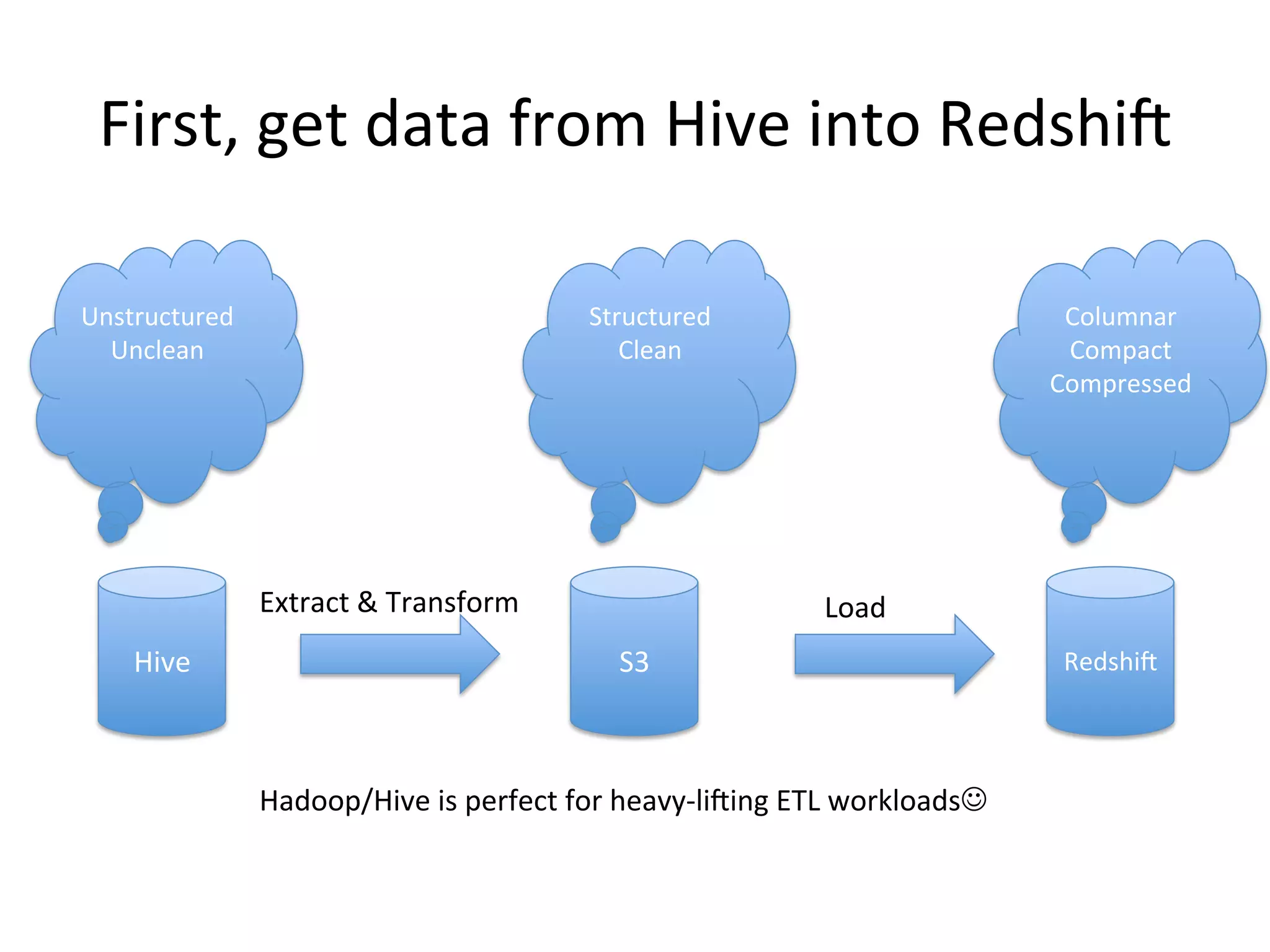
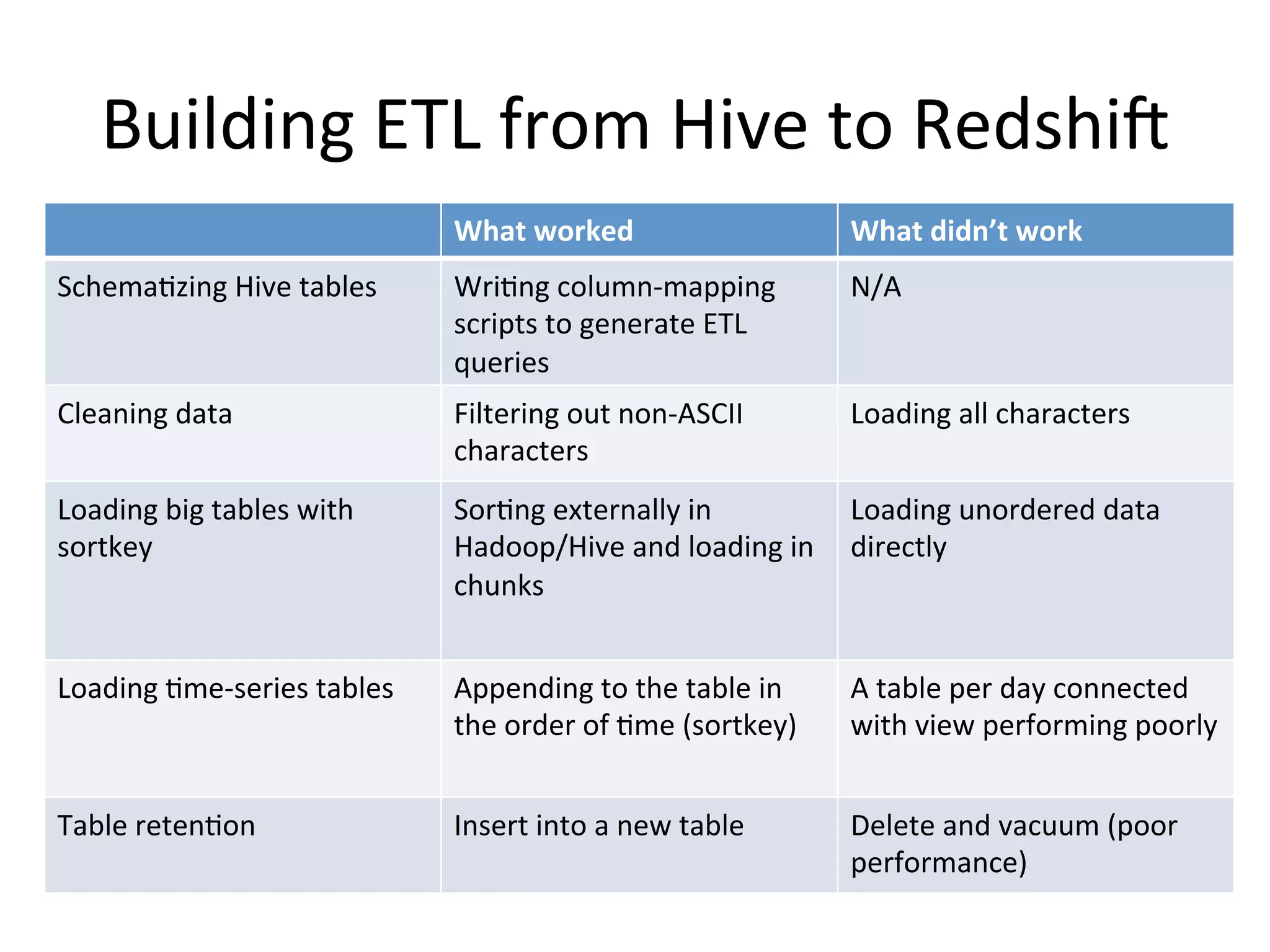

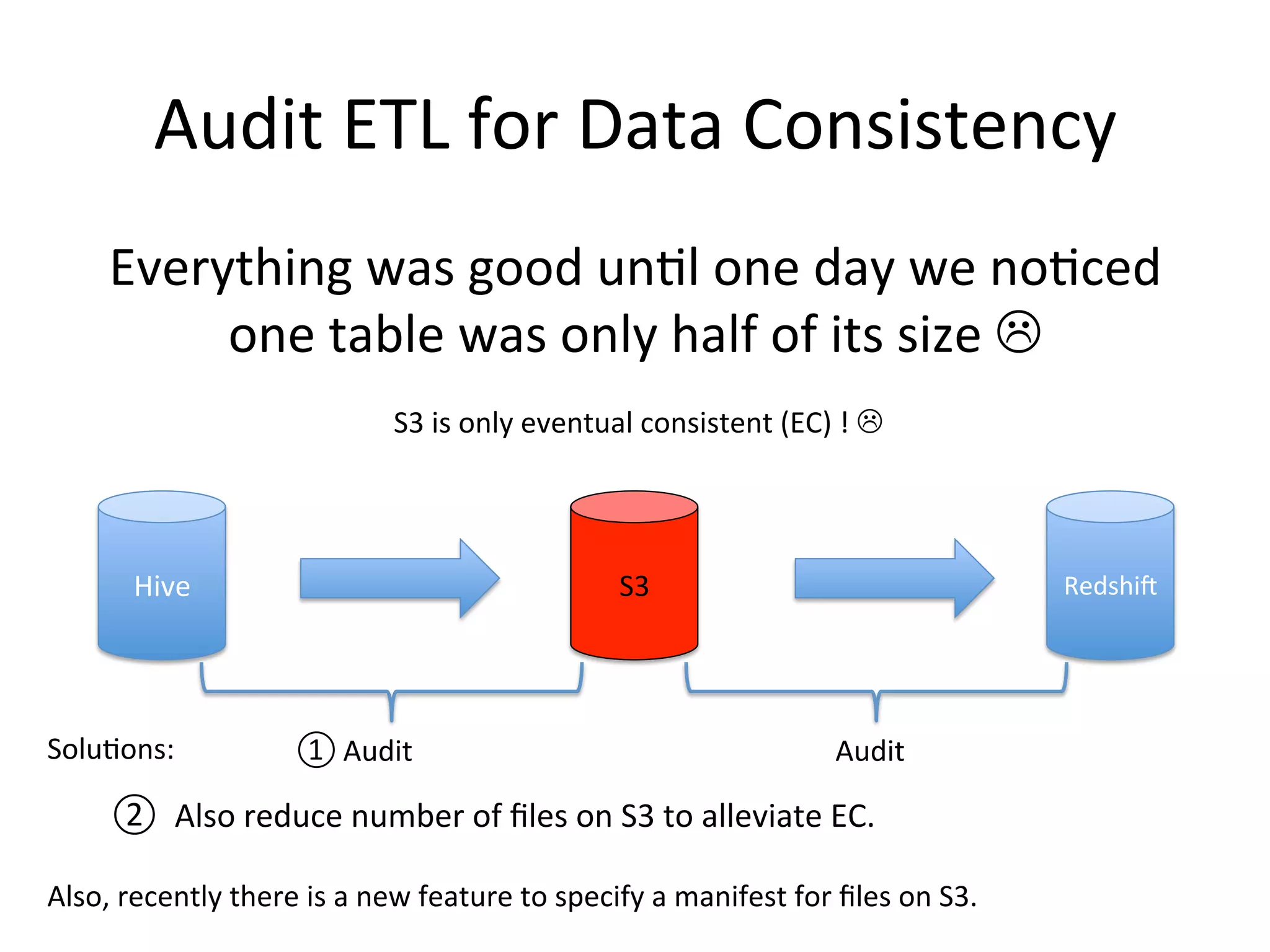

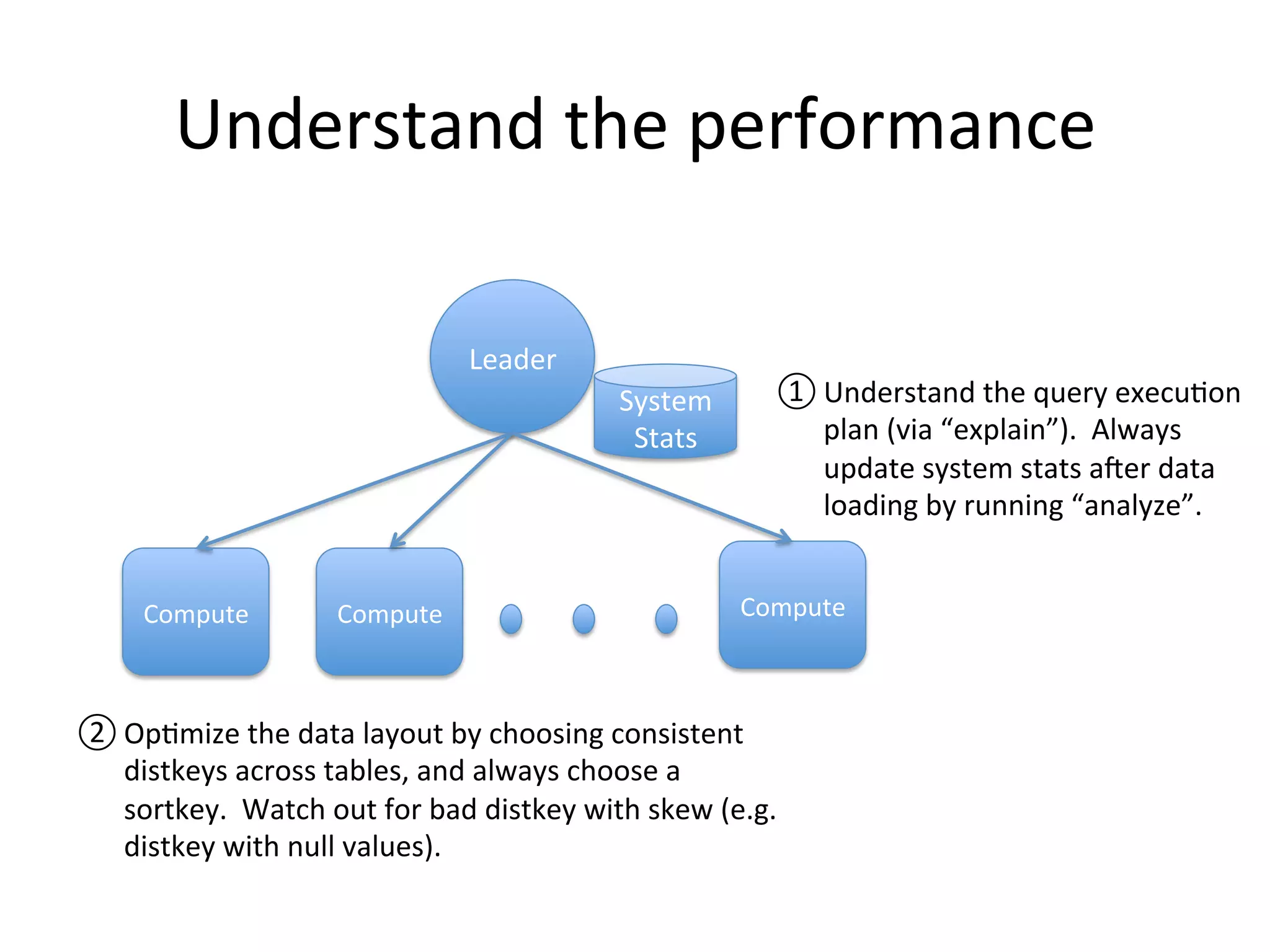

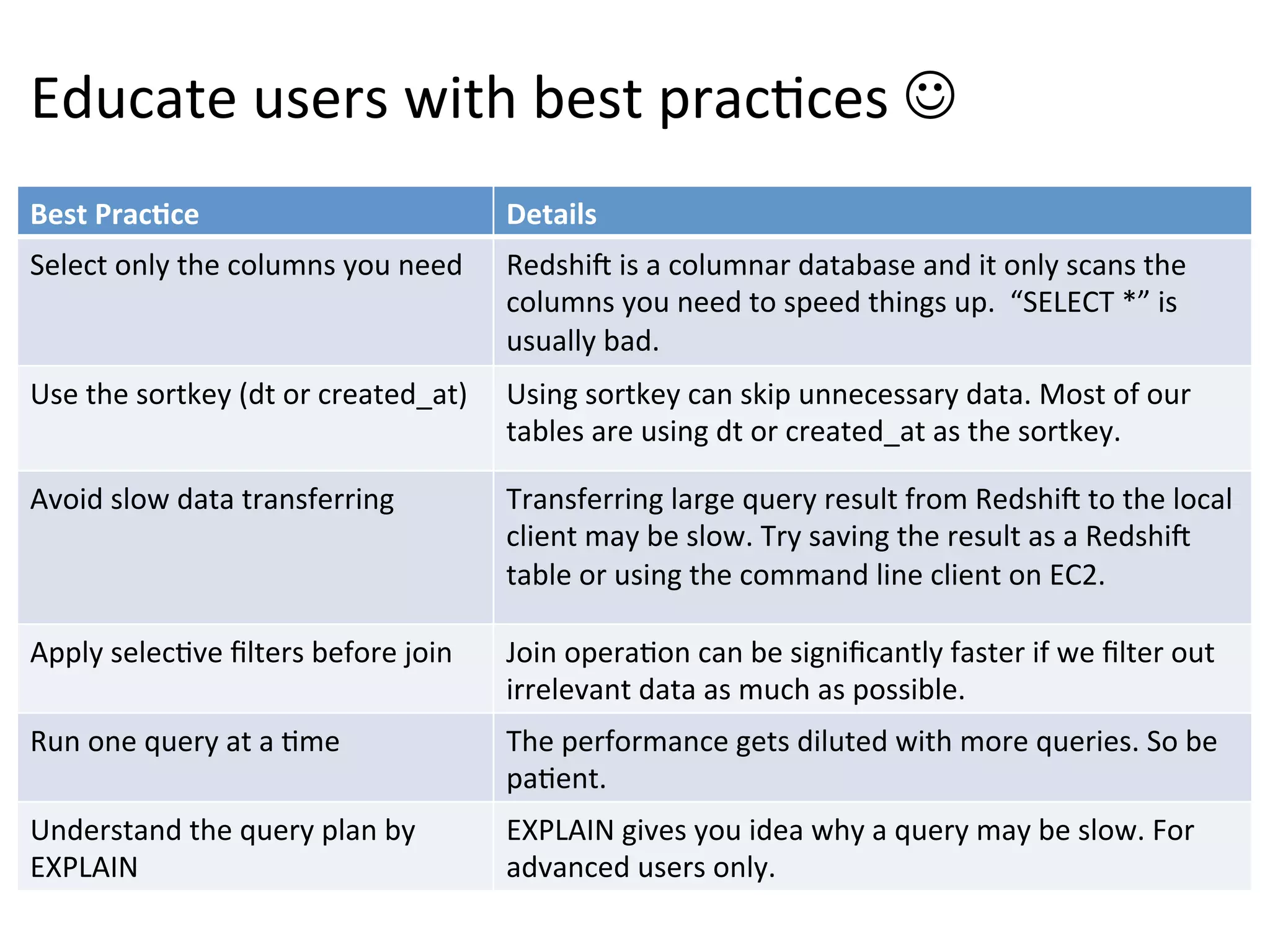

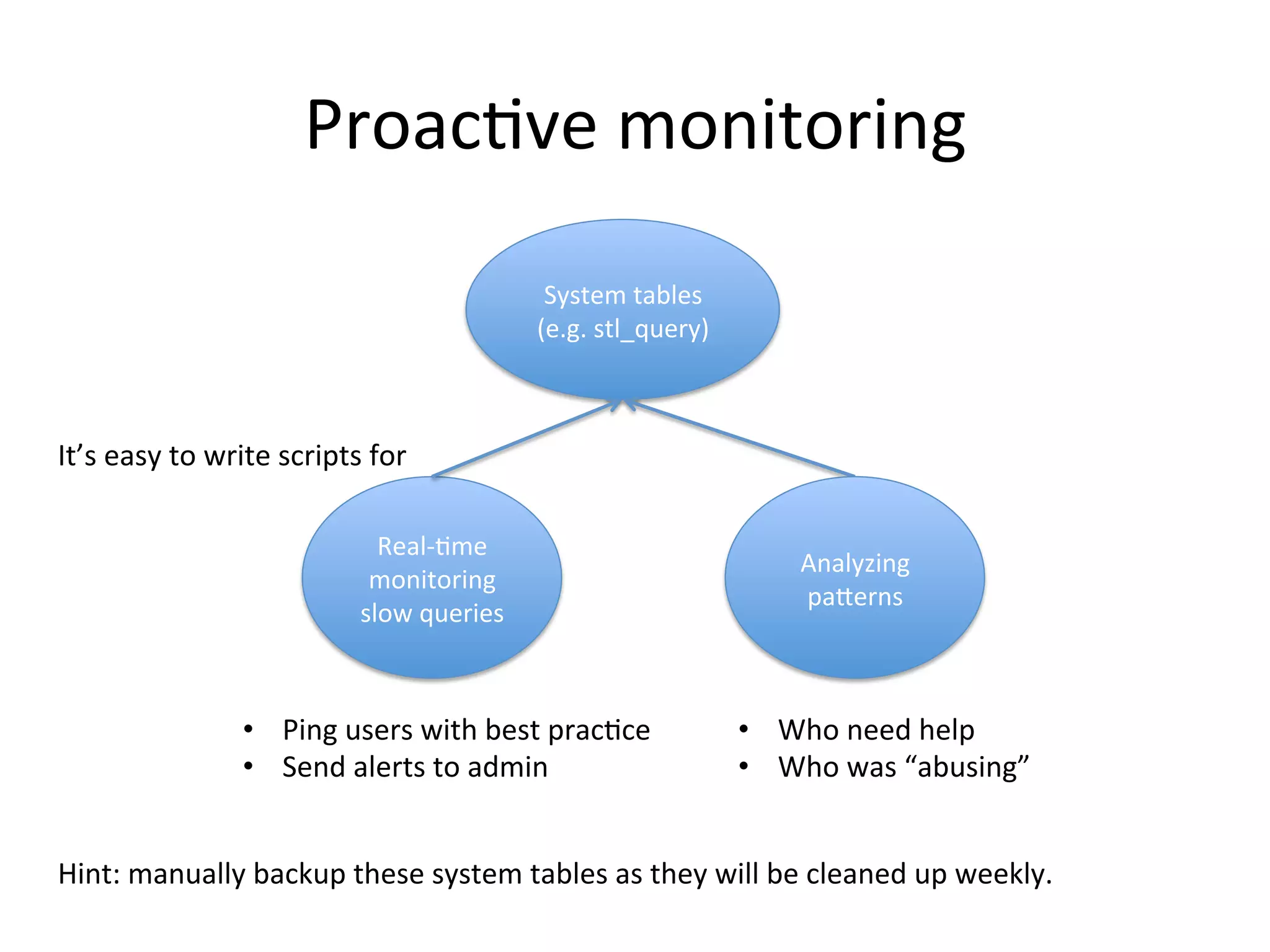


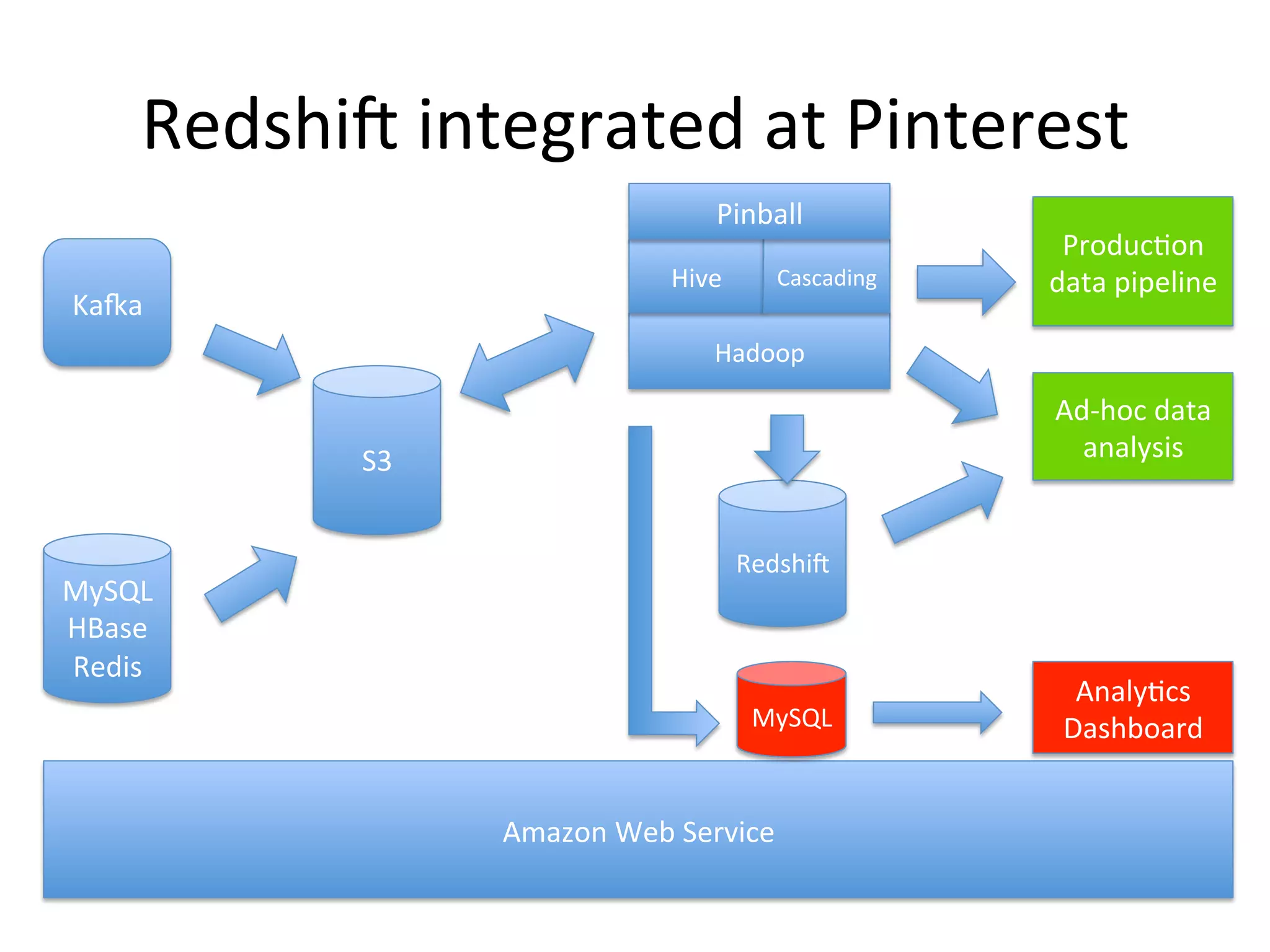
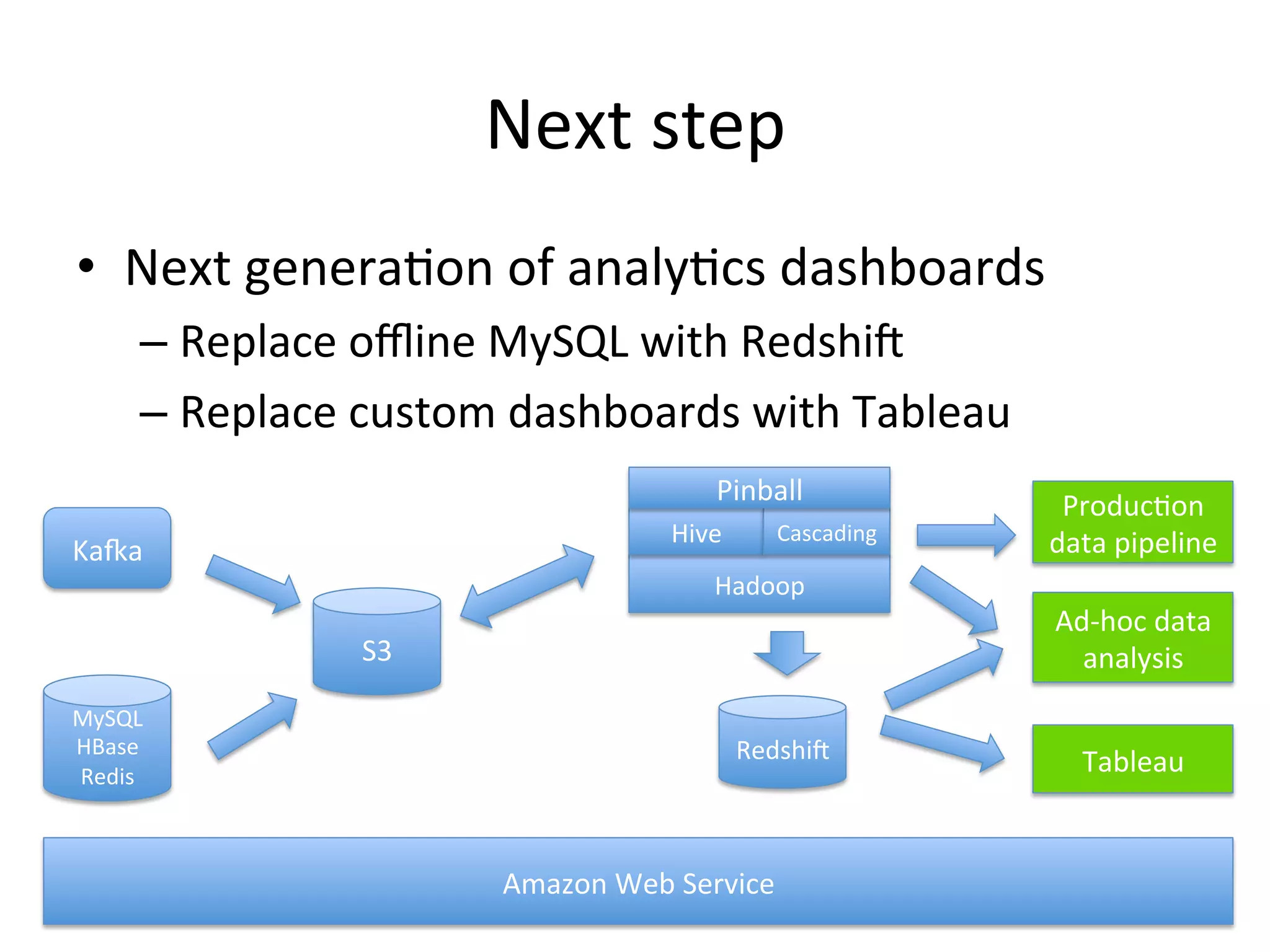



The document discusses how Pinterest leverages Amazon Redshift for interactive data analysis, outlining its advantages in terms of cost, maintenance, and performance compared to other data warehousing solutions like MySQL and Hadoop. It details the ETL process, best practices for optimizing queries, and the current operational status of their Redshift setup, including data ingestion and usage metrics. Future plans include enhancing analytics dashboards and addressing challenges related to SLA for low latency queries and cluster availability.



























![[よくわかるAmazon Redshift]Amazon Redshift最新情報と導入事例のご紹介](https://cdn.slidesharecdn.com/ss_thumbnails/20140219redshiftupdatesv1tokyo-140224010117-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)






























